
深度学习
1. 数据操作 + 数据预处理
1.1 数据操作
tensor一维向量如果只有一个元素,等同于标量,其shape都是: torch.Size([])
import torch
x = torch.arange(12)
x.shape
x.numel()
# reshape是浅拷贝!
X = x.reshape(3, 4)
# 维度
X.ndim
torch.zeros((2, 3, 4))
torch.ones((2, 3, 4))
torch.randn(3, 4)
torch.tensor([[2, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
x = torch.tensor([1.0, 2, 4, 8])
y = torch.tensor([2, 2, 2, 2])
x + y, x - y, x * y, x / y, x ** y # **运算符是求幂运算
torch.exp(x) # 相当于是每个元素 -> e^(每个元素)
X = torch.arange(12, dtype=torch.float32).reshape((3,4))
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
# 第一个输出张量的轴-0长度(6)是两个输入张量轴-0长度的总和(3 + 3);
# 第二个输出张量的轴-1长度(8)是两个输入张量轴-1长度的总和(4 + 4)。
torch.cat((X, Y), dim=0), torch.cat((X, Y), dim=1)
# 对应位置是否相等,输出同样大小bool矩阵
X == Y
X.sum()广播机制:
1.本来:相加应该形状一样(都是3 x 4)
2.广播机制:
两个张量必须不为空:
a.维度相同:对于同一维度,如果大小不相等,但是有一个为1,就会自动复制到相等
b.维度不同:维度少的张量在shape的左边补1,直到两个维度一样
a = torch.arange(6).reshape((3, 2))
b = torch.arange(2).reshape((1, 2))
a + b
a = torch.arange(40).reshape((2, 4, 5))
b = torch.arange(5).reshape((1, 5))
a + bX[-1], X[1:3]
X[1, 2] = 9 #类似于X[1][2]
X[0:2, :] = 12节省内存:
Y = X + Y 会导致 新分配一个Y,再析构掉原来的Y
解决:
Y+=X
# or
Z[:] = X + Y这里Z[:] 是在等式左侧,所以可以
如果直接比较Z和Z[:] ,会发现二者id不一样
Z[:]相当于浅拷贝,指向的是Z
NumPy:
# 将深度学习框架定义的张量[转换为NumPy张量(ndarray)]很容易,反之也同样容易。 torch张量和numpy数组将共享它们的底层内存,就地操作更改一个张量也会同时更改另一个张量。
A = X.numpy()
B = torch.tensor(A)
type(A), type(B)
# 要(将大小为1的张量转换为Python标量),我们可以调用item函数或Python的内置函数。
a = torch.tensor([3.5])
a, a.item(), float(a), int(a)1.2 数据预处理
# 写入csv文件
import os
# os.path.join是用操作系统的分隔符连接,exist_ok是存在就不创建
os.makedirs(os.path.join('..', 'data'), exist_ok=True)
data_file = os.path.join('..', 'data', 'house_tiny.csv')
with open(data_file, 'w') as f:
f.write('NumRooms,Alley,Price\n') # 列名
f.write('NA,Pave,127500\n') # 每行表示一个数据样本
f.write('2,NA,106000\n')
f.write('4,NA,178100\n')
f.write('NA,NA,140000\n')
# 读取csv文件
import pandas as pd
data = pd.read_csv(data_file)
data处理缺失值:
# 位置索引 iloc: index location
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]
# mean是求平均数(数值才生效),fillna是填充
inputs = inputs.fillna(inputs.mean())
print(inputs)
inputs = pd.get_dummies(inputs, dummy_na=True)
print(inputs)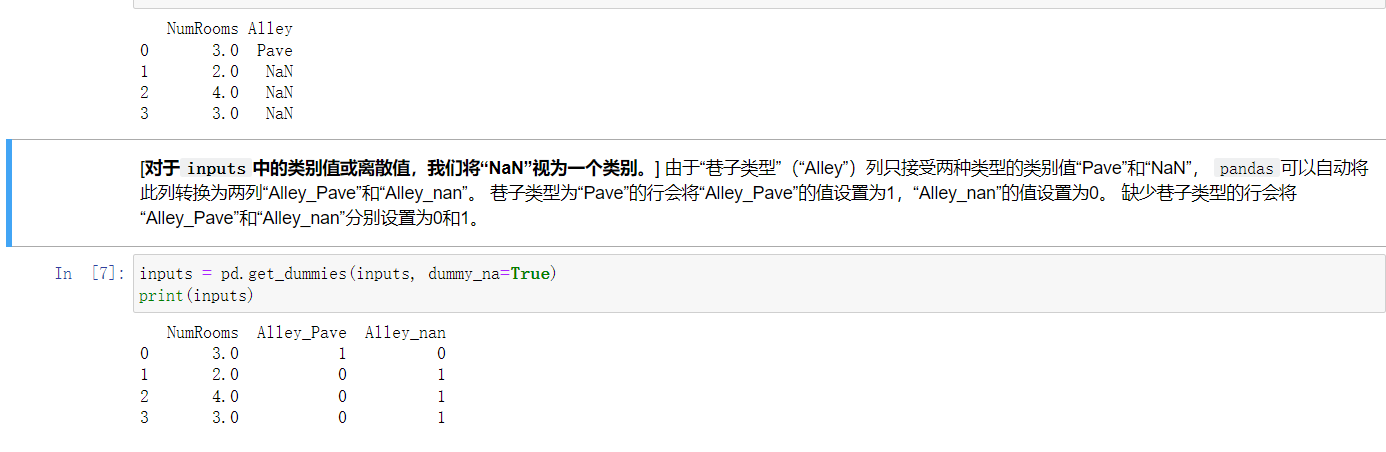
现在都变成了数值类型,就可以转换为张量了
import torch
X, y = torch.tensor(inputs.values), torch.tensor(outputs.values)
# 这里dtype=torch.float64,默认64,比32慢,一般用32
X, y2. 线性代数
2.1 线性代数
https://www.bilibili.com/video/BV1ys411472E/?p=1
2.2 实现
import torch
x = torch.arange(4)
x[3]
len(x)
A = torch.arange(20).reshape(5, 4)
# 转置
A.T
A = torch.arange(20, dtype=torch.float32).reshape(5, 4)
B = A.clone() # 通过分配新内存,将A的一个副本分配给B,深拷贝
A, A + B
# 这是对应位置相乘
A * B
a = 2
X = torch.arange(24).reshape(2, 3, 4)
# 每个值都加/乘上2,因为广播机制
a + X, (a * X).shapesum:
x = torch.arange(4, dtype=torch.float32)
# sum默认把所有元素加起来,也就是沿所有轴降低维度,最后成一个标量
x, x.sum()
A = torch.arange(20*2, dtype=torch.float32).reshape(2, 5, 4)
A.shape, A.sum()
# axis表示轴,也就是按【指定轴】降低维度,将指定维度在输出形状中消失
A_sum_axis0 = A.sum(axis=1)
A_sum_axis0, A_sum_axis0.shape
# 这是消去第0轴和第1轴
A.sum(axis=[0, 1])
# 二者等价,numel表示个数
A.mean(), A.sum() / A.numel()
# 也可以指定维度,左边的操作就是右边的步骤,二者等价
A.mean(axis=0), A.sum(axis=0) / A.shape[0]
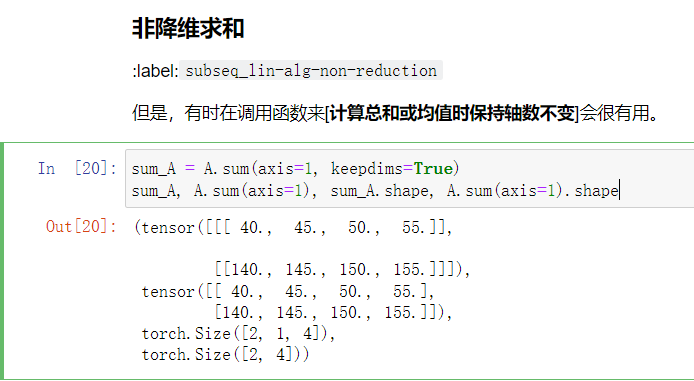
# 非降维度求和,也即只是将其变为1
sum_A = A.sum(axis=1, keepdims=True)
sum_A, A.sum(axis=1), sum_A.shape, A.sum(axis=1).shape
# 然后就能通过广播,做除法
A / sum_A
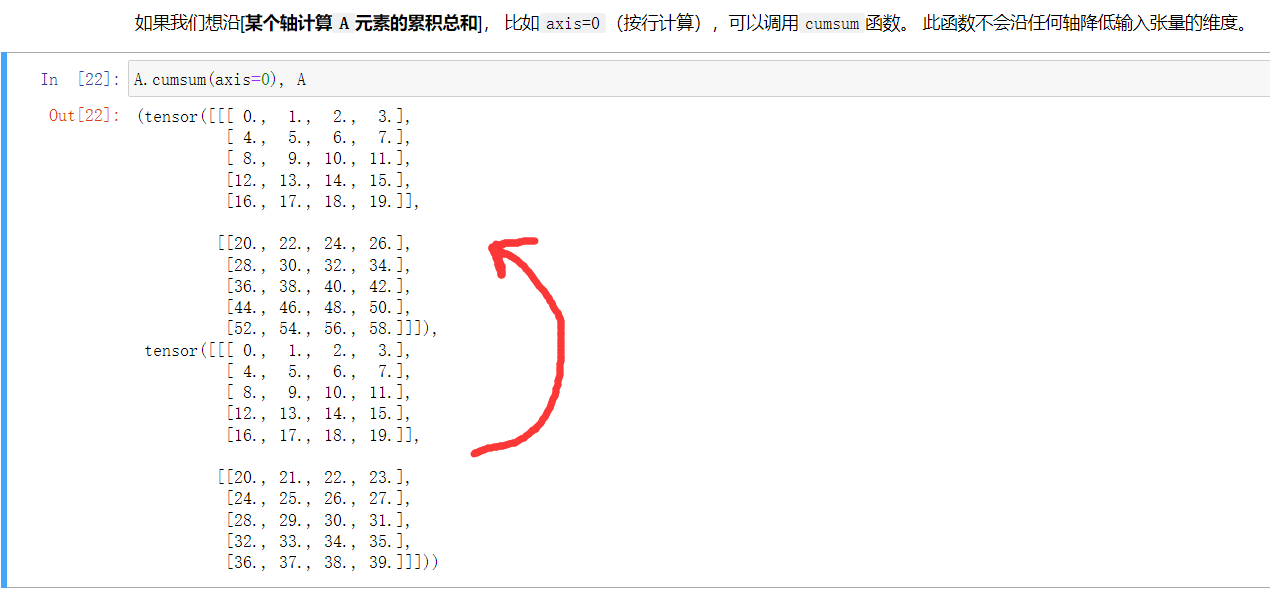
# 沿着某个轴,进行累加,第0个+=0,第1个+=第0个,第三个+=前两个...s,也即前缀和
A.cumsum(axis=0)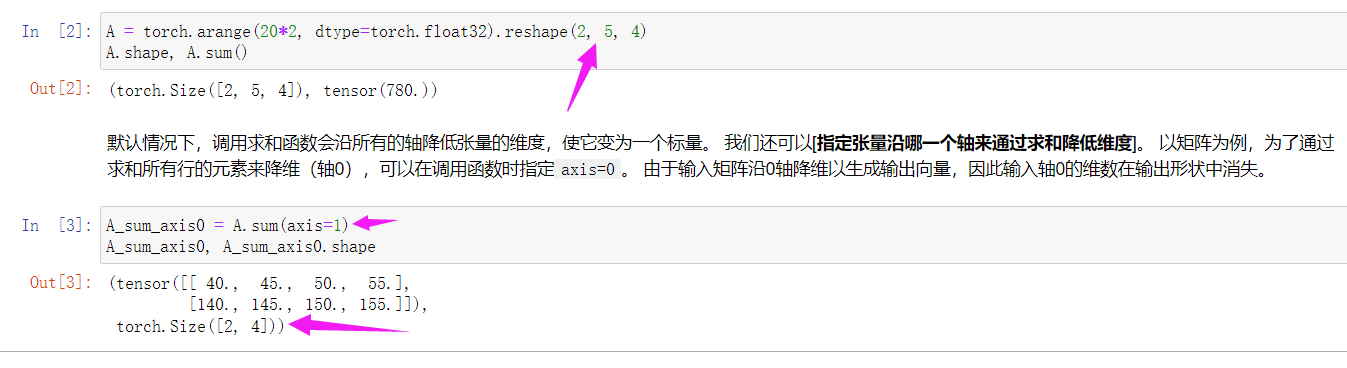
点积:
x = torch.arange(4, dtype=torch.float32)
y = torch.ones(4, dtype = torch.float32)
x, y, torch.dot(x, y)
# 结果:(tensor([0., 1., 2., 3.]), tensor([1., 1., 1., 1.]), tensor(6.))
# 这个结果和点积结果一致
torch.sum(x * y)**矩阵*向量:**
A = torch.arange(20, dtype=torch.float32).reshape(5, 4)
# 注意A是一个5x4矩阵,x是一个4x1列向量,结果为5x1的列向量
A.shape, x.shape, torch.mv(A, x)矩阵乘法:
B = torch.ones(4, 3)
# mm只能二维,多维要matmul,可以@表示矩阵乘法
torch.mm(A, B)范数:
# 𝐿2范数中常常省略下标2,也就是说‖𝐱‖等同于‖𝐱‖2
u = torch.tensor([3.0, -4.0])
torch.norm(u) # 结果:tensor(5.)
# 𝐿1范数
torch.abs(u).sum() # 结果:tensor(7.)
# 计算矩阵的Frobenius范数
torch.norm(torch.ones((4, 9))) # 结果:tensor(6.)3. 矩阵计算
矩阵求导的本质与分子布局、分母布局的本质(矩阵求导——本质篇):https://zhuanlan.zhihu.com/p/263777564
向量点乘的求导:https://www.bilibili.com/video/BV1Qd4y1Q77d/?vd_source=7e34085a459b4e9ffab42ccd04776d69
点乘和叉乘满足乘法求导规则,但是记得,如果表示的是矩阵乘法,要将列向量转置一下
默认分子布局

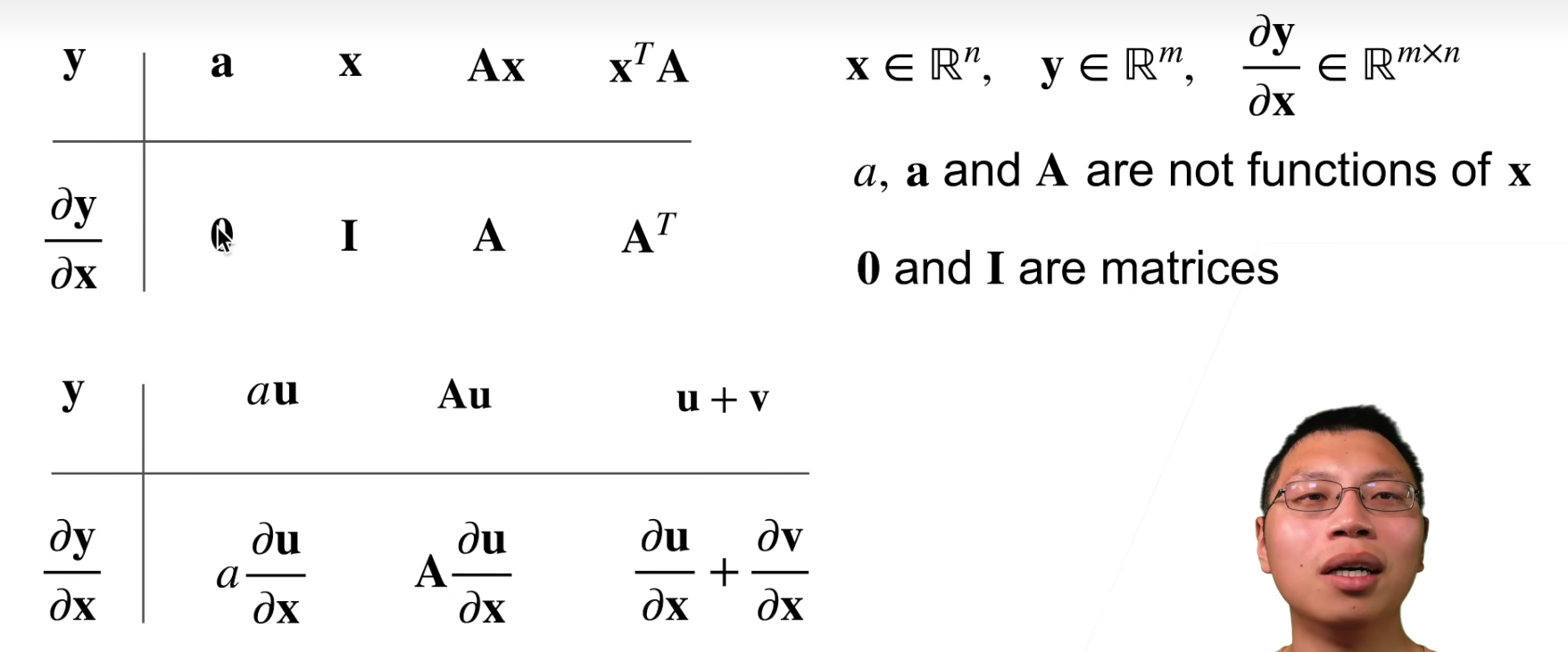

4. 自动求导
链式法则,向量同样适应(可从对应的向量、矩阵大小看出)
一文解释 PyTorch求导相关 (backward, autograd.grad)
4.1 实现
import torch
x = torch.arange(4.0)
x
# [在我们计算 𝑦关于 𝐱的梯度之前,需要一个地方来存储梯度。] ,我们不会在每次对一个参数求导时都分配新的内存。 因为我们经常会成千上万次地更新相同的参数,每次都分配新的内存可能很快就会将内存耗尽。
# grad表示梯度缩写gradient
x.requires_grad_(True) # 等价于x=torch.arange(4.0,requires_grad=True)
x.grad # 默认值是None
y = 2 * torch.dot(x, x)
y
y.backward() # 反向传播函数
x.grad # tensor([ 0., 4., 8., 12.])
x.grad == 4 * x
# 在默认情况下,PyTorch会累积梯度,我们需要清除之前的值
x.grad.zero_()
y = x.sum()
y.backward()
x.grad
# 对非标量调用backward需要传入一个gradient参数,该参数指定微分函数关于self的梯度。
# 本例只想求偏导数的和,所以传递一个1的梯度是合适的
x.grad.zero_()
y = x * x
# 等价于y.backward(torch.ones(len(x)))
y.sum().backward()
x.grad
x.grad.zero_()
y = x * x
# 将u作为常数处理
u = y.detach()
z = u * x
z.sum().backward()
x.grad == u
x.grad.zero_()
y.sum().backward()
x.grad == 2 * x
def f(a):
b = a * 2
# norm是求L2范数,即平方和开根号
while b.norm() < 1000:
b = b * 2
if b.sum() > 0:
c = b
else:
c = 100 * b
return c
# size=()表示标量
a = torch.randn(size=(), requires_grad=True)
d = f(a)
d.backward()
print(a.grad == d / a)
a.grad函数
因为相当于求范数2