Redis笔记
https://redis.io/docs/data-types/
http://www.redis.cn/commands.html
1. Redis10大数据类型
注意:这次的数据类型指的是value的类型,因为key的类型一般是字符串
- 字符串String
- 列表List
- 哈希表Hash
- 集合Set
- 有序集合Zset
- 地理空间GEO
- 基数统计HyperLogLog
- 位图bitmap
- 位域bitfield
- 流Stream
help @类型 帮助命令
### 1.1 字符串String
概念:
string类型是二进制安全的,
意思是redis的string支持序列化,string可以包含任何数据,比如图片或者序列化的对象
一个redis中字符串value最多可以是512M
单值单value
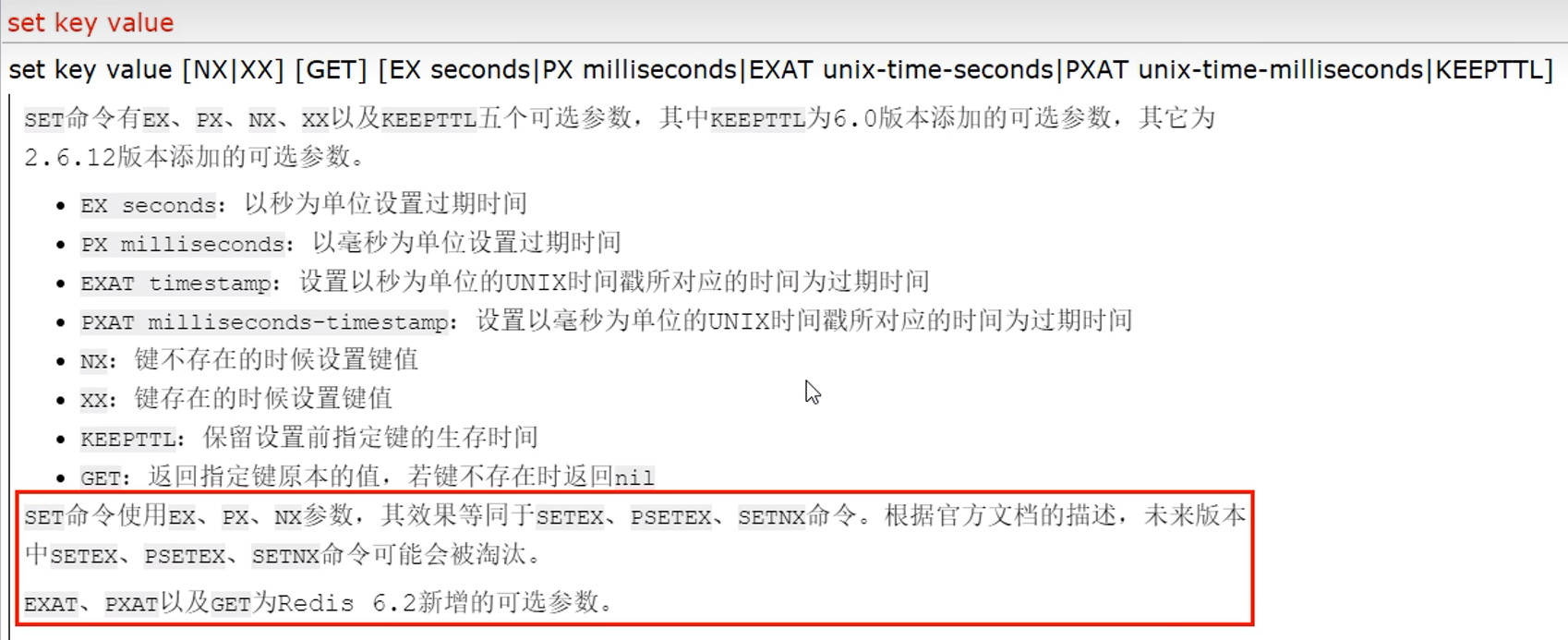
常用命令:
下面的keepttl,用于保持一个kv的过期时间,因为直接set会导致前面设置的过期时间失效
下面的unix时间戳,可以参照System.currentTimeMillis(),返回的就是毫秒值
mset,mget,msetnx就是批量的操作(mset 是 Multi-Set的缩写)
对于msetnx,它的操作是作为一个整体,批量中只要有一个已存在,就不执行
getrange/setrange:
比如getrange k1 0 -1
0 -1表示获取全部
如果把0和-1改成你想要的索引,就能获取到指定的部分字符串,两个位置都是闭区间
set key 起始位置(包括这位开始替换) 你的字符串
incr/incrby/decr/decrby:
value必须是数字
incr key
incrby key 增加的大小
setnx,setex:已经过期,可以通过set的参数来实现

1.2 列表List
概念:
底层实际是一个双端链表
可添加到头部或者尾部
最多可以包含232-1个元素(4294967295,超过40亿个元素)
如果值全部移除,对应的键也就消失了
一个key多个value
应用于:比如微信公众号订阅的消息
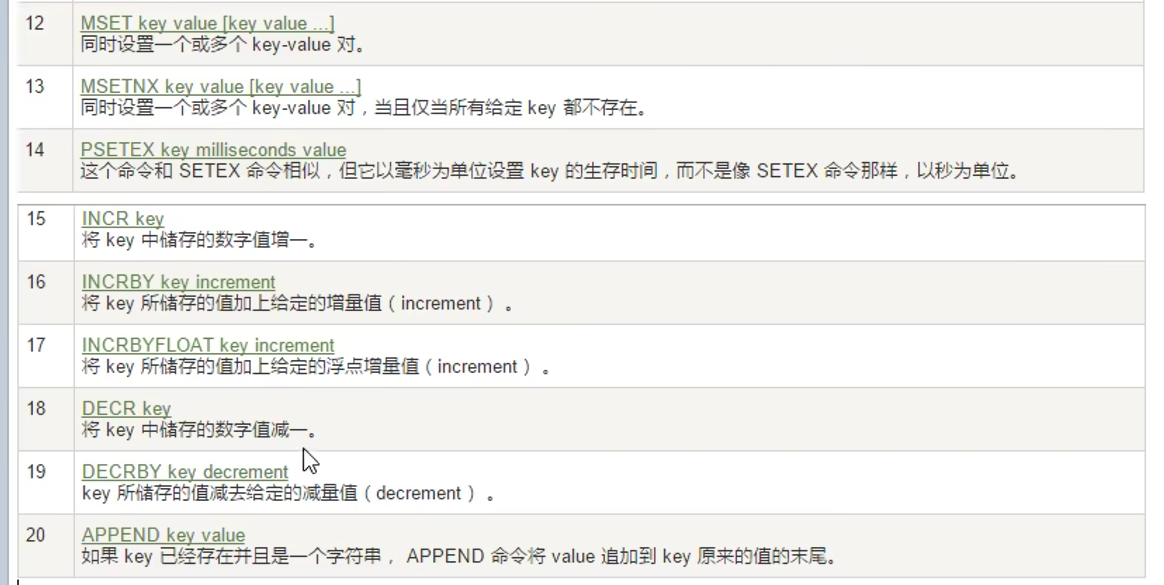
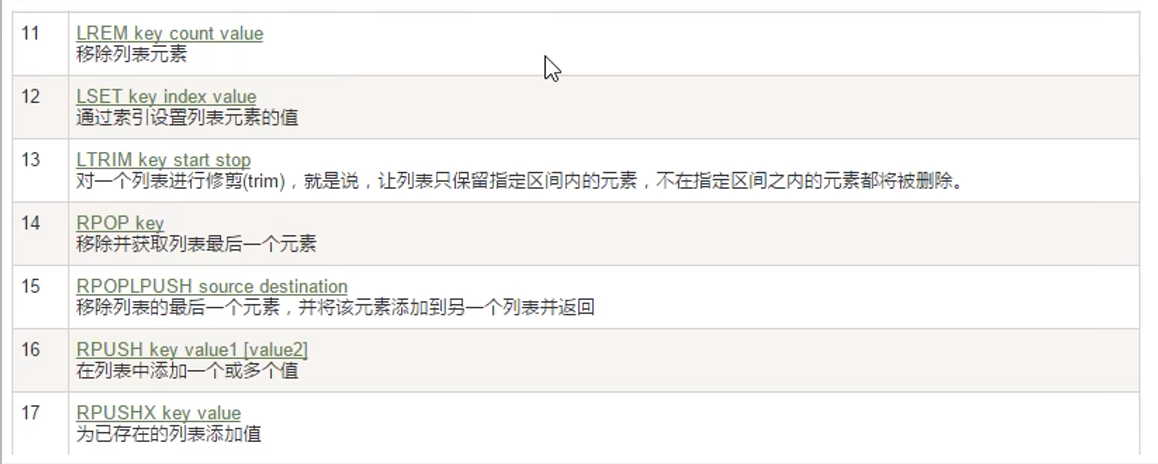
常用命令:
只有lrange,lindex,没有rrange,rindex命令
可以通过-1,-5这样从右边开始访问
lrange指的是从左边开始遍历
lpush从左边插入
rpush从右边插入
lrem key N v1 删除N个值位v1的元素
rpoplpush(已经弃用),改为lmove 源list 目的list left|right left|right

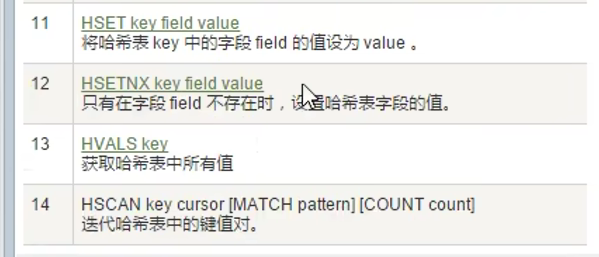
1.3 哈希表Hash
概念:
string类型的filed字段和value
适合用于存储对象
每个hash可以储存232-1个键值对(40多亿)
k v键值对中的 value 是一个哈希表 hash
常用命令:
hmset被弃用,用hset就能实现
hgetall,会显示键1,值1,键2,值2......
hdel删除一个字段,del删除整个hash

1.4 集合Set
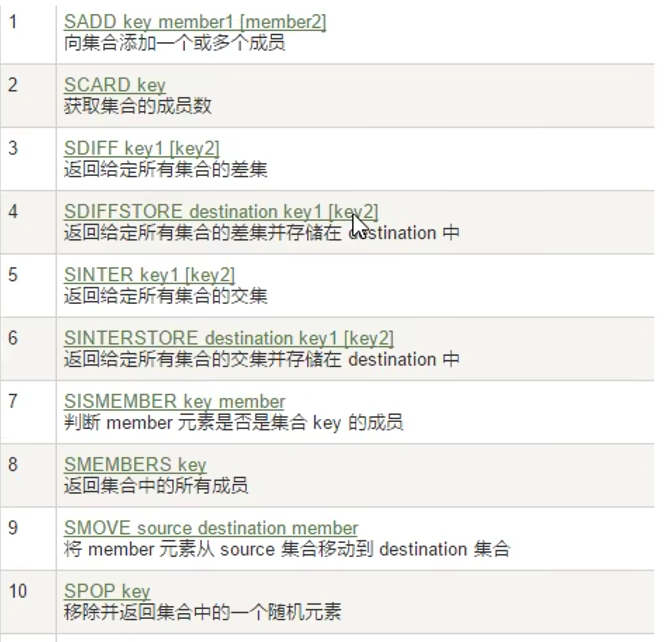
概念:
String类型的无序集合,集合成员唯一
集合对象的编码可以是intset或者hashtable
Redis中的Set底层通过哈希表实现,所以添加,删除,查找的复杂度都是O(1)
集合最大成员同样40多亿
应用场景:
抽奖,查看点赞朋友,可能认识的人,共同关注
常用命令:
sintercard交集的个数,redis7新增

1.5 有序集合Zset(Sorted set)
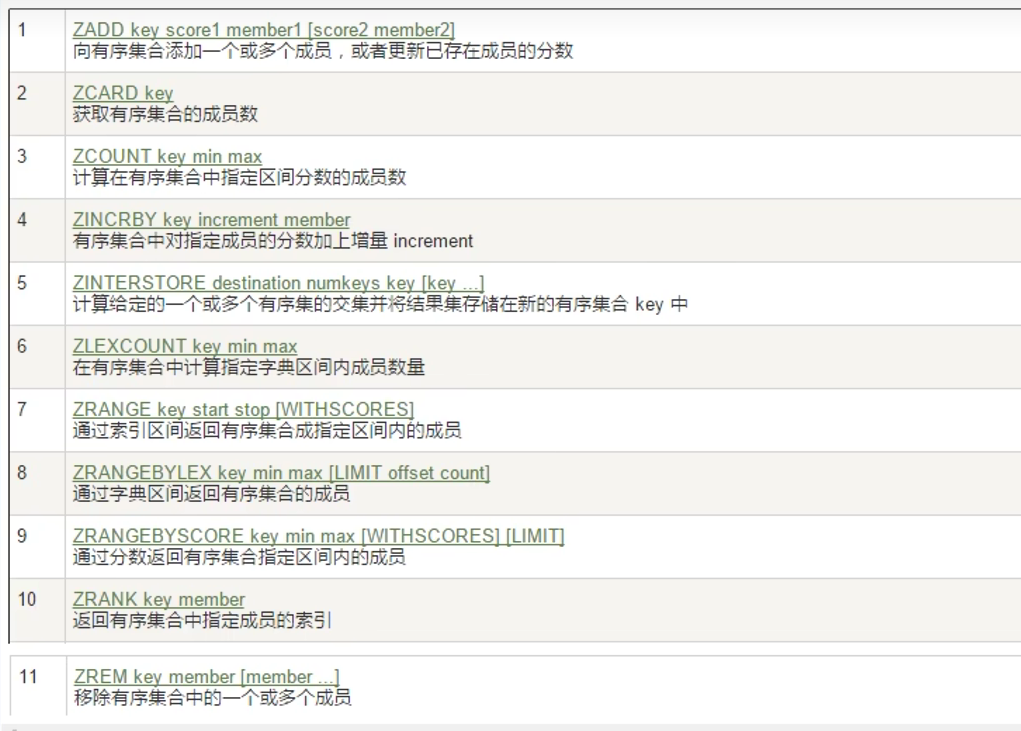
概念:
Redis的zset和set一样是string类型元素的集合,不允许重复
不同之处是:zset的每个元素都会关联一个double类型的分数,分数可以重复,redis通过分数来进行从小到大排序
也是通过哈希表实现,添加,删除,查找的复杂度为O(1),集合的最大成员数为40多亿
应用:
商品排序
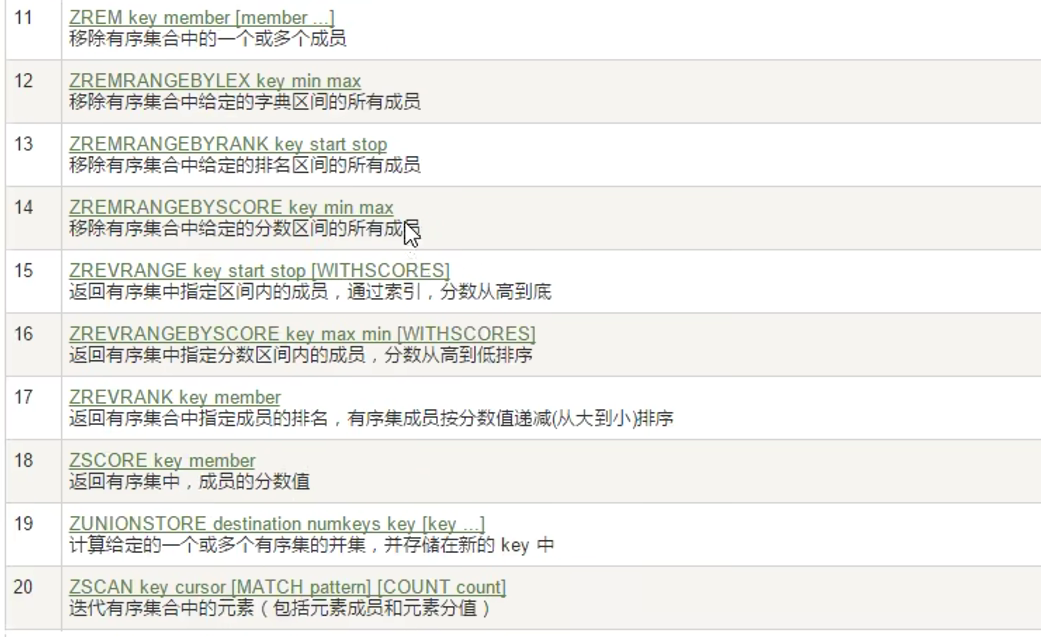
常用命令:
按score从小到大排序
1.下面命令的左括号表示不包含,默认包含,只有左括号的表达方式,limit 0 2表示从0开始取2条数据
zrangebysocre zset (60 (90 withscores limit 0 2
2.下面是redis7的新增命令
ZMPOP numkeys key [key ...] <MIN | MAX> [COUNT count]从键名列表中的第一个非空排序集中弹出一个或多个元素,它们是成员分数对。当使用MIN修饰符时,弹出的元素是第一个非空排序集中得分最低的元素。MAX修改器会弹出得分最高的元素,numkeys表示key的数量
可选的COUNT可用于指定要弹出的元素数量,默认情况下设置为1,弹出元素的数量是排序集的基数和COUNT值中的最小值

1.6 地理空间GEO
概念:
经纬度,存储地理位置信息
并且可以进行操作:
- 添加地理位置的坐标
- 获取地理位置的坐标
- 计算两个位置之间的距离
- 根据用户给定的经纬度坐标来获取指定范围内的地理位置集合
类型:zset
中文乱码问题:
进入redis客户端时加入参数raw
redis-cli -a 123456 --raw常用命令:

georadiusbymember与georadius相比不写经纬度,而是名称

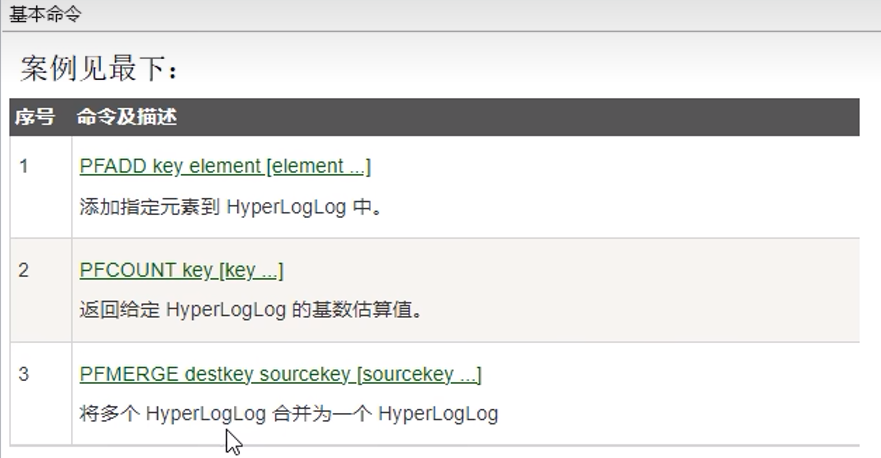
1.7 基数统计HyperLogLog
概念:
用来做基数统计的算法
类型属于string
注:HyperLogLog以完美的准确性换取有效的空间利用。
Redis HyperLogLog实现最多使用12 KB,标准误差为0.81%。
基数:一种数据集,去重后的真实个数
优点:输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定且是很小的
在Redis里,每个HyperLogLog键只需要花费12KB,就可以计算接近264个不同元素的基数。
这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比
但是,因为HyperLogLog只会根据输入元素来计算基数,而不会存储输入元素本身,所以HyperLogLog不能像集合那样,返回输入的各个元素
常用命令:
1.8 位图bitmap
概念:
0和1状态表现的二进制位的bit数组
偏移量从0开始
只能是0和1
type bitmap ----> string
应用:
打卡签到记录
常用命令:
setbit的返回值,不代表成功,而是set之前的值
get bitmap 返回的是对应的字符串(一个字节占8位,所以8个一组,超过8位自动扩容,8位,8位扩容)
bitcount返回的是1的数量
默认情况下,bitcount按byte,如果start end 要按bit算,要写明bit
BITCOUNT key [start end [BYTE | BIT]]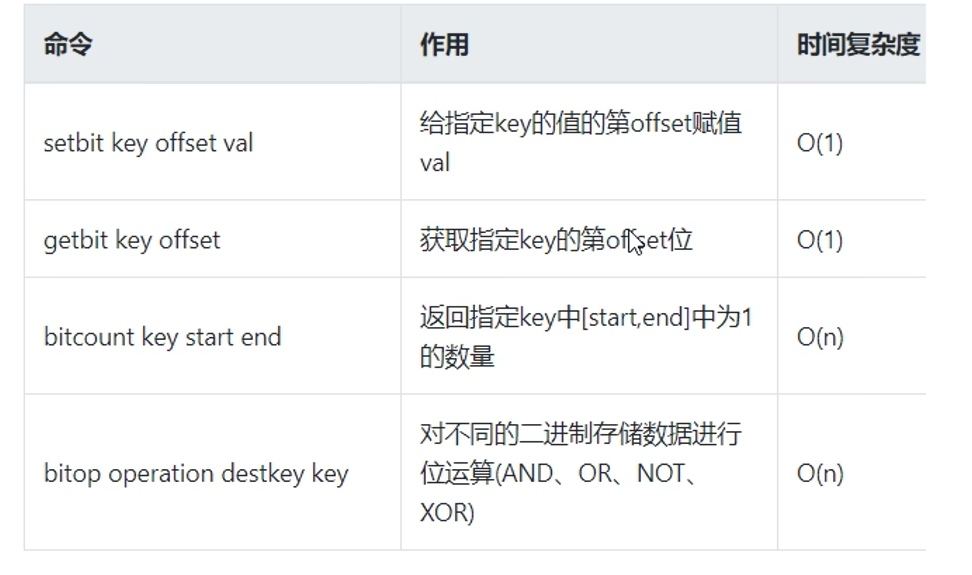
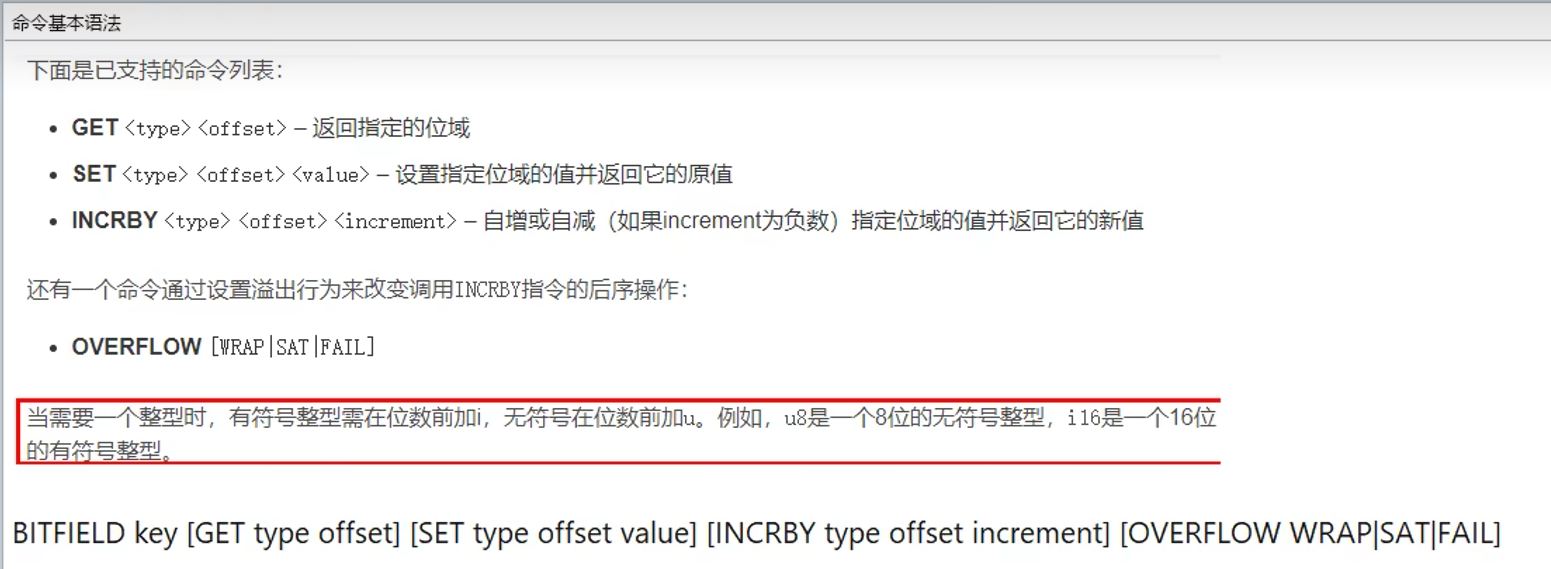
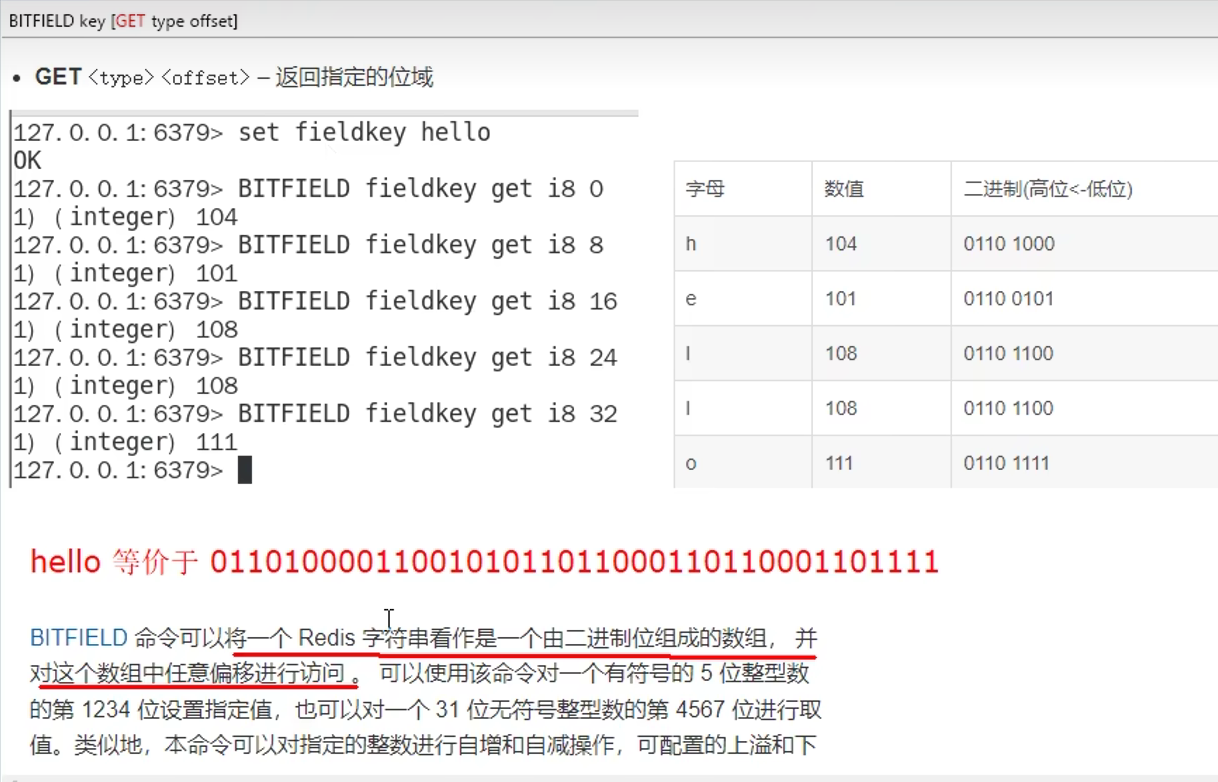
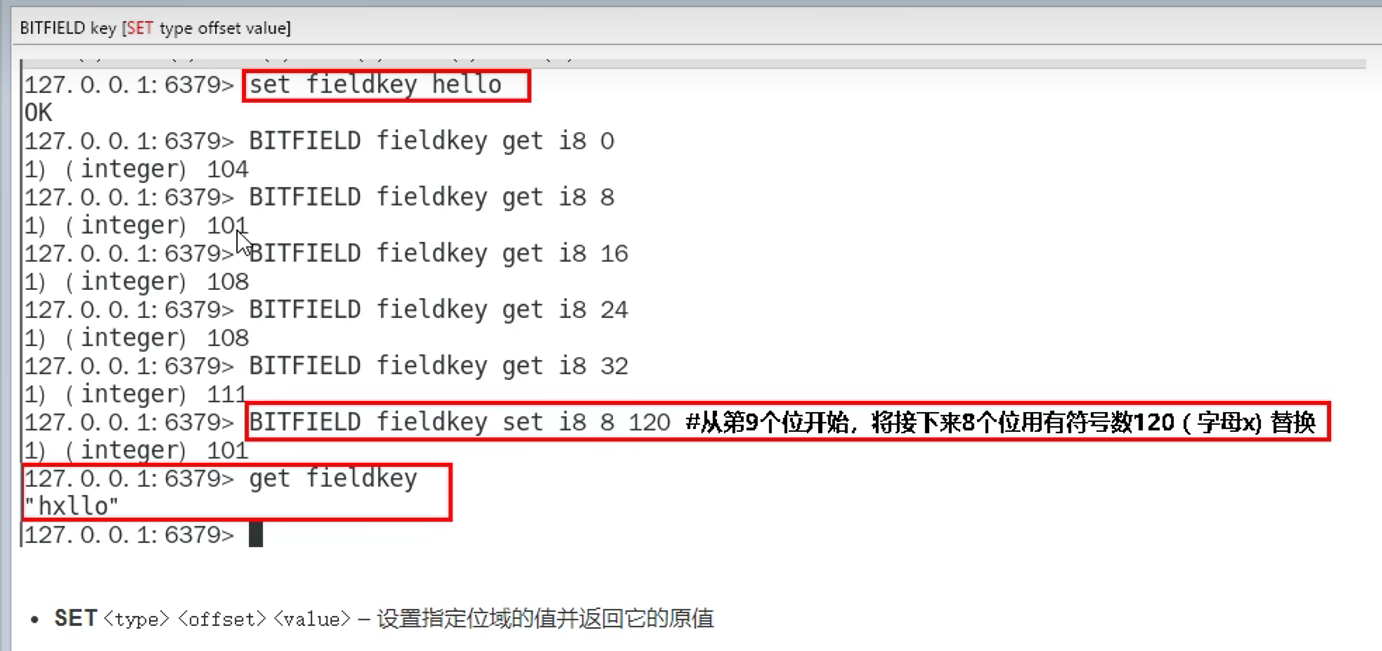
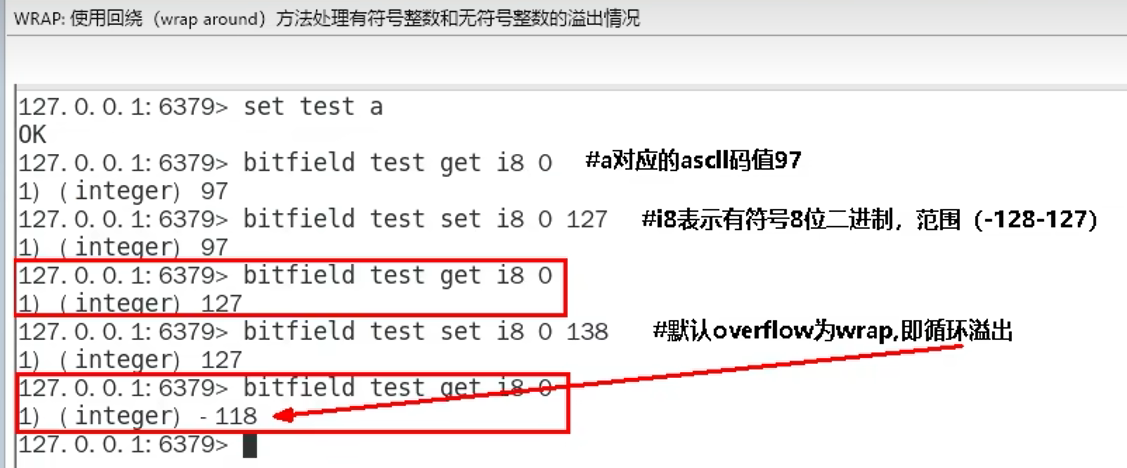
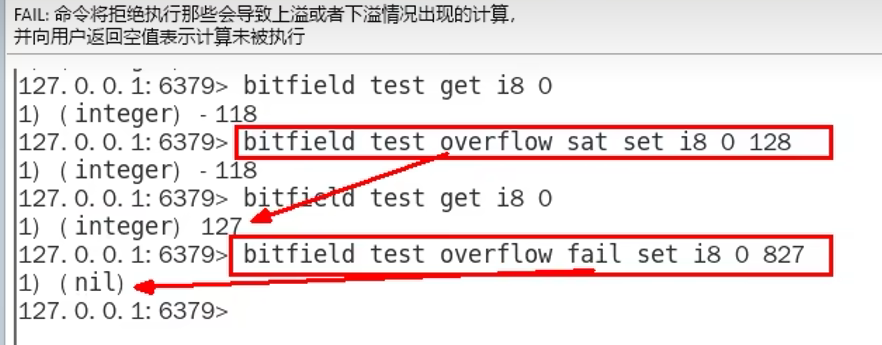
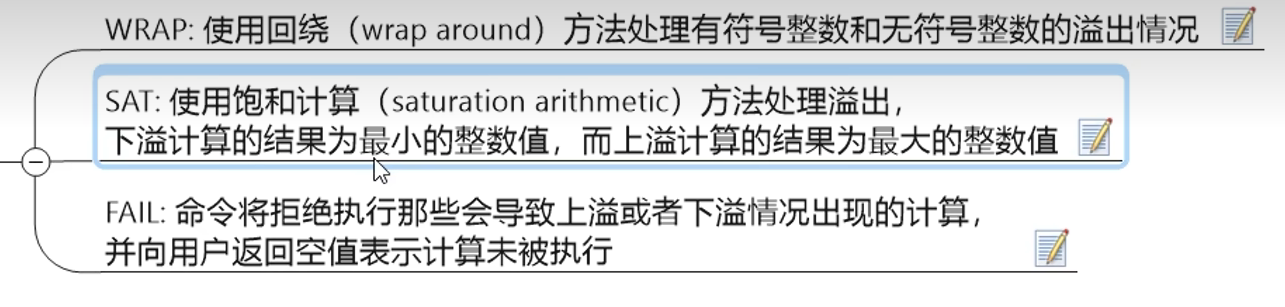
1.9 位域bitfield(使用少,了解)
概念:
通过bitfield命令可以一次性操作多个比特位域(连续多个比特位),执行一系列操作并返回一个响应数组
这个数组中的元素对应参数列表中的相应操作的执行结果
作用:
1. 位域修改,直接修改对应的bit位
1. 溢出控制命令:


1.10 流Stream
概念:
用于消息队列MQ,
Redis原本有发布订阅(pub/sub)来实现消息队列,但缺点是消息无法持久化
如果网络断开,Redis宕机等,消息就会被丢弃,无法记录历史消息
而Redis Stream提供了消息的持久化和主备复制功能,
可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失
类型:
type mystream --> stream
历程:
1. 简单的用list,lpush,rpop能实现(只能点对点,不能一对多),无法实现发布订阅
因此引入了发布订阅**,能一对多了
2. 但是无法实现消息的持久化,如果出现网络断开,Redis宕机等,消息就会被丢弃
而且没有Ack机制来保证数据的可靠性,如果一个消费者都没有,消息就丢弃了
因此又引入了Stream的数据结构 (since Redis 5.0)
作用:

底层结构:
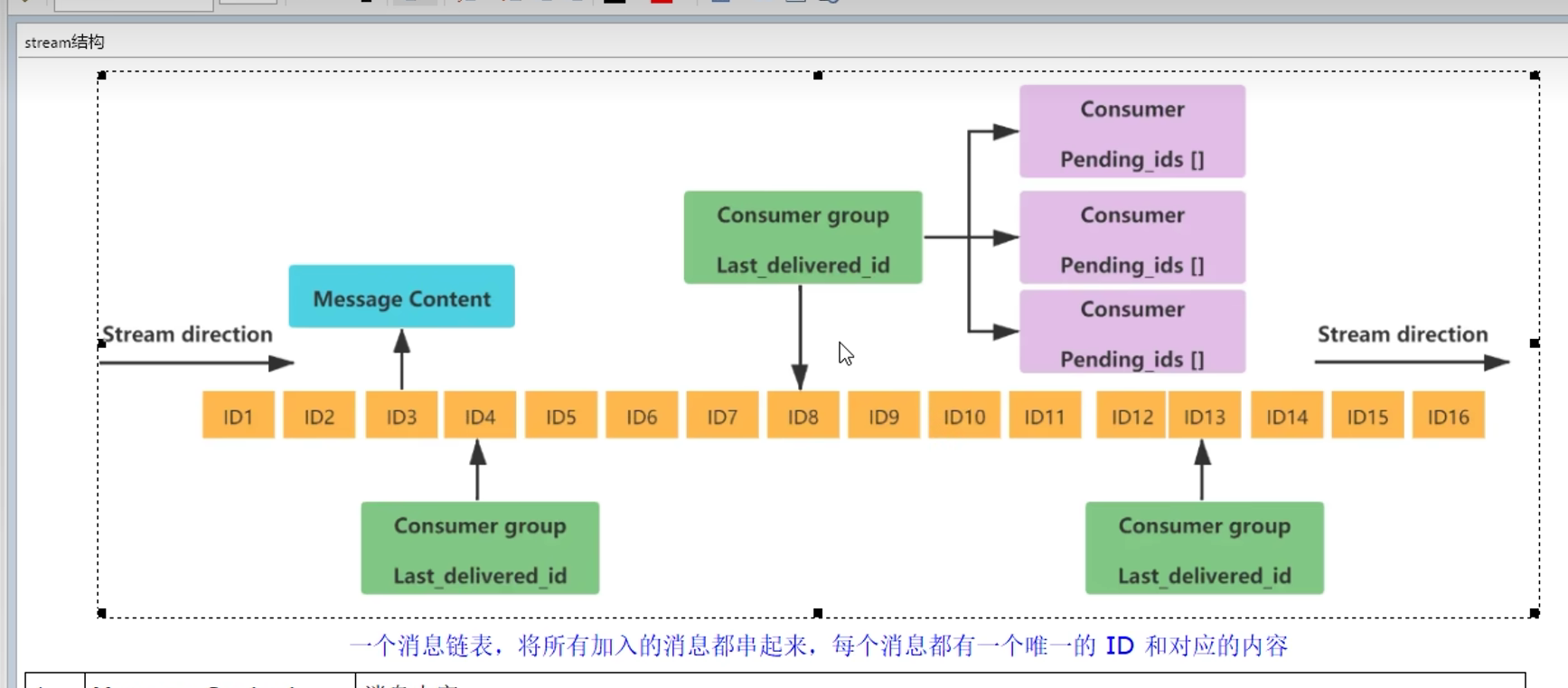
总结:Stream就是Redis版的MQ消息中间件+阻塞队列
常用命令:
xrange:
’-‘表示最小值,‘+’表示最大值,这个值和stream里面的id无关,相当于正无穷和负无穷
所以对于xrange,从小到大顺序, + -就返回空
和之前一样,默认前后都是闭区间,要想去掉边界就加上左括号,正负无穷不能加左括号
count表示最多获取多少个值,如果要限制获取个数,那么count单词必须写
xtrim:
minid: 允许的最小id,比它小的会抛弃
maxlen 允许的最大长度,会抛弃时间戳小的,也即保留最近时间的
这两个都要带上单词本身
xadd:
NOMKSTREAM表示不创建stream,只添加kv键值对
XADD key [NOMKSTREAM] [<MAXLEN | MINID> [= | ~] threshold
[LIMIT count]] <* | id> field value [field value ...]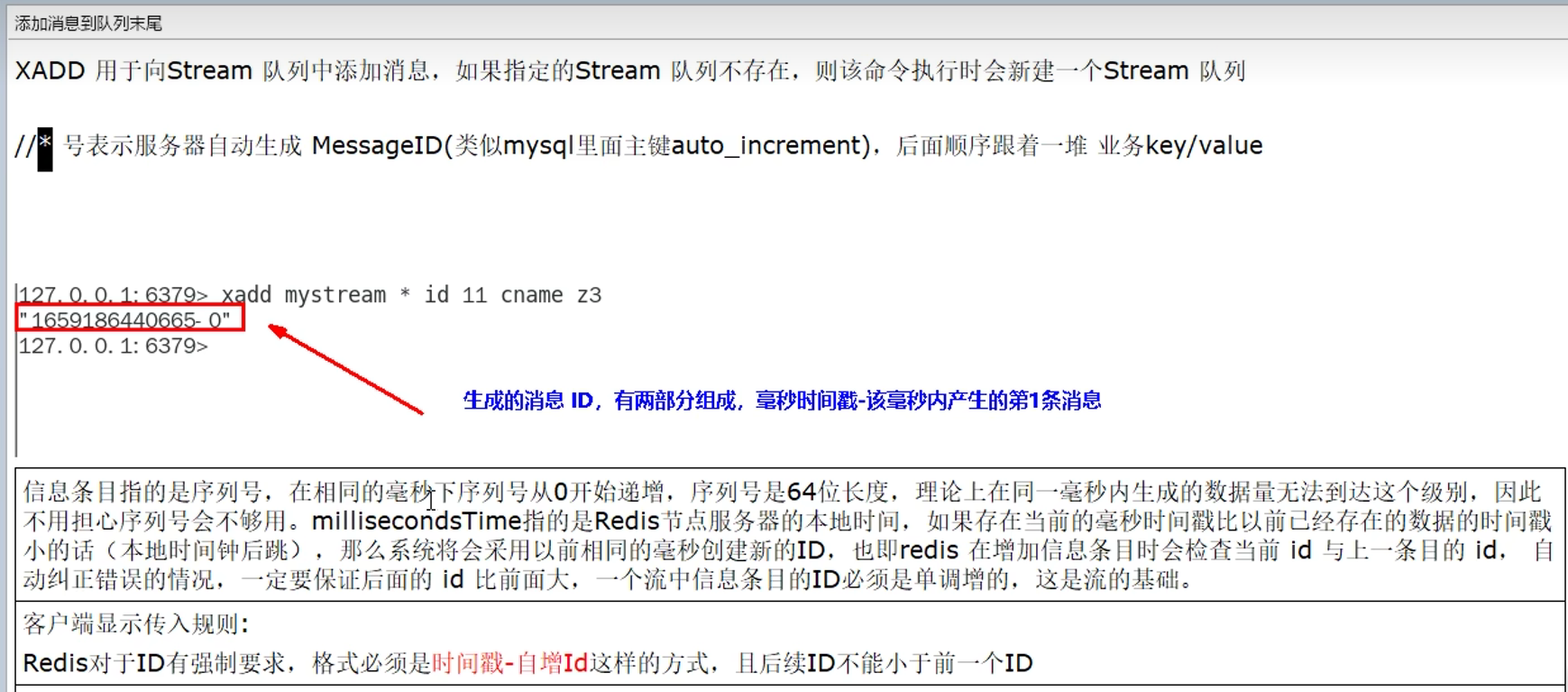
xread:
streams必须写
count(如果要写明条数,就要写count)
id表示从哪里开始,不包括该id,开区间
$是一个特殊ID,它比当前存储的最大ID还大,因此用于下一条消息(阻塞时接收消息)
id可以是0或者00或者000等,0等价于0-0(这个是redis编号id,毫秒-次序)
几个key就要写几个ID
xread不会影响stream,只是读取出来
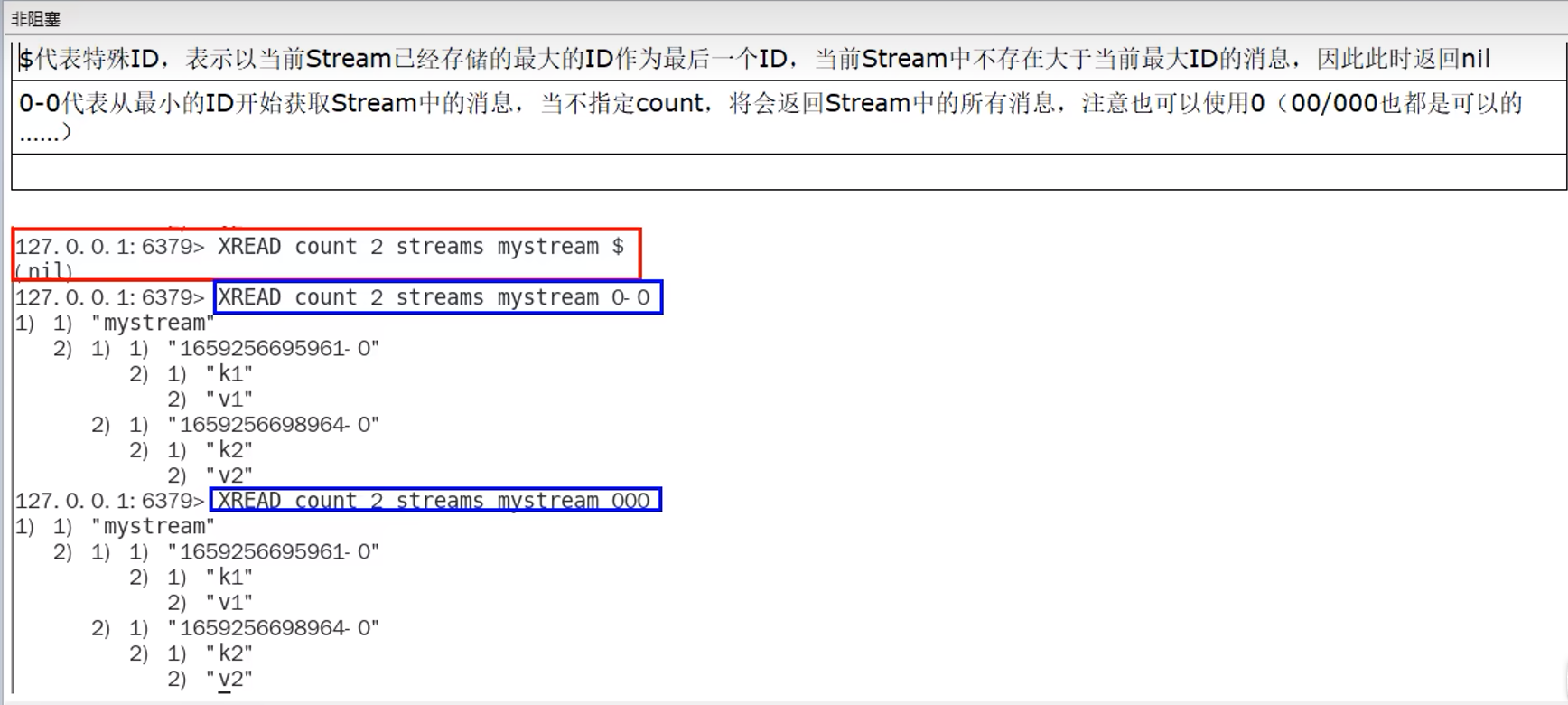
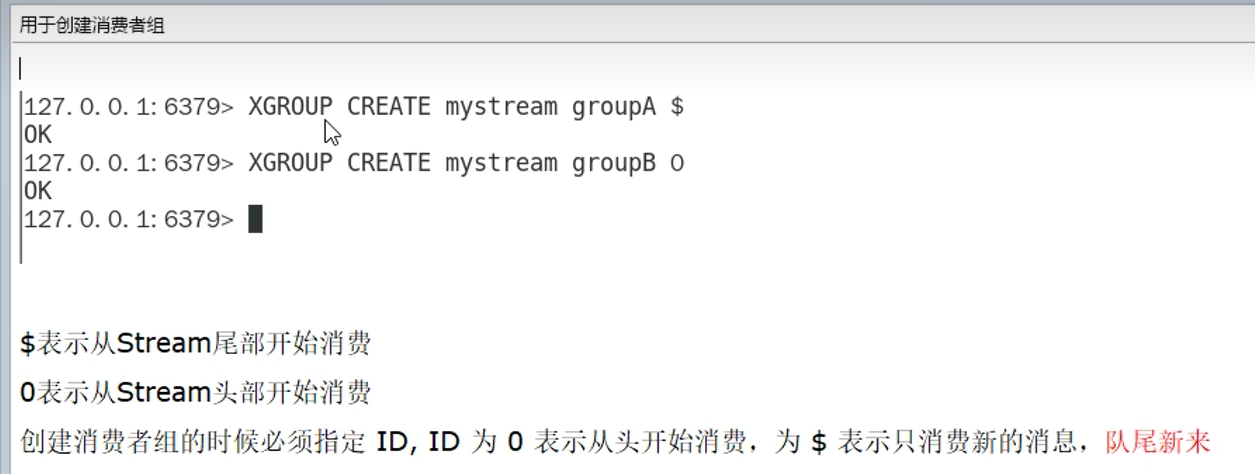
下面这里同一个消费组,一个消息只能读取一次,哪怕还是同一个消费者读取,也为nil
但是不同组可以消费同一个消息
这个均衡就相当于MQ中的轮询

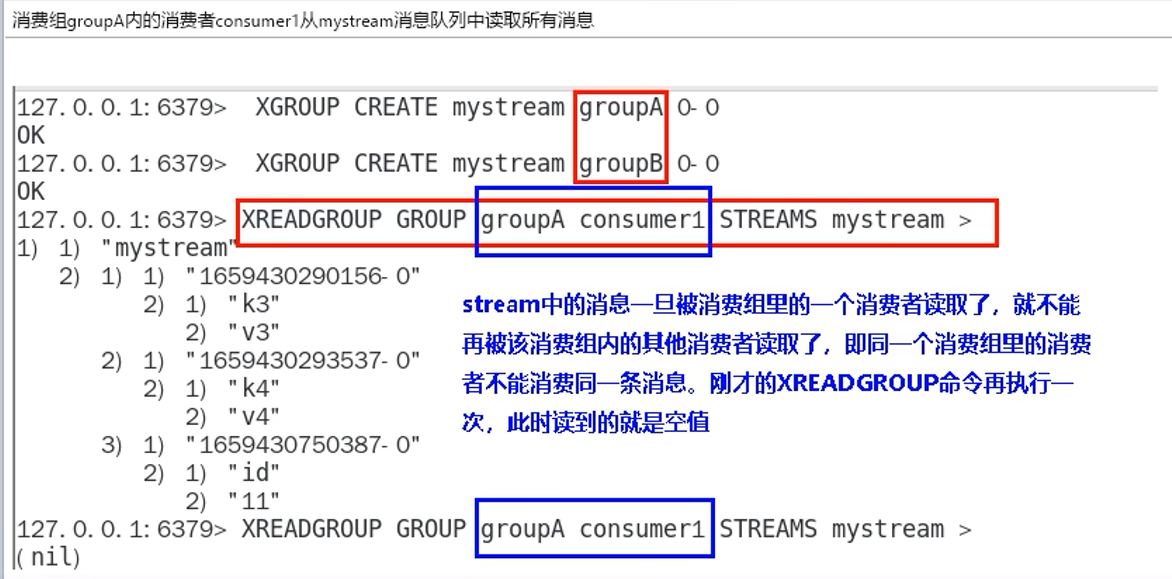
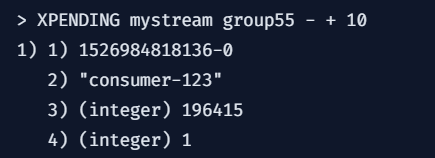
xpending:
额外参数:
传递一个id范围(与XRANGE类似)和一个非可选的count参数
以限制每次调用返回的消息数量,返回详细信息
如下图:
1.消息ID
2.消费但没确认的消费者名称
3.自上次将此消息传递给此消费者以来,到此刻所经过的毫秒数
4.此消息被传递的次数
当访问消费者组中的消费者历史记录时,则增加
这里的次数指的是传递给(消费者)自己的次数,与其他消费组的人无关
xclaim:
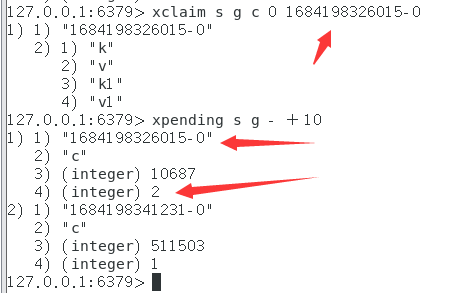
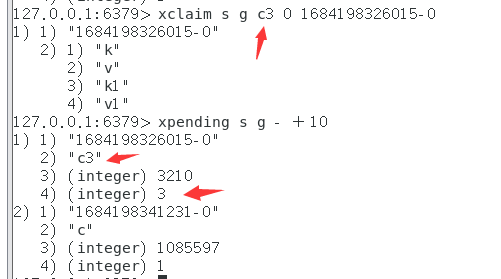
当其他消费者(或者当前消费过的消费者)使用XCLAIM声明消息时,都会+1
xclaim的retrycount可以直接指定count计数器的值
?或者当消息再次通过XREADGROUP传递时(一个消费组不是只能消费该消息一次吗)


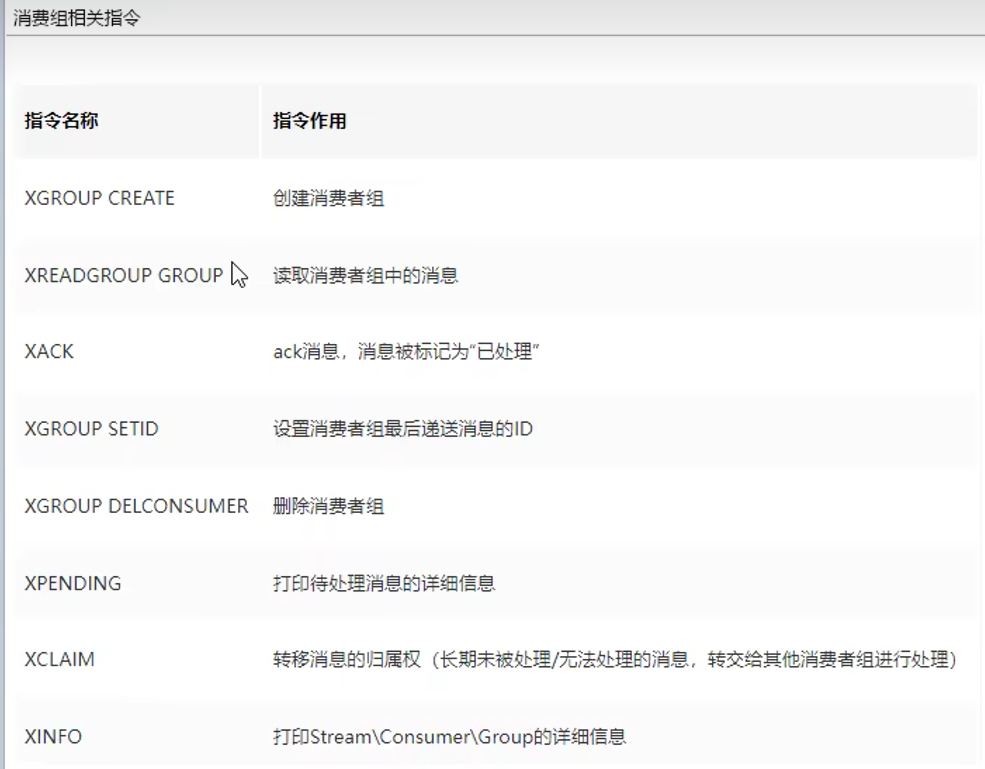


2. Redis 常用key操作命令
命令不区分大小写,但是key区分!!!


3. Redis持久化
3.1 RDB(redis database)
3.1.1 定义
在指定的时间间隔,把某一时刻的数据和状态以文件的形式写到磁盘上,也就是快照Snapshot,
这样即使宕机,快照文件也不会丢失,保证了数据的可靠性
保存备份执行的是全量快照,记录内存的所有数据
这个快照文件称为RDB文件(dump.rdb)
恢复时,将快照文件直接读回到内存
3.1.2 配置
Redis6:
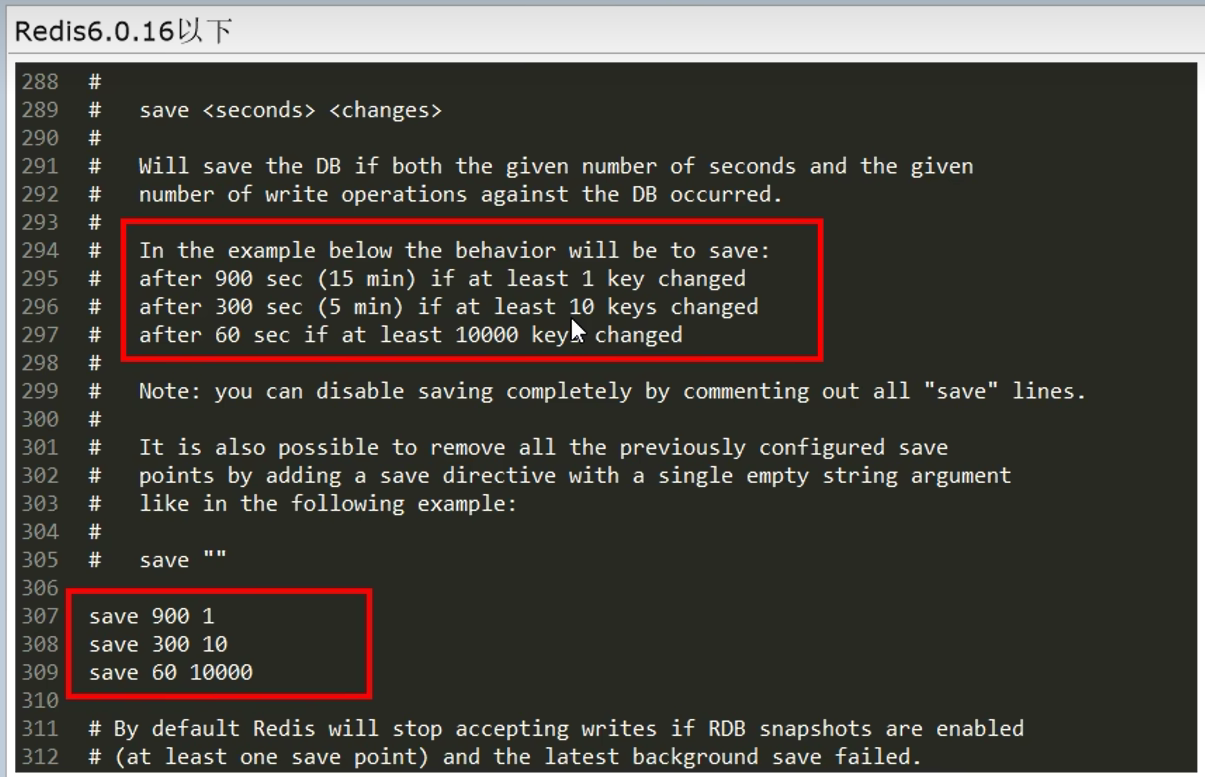
Redis7:

15min --> 1h 1
5min 10-->100
1min 10000
配置说明:
https://www.bilibili.com/video/BV13R4y1v7sP?p=30&vd_source=7e34085a459b4e9ffab42ccd04776d69
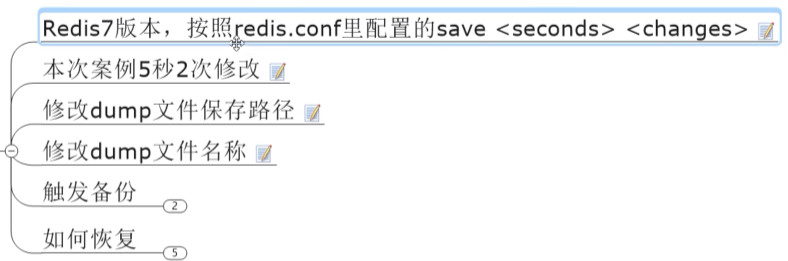
修改save
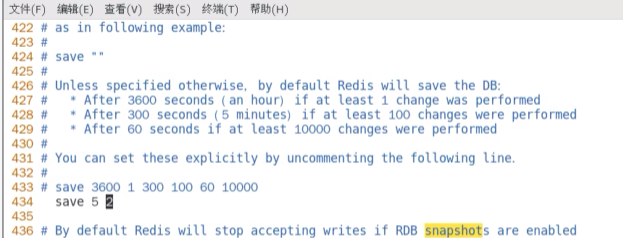
修改dump文件保存路径(文件夹要存在)
修改dump文件名称(加上端口号,方便区分不同的机器实例)
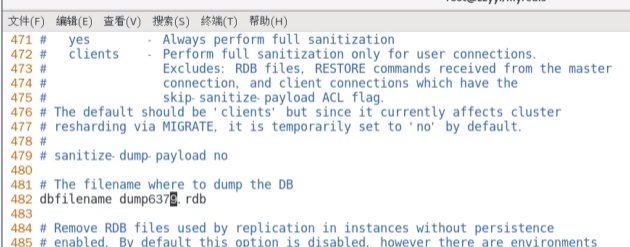
3.1.3 RDB自动触发
设置为5秒2次的结果:
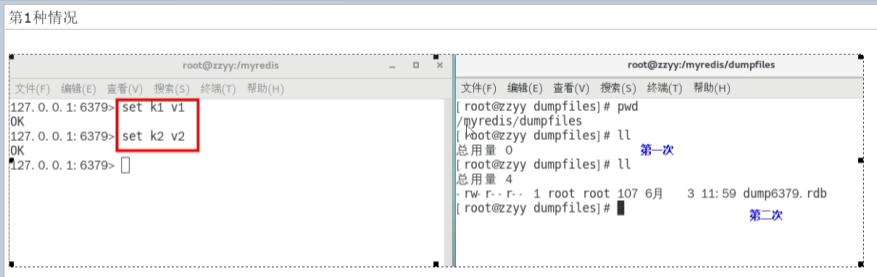
这里为什么超过了5秒,却更新了:
是因为5秒指的是检查,而更新的次数是累积的,第二个5秒检查到的是从上次save以来累积的次数,
达到了2次,所以文件变化
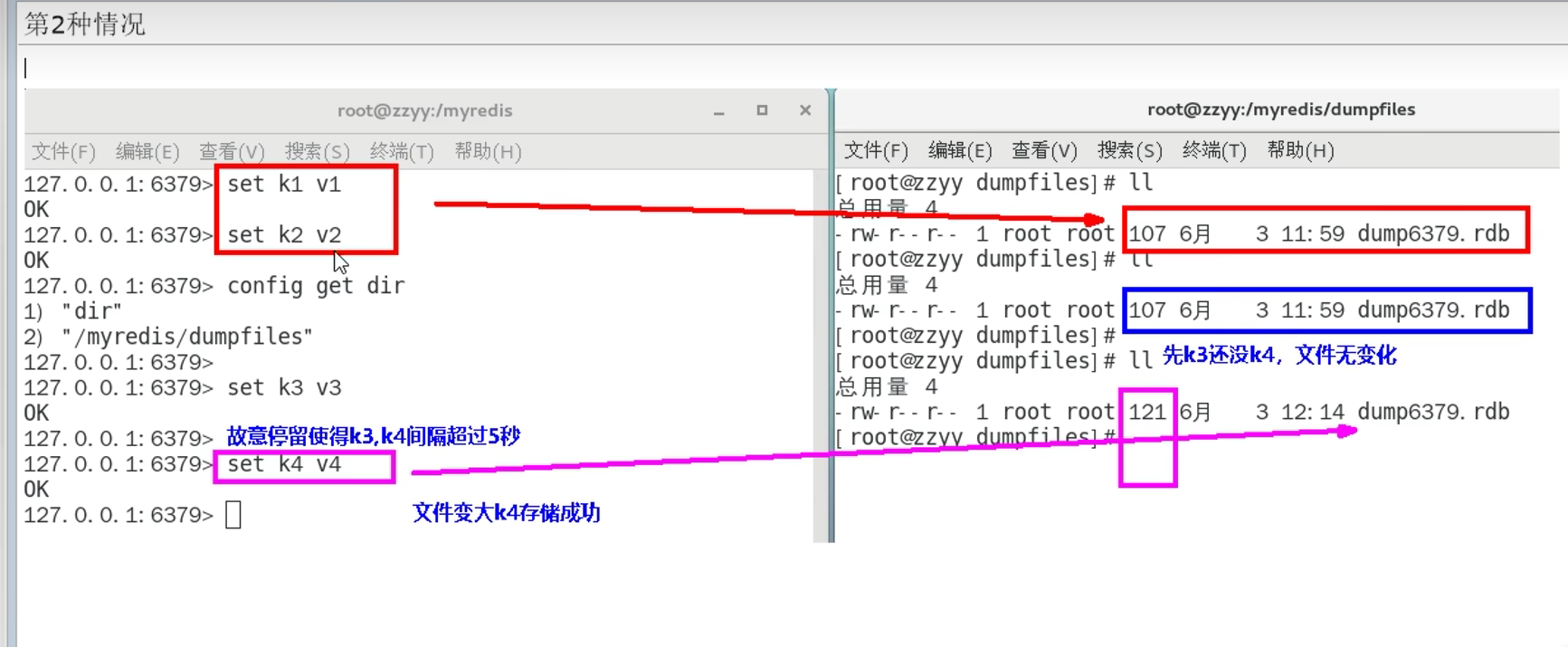
flushdb/flushall会产生一个dump.rdb文件,里面是空的,无意义
shutdown这种宕机操作,会自动保存当前快照(但是kill进程这种不会保存)
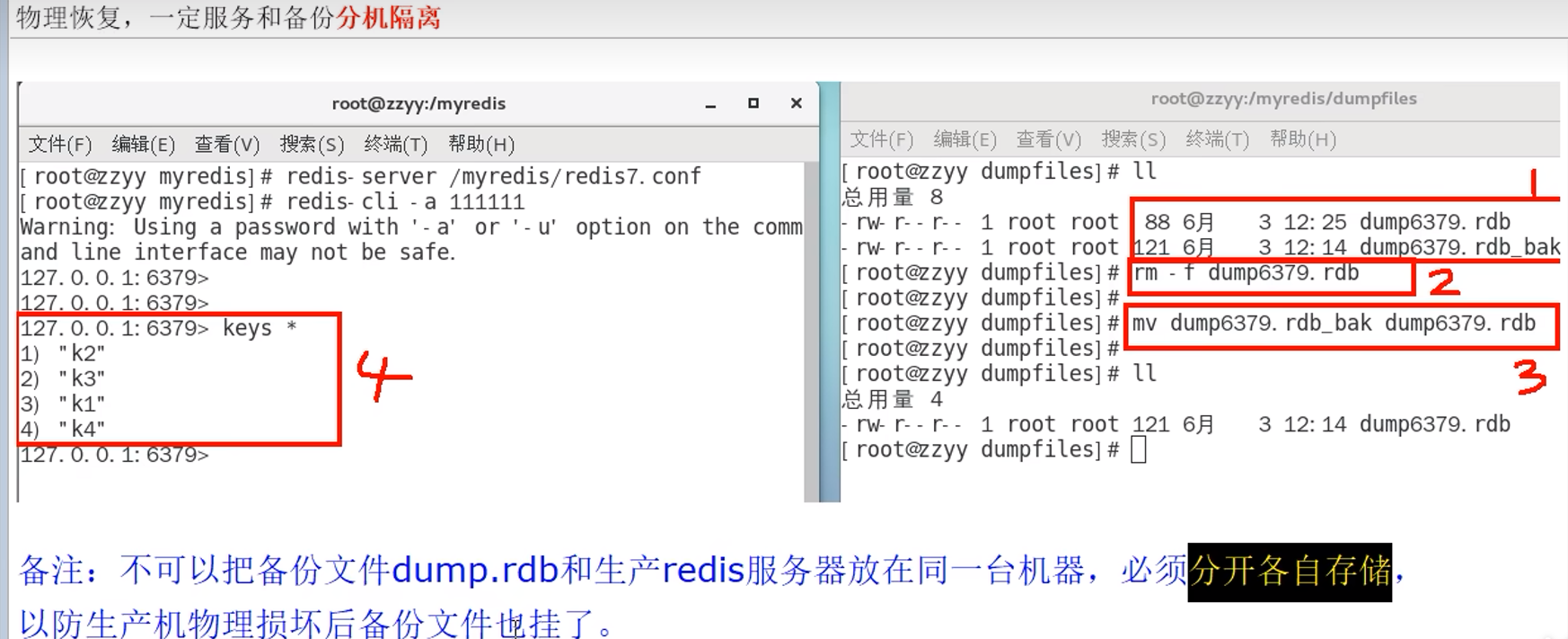
下图的备注指的是:dump.rdb和redis服务器要放在不同的机器上

3.1.4 RDB手动触发
- save
- bgsave(一般用这个)
save:
会阻塞当前redis服务器,直到持久化完成,持久化时Redis不能处理其他命令,线上禁止使用
bgsave:
在后台进行异步的快照操作,不会阻塞,持久化的同时,redis可以响应客户端请求,该触发方式
会fork一个子进程,由子进程进行持久化过程

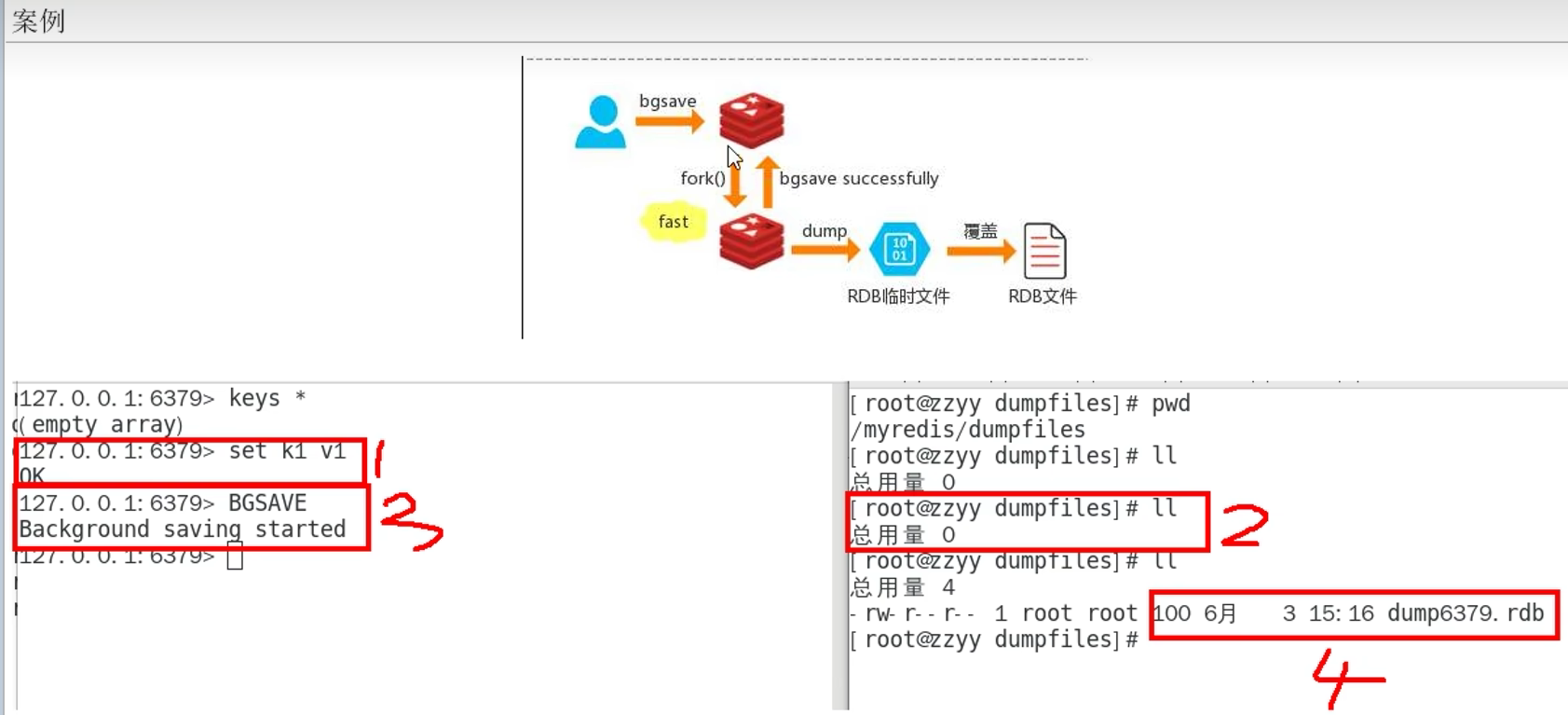
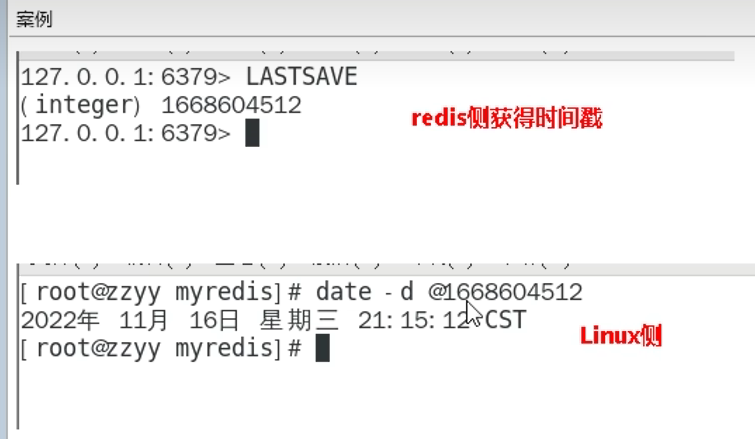
lastsave查看上一次保存时间(linux下可通过date -d转成日期时间)
3.1.5 RDB优点


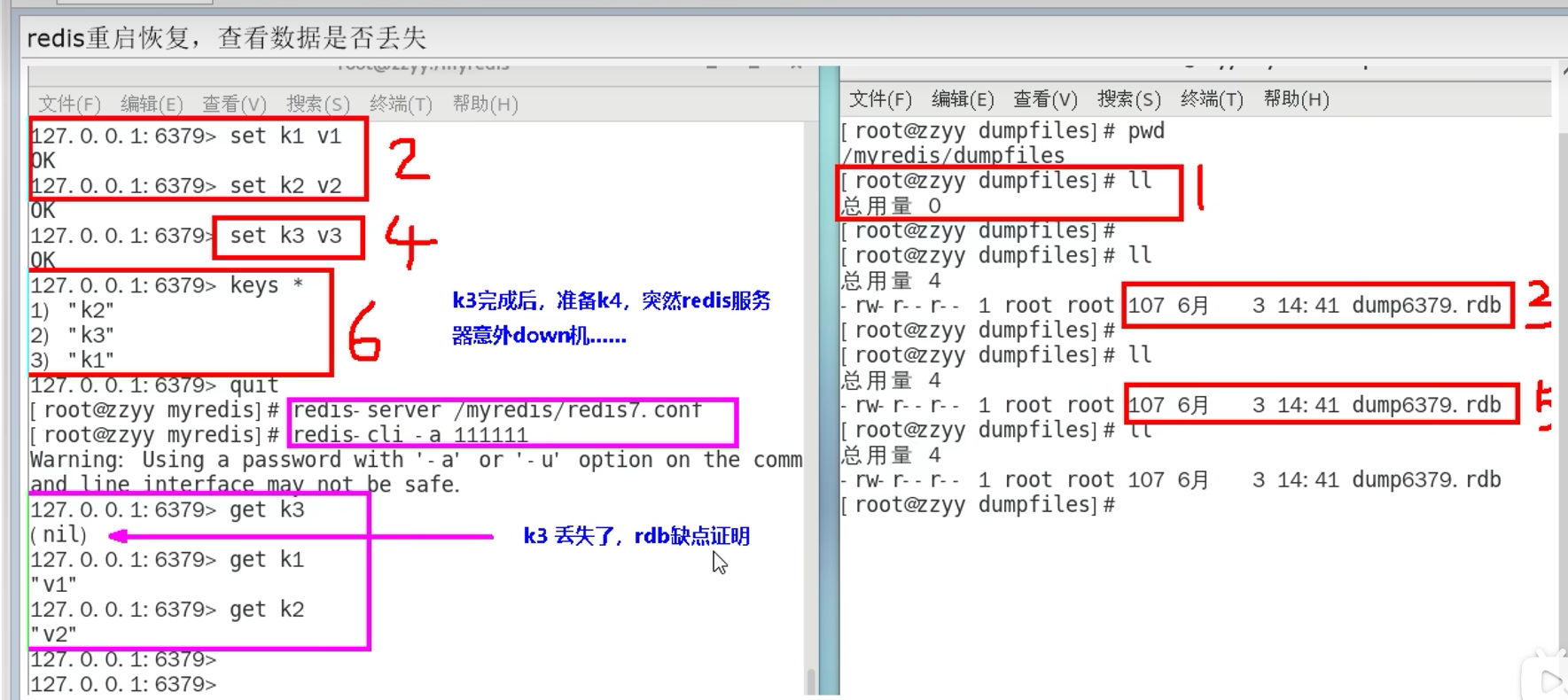
3.1.6 RDB缺点
意外down掉(比如kill -9)快照之间的数据会丢失


3.1.7 RDB修复
保存的时候,突然断电宕机,可能写入不完整,文件破损,
因为这一条,可能导致整个文件无法使用,此时就需要修复
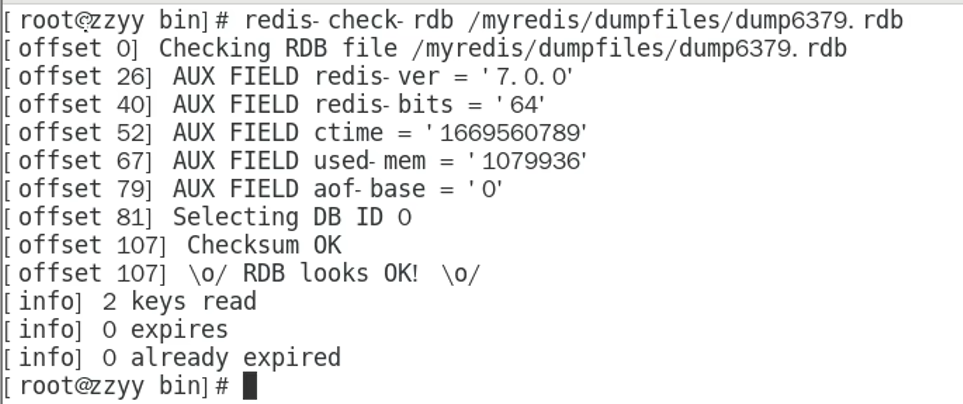
3.1.8 RDB小结




3.1.9 RDB优化参数


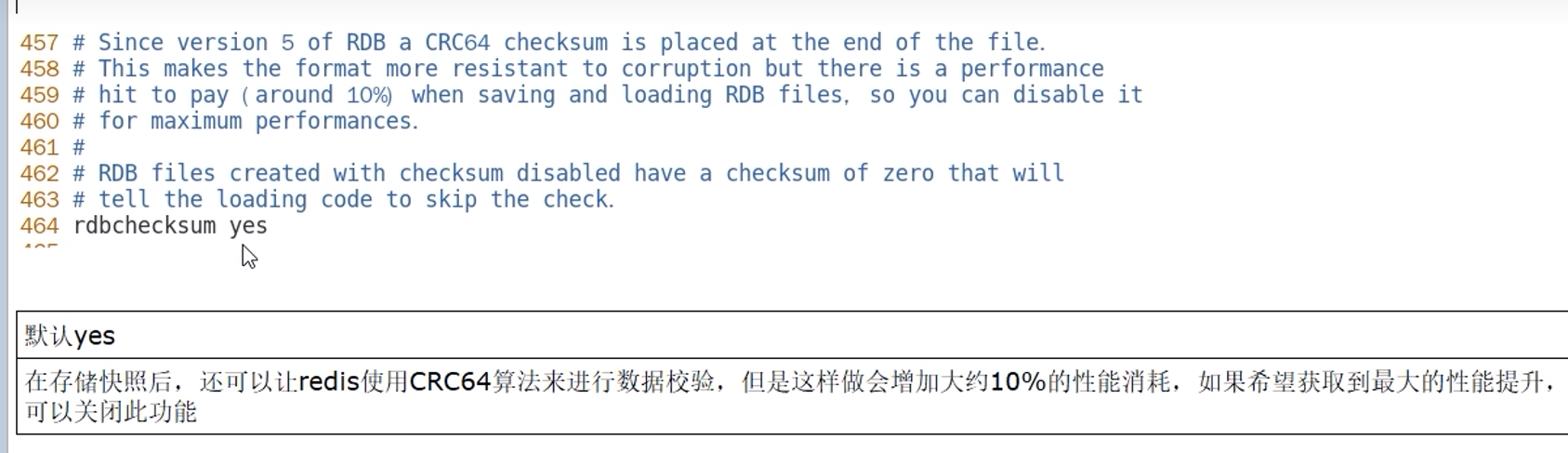

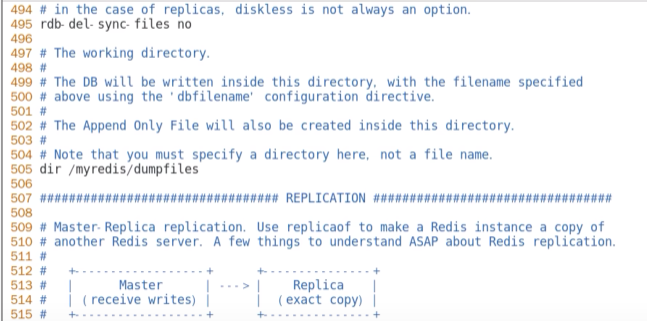
主从复制时,是否删除用于同步的从机上的 RDB 文件。默认是 no,不删除。
不过需要注意,只有当从机的RDB 和 AOF持久化功能都未开启时才生效。
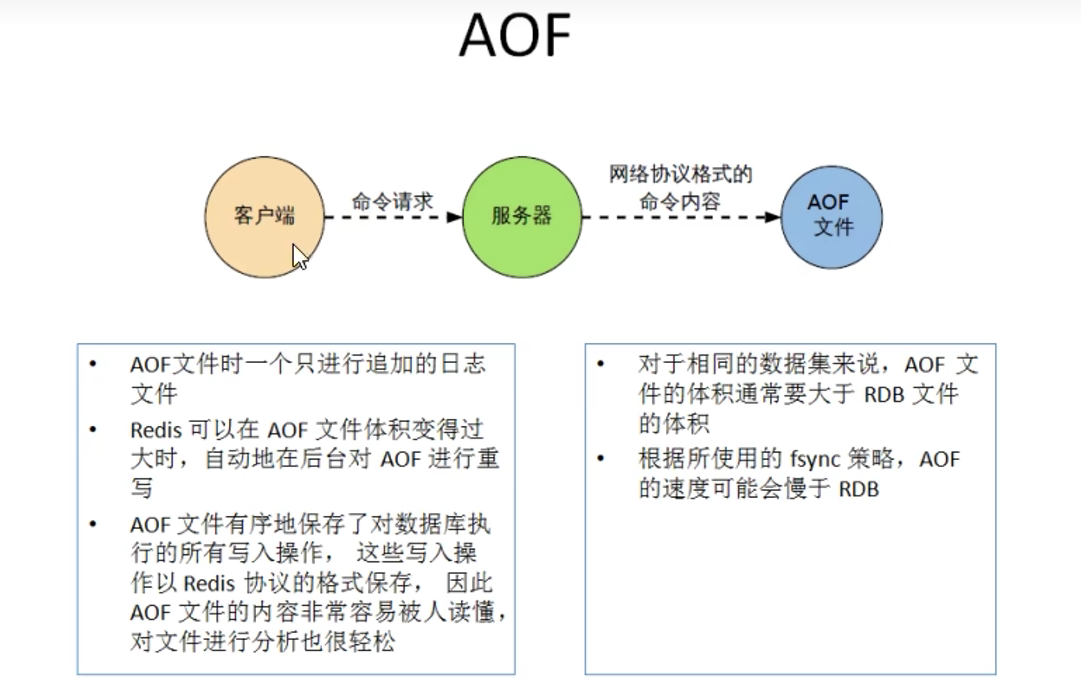
3.2 AOF(Append Only File)
3.2.1 使用原因
因为前面RDB的缺点,可能存在最新数据的丢失,所以引入了aof
3.2.2 基本
记录写操作,保存的是appendonly.aof,
重启的时候,就会把aof文件加载回redis,也即再次执行里面所有的写操作

3.2.3 工作流程

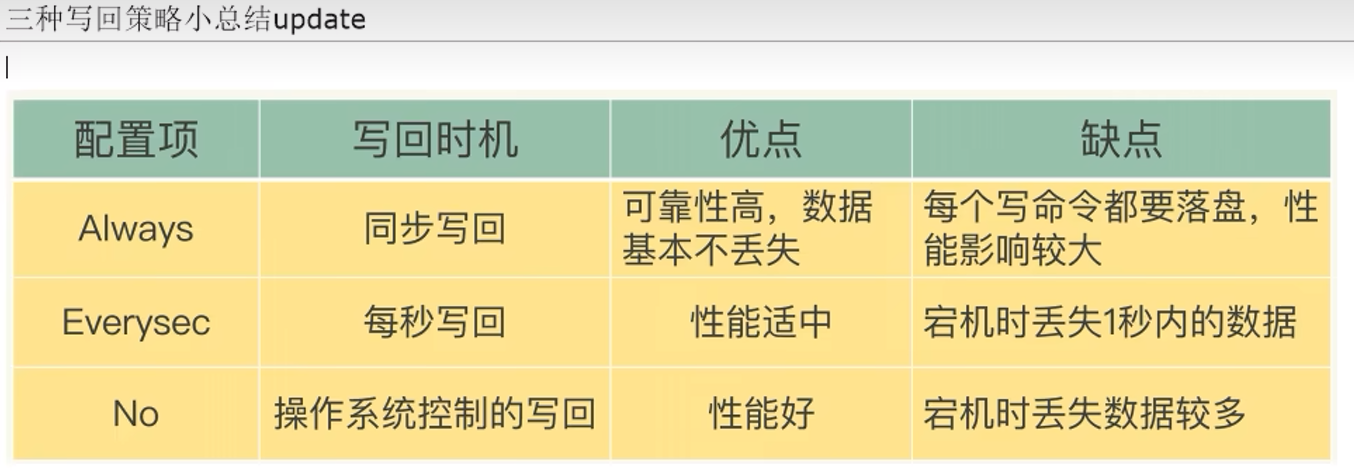
3.2.4 三种写回策略
Always,同步回写,每个写命令执行完后立刻同步地将日志写回磁盘,但是导致频繁地I/O操作
everysec(默认),每秒写回,每个写命令执行完后,先写到aof文件的内存缓冲区,
每隔1秒把缓冲区的内容写入磁盘
no,由操作系统控制,每个写命令执行完后,只是先把日志写到AOF文件的内存缓冲区,
由操作系统决定何时将缓存区的内容写回磁盘
3.2.5 AOF功能配置
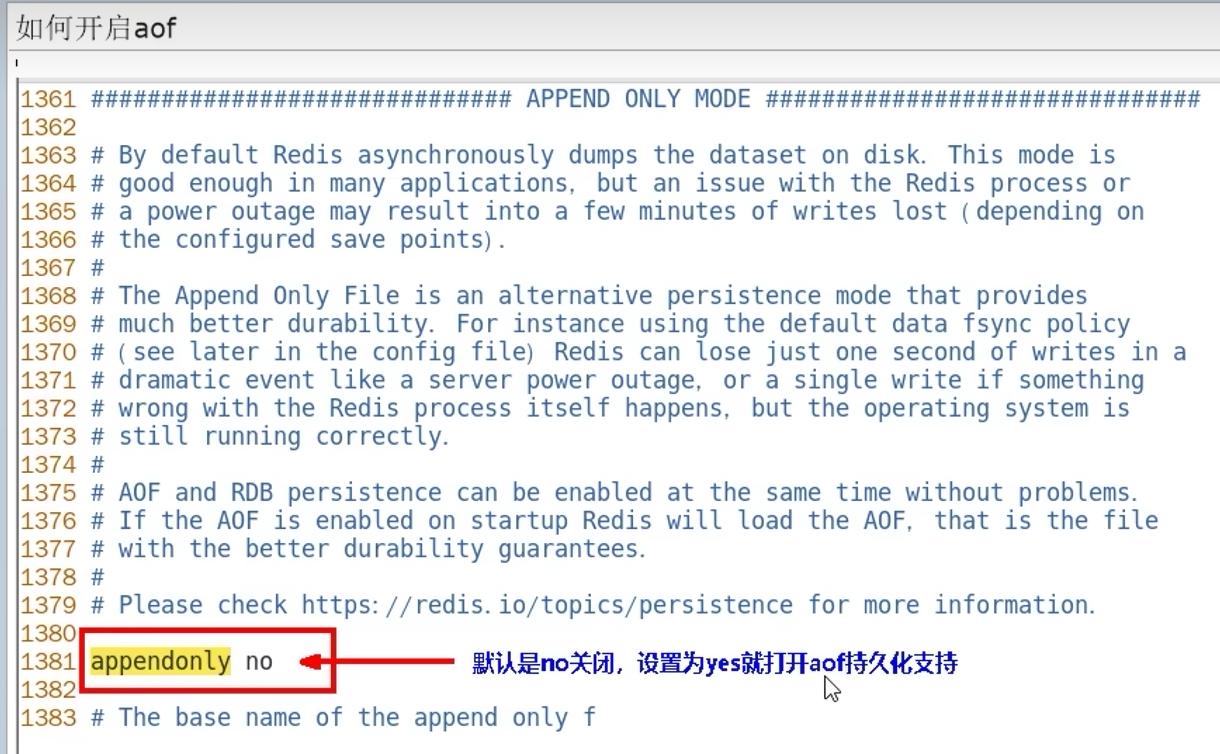
开启AOF
aof保存路径

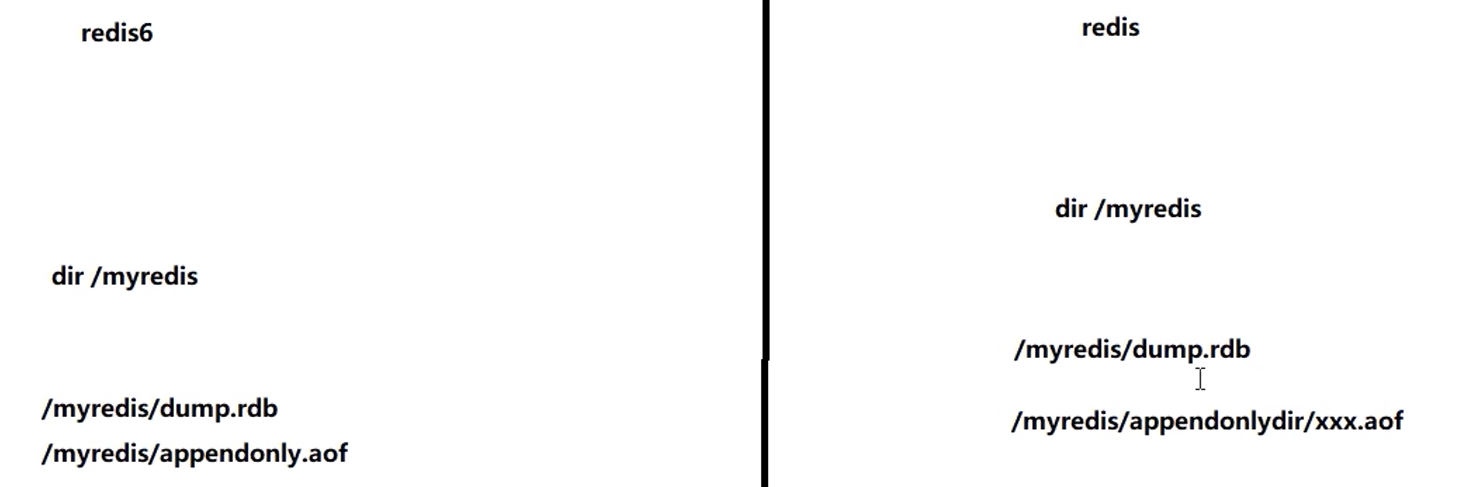
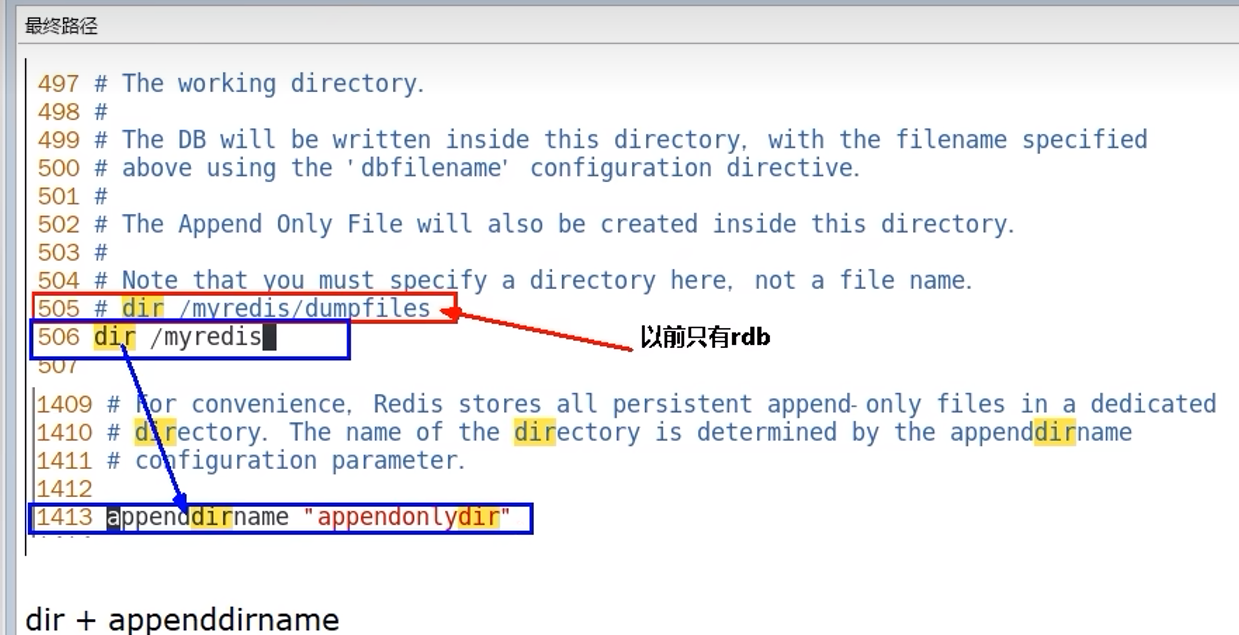
aof保存名称

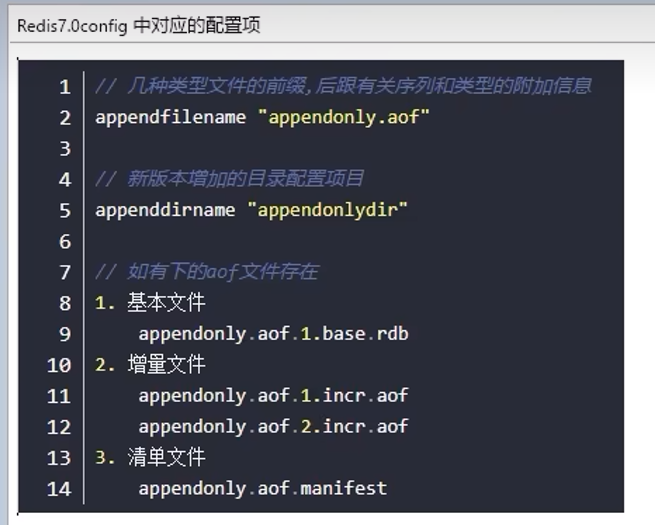
3.2.6 AOF恢复
模拟正常恢复:写入 --> 保存后复制文件备份成bak --> shutdown
-->删除rdb和appendonlydir文件 --> 从bak复制appendonlydir --> 重启
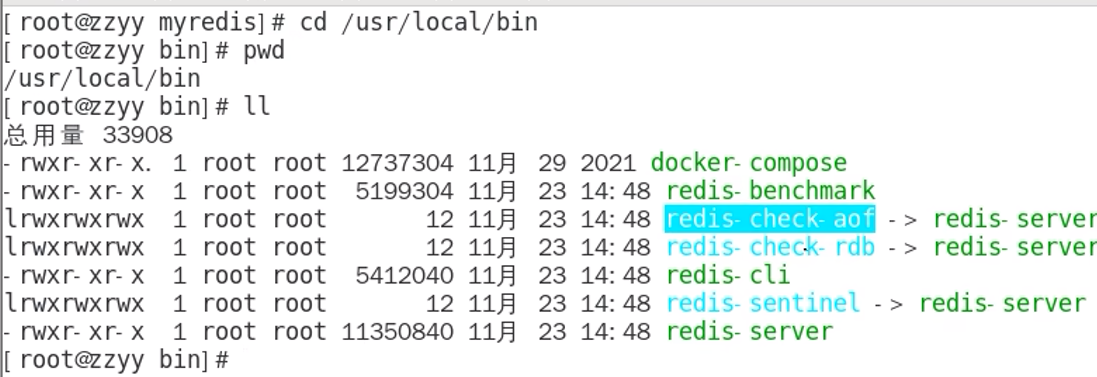
异常恢复:下图的这个来修复incr文件
执行redis-check-aof --fix,必须加上--fix
修复后,会清空掉不符合语法规则的部分
3.2.7 AOF优缺点
使用everysec时,最多丢失一秒的数据




#### 3.2.8 AOF重写
aof文件会不断增大,恢复的时候也越来越慢,为了减少其大小,为其瘦身,使用aof重写
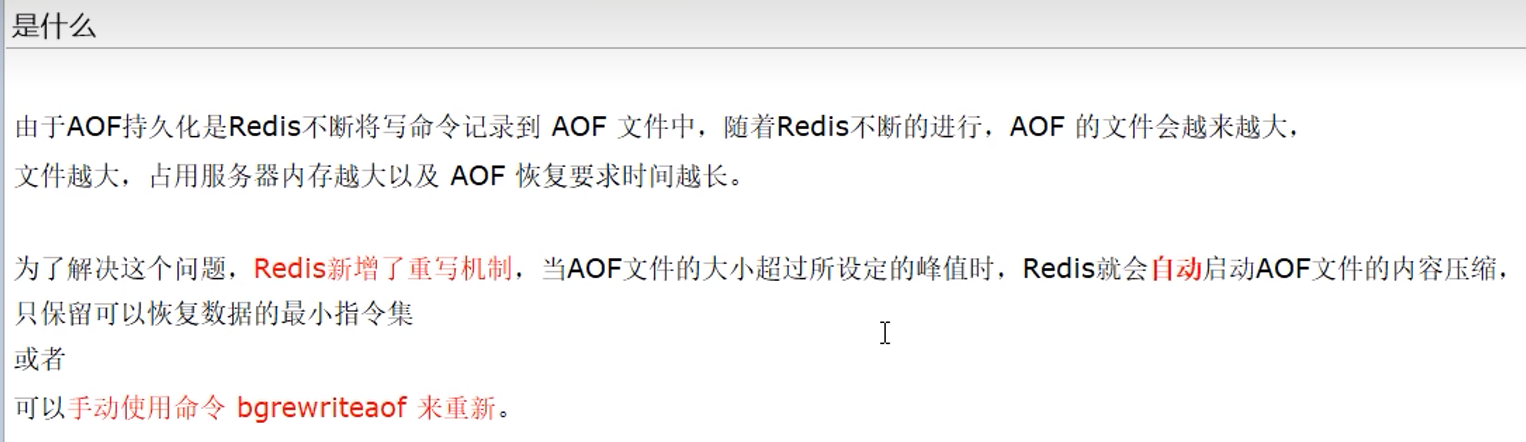


aof重写举例
配置

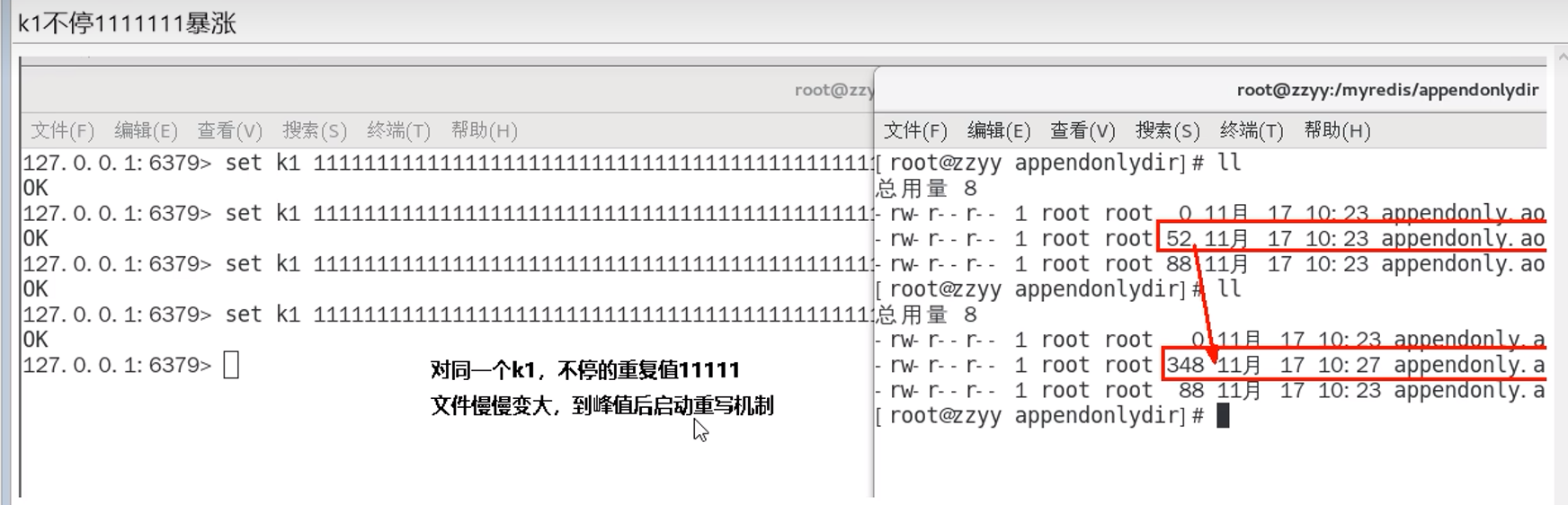
重写案例
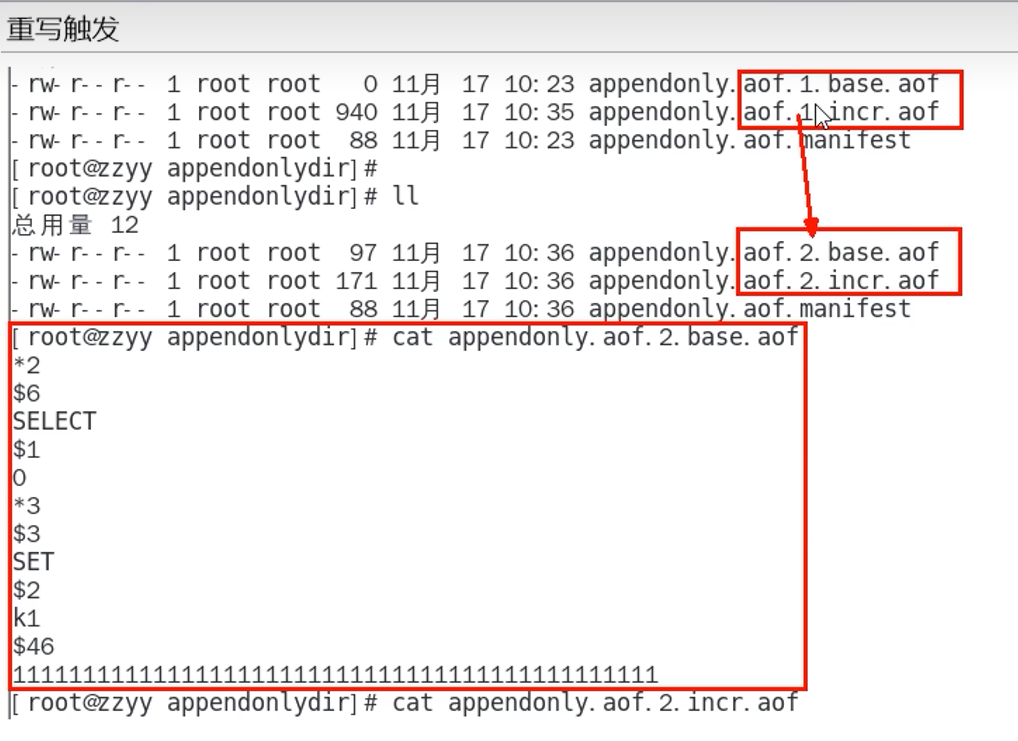
重写总结

重写原理
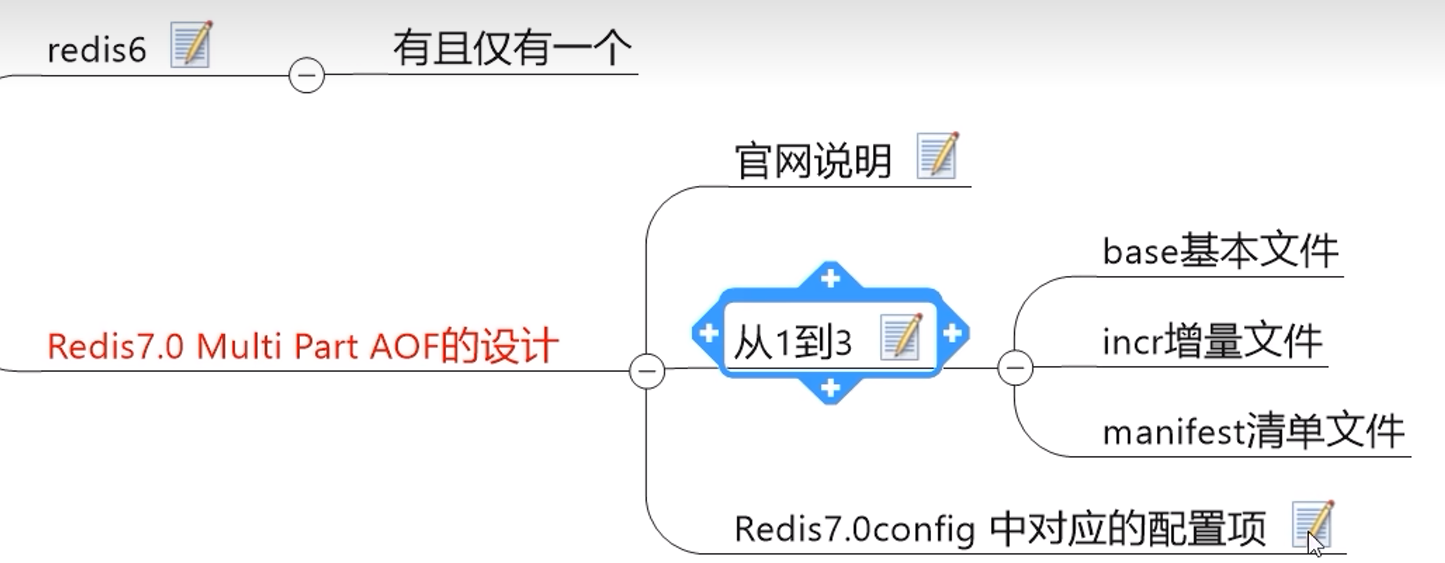
Redis >= 7.0
- Redis forks,所以现在我们有一个子进程和一个父进程。
- 子进程开始在临时文件中写入新的基本AOF(new base)。
- 父进程打开一个新的增量AOF文件(new incr)以继续写入更新。如果重写失败,旧的基文件(old base)和增量文件(old incr)(如果有的话)加上这个新打开的增量文件(new incr)代表完整的更新数据集,所以我们是安全的。
- 当子进程重写完基本文件后,父进程获得一个信号,并使用新打开的增量文件(new incr)和子进程生成的基本文件(new base)构建一个临时清单,并将其持久化。
- 现在,Redis对清单文件进行原子交换,以便AOF重写的结果生效。Redis还会清理旧的基本文件和任何未使用的增量文件。
Redis < 7.0
- Redis forks,所以现在我们有一个子进程和一个父进程。
- 子进程开始在临时文件中写入新的AOF(重写)。
- 父进程在内存缓冲区中累积所有新更改(但同时它将新更改写入旧的AOF文件,因此如果重写失败,我们是安全的)。
- 当子进程重写完文件后,父进程获得一个信号,并将内存缓冲区(新的更改)附加到子进程生成的文件(重写后的AOF)的末尾。
- 现在Redis自动将新文件重命名为旧文件,并开始将新数据附加到新文件中。
3.2.9 AOF小结


3.3 RDB + AOF混合持久化
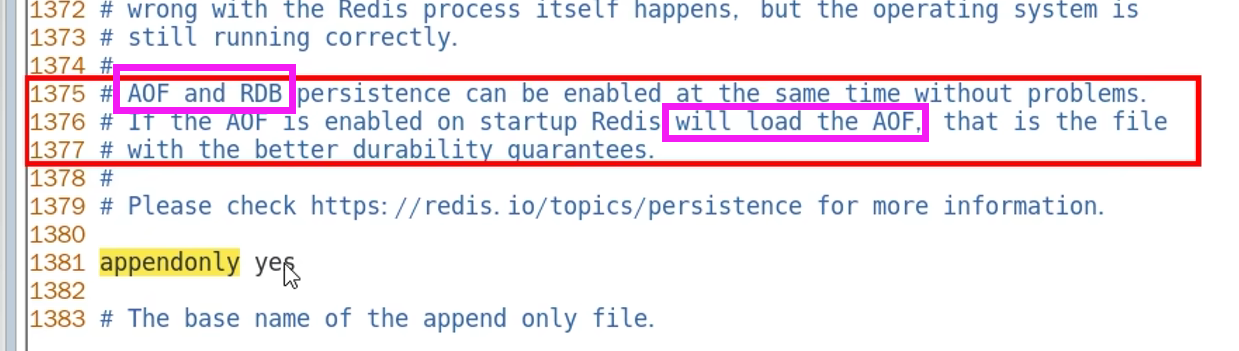
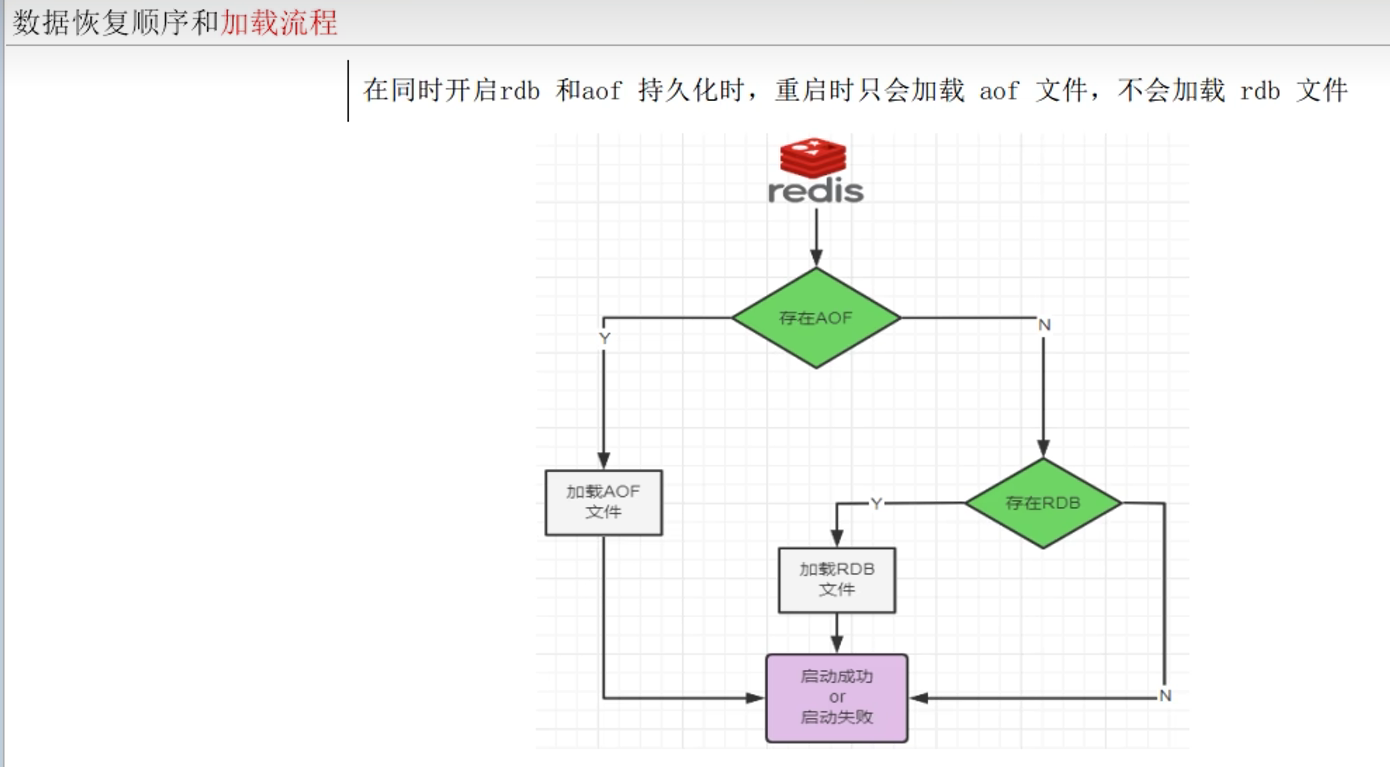
3.3.1 AOF优先
同时生效时,AOF优先
RDB:隔一段时间存储快照
AOF:记录写入操作
3.3.2 为什么AOF优先
因为:通常情况下,AOF保存的文件更加完整,最多丢失一秒的数据(everysec)
而RDB可能缺少更多的数据
3.3.3 为什么不只使用AOF
因为:RDB更适合于备份数据库,而AOF在不断变化不好备份,大数据量时RDB能更快加载
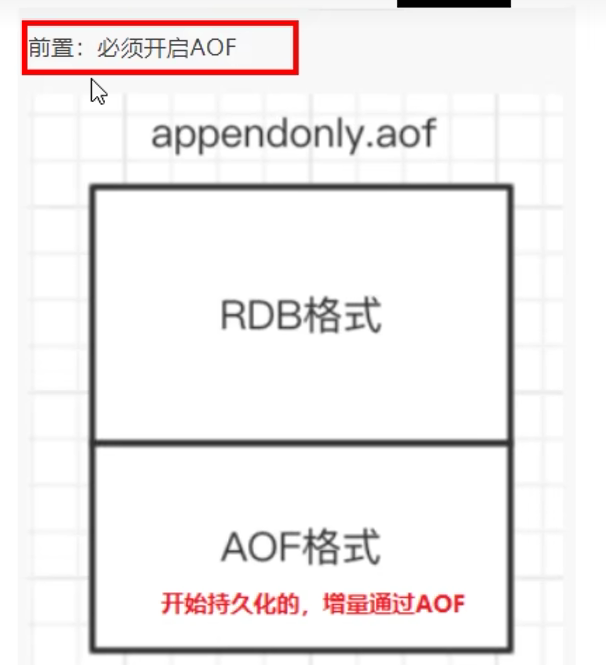
3.3.4 混合使用


3.4 纯缓存模式(关闭持久化)
为了专注于高性能的缓存服务,高速缓存
关闭持久化,即同时关闭RDB和AOF
这个禁用只是禁用了自动触发

4. Redis事务
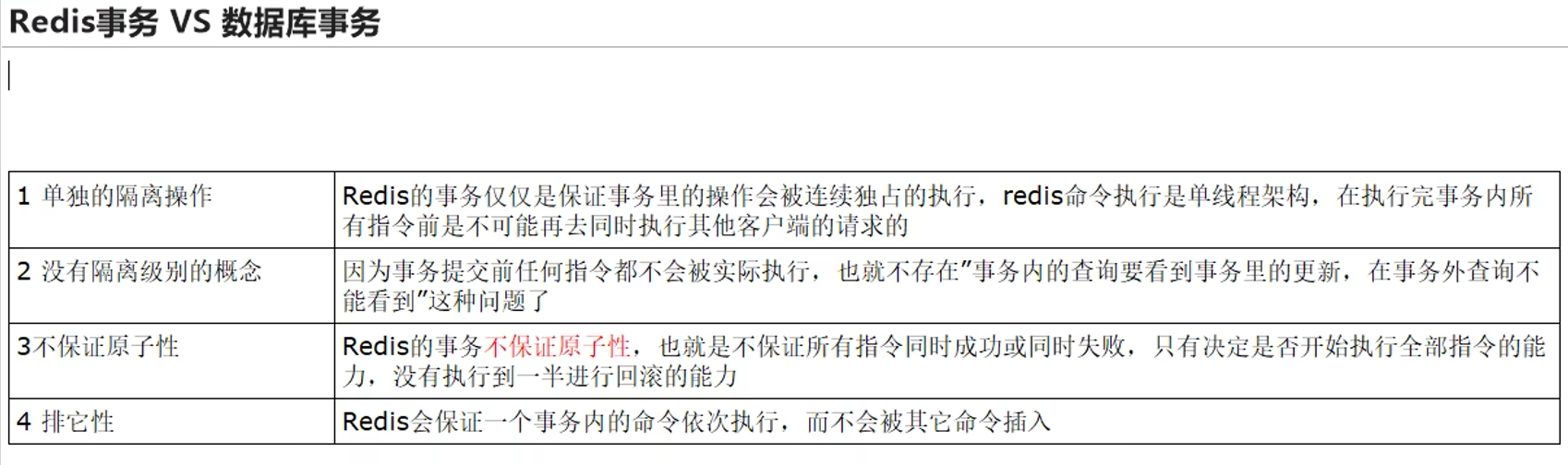
4.1 是什么
回顾——数据库事务:一次在跟数据库的连接会话当中,所有执行的sql,要么一起成功,要么一起失败
Redis事务:
总的来说:就是一串操作命令队列,一次性执行

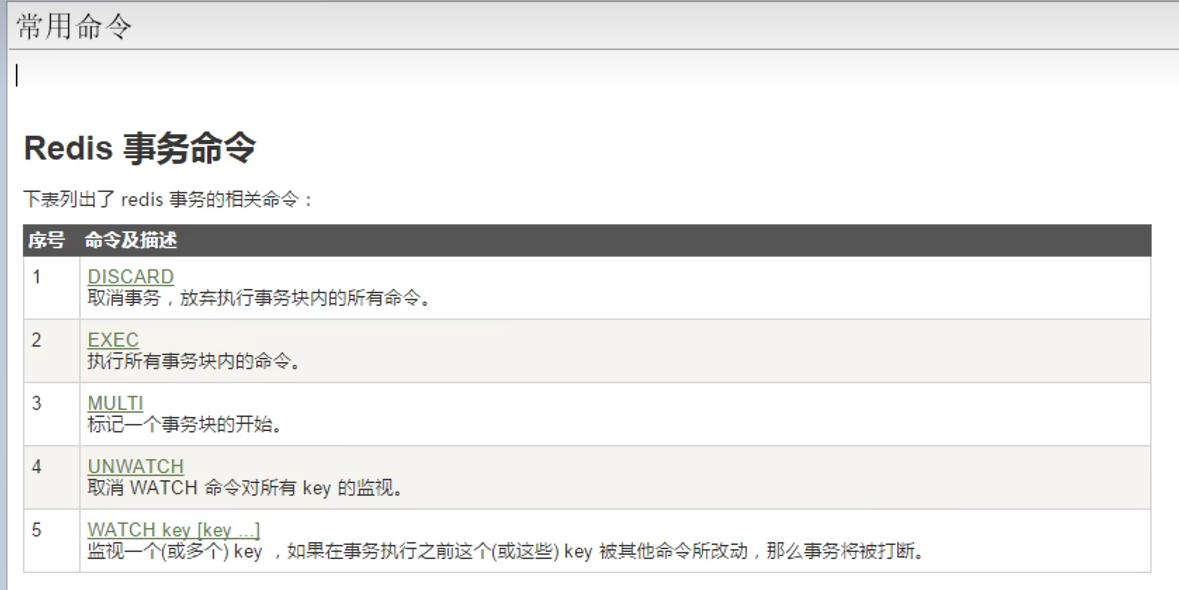
4.2 使用
注意事项:
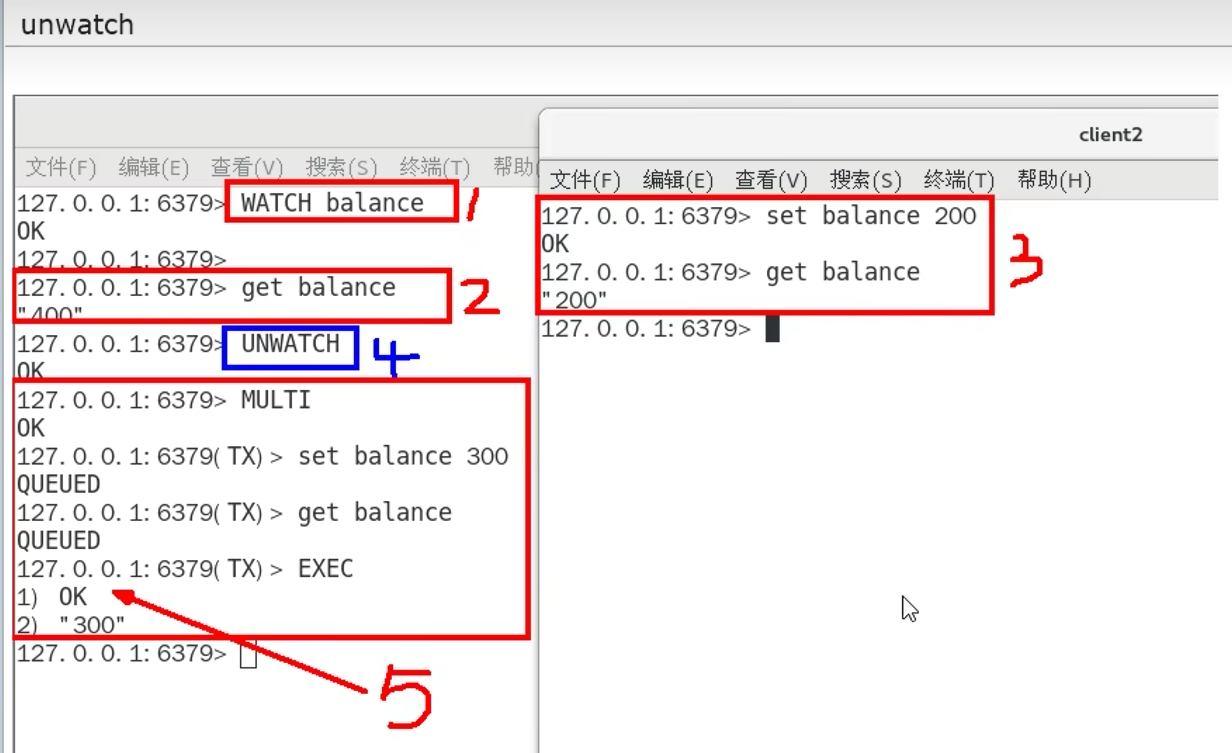
watch监控只在下一次事务有效,当discard或者exec之后,watch失效
watch监控是乐观锁,watch监控后,会记录当前值,exec的时候,在执行操作队列(Redis事务)之前,会先进行判断watch的值是否被修改,被修改则整个操作队列都不执行
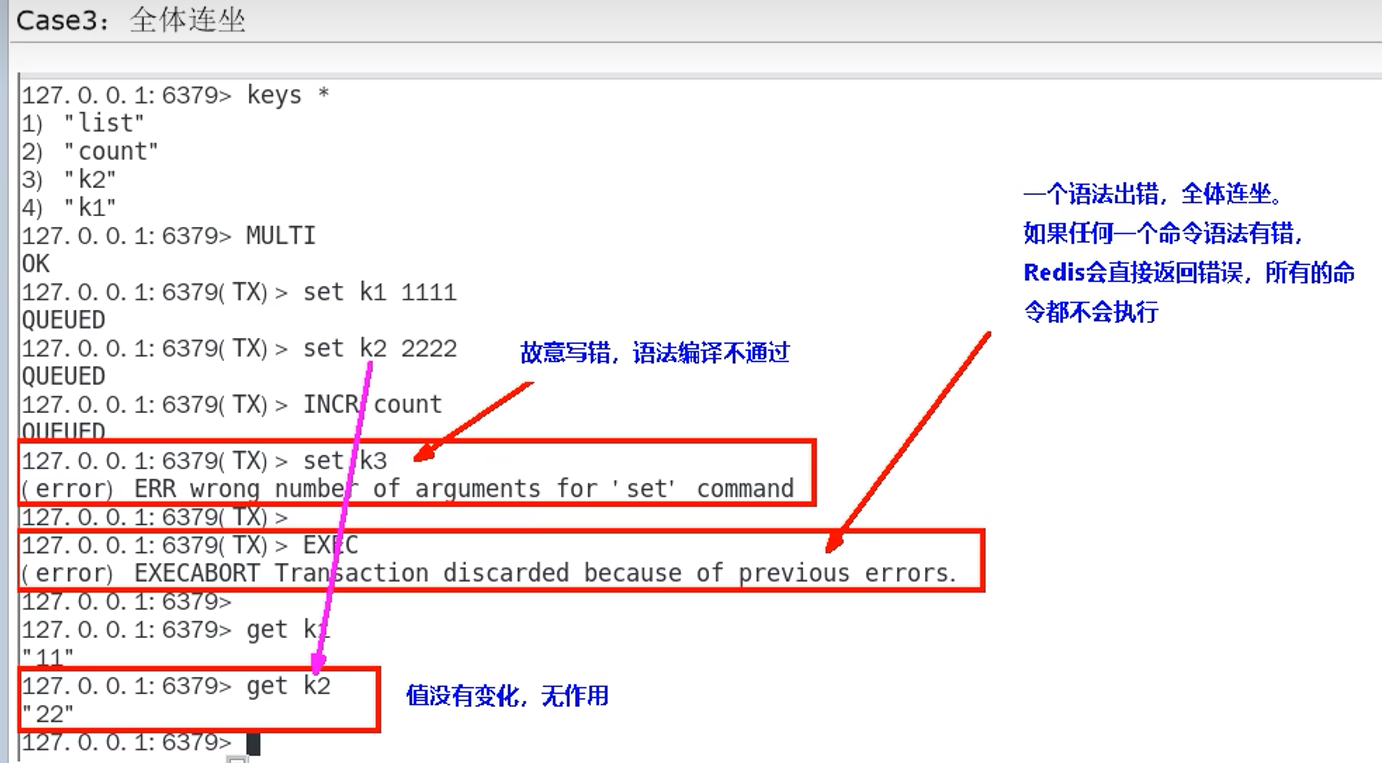
Redis事务,会检查语法,一旦语法编译不通过,整个队列的命令都不执行
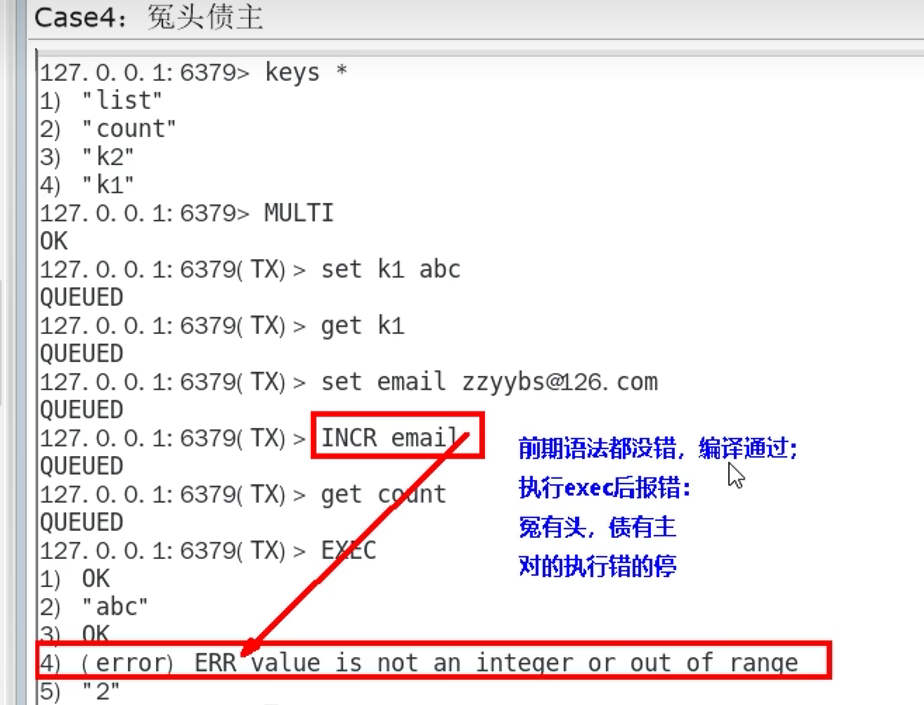
Redis事务,如果语法正确,但执行时发现命令有错误,只有错的命令不执行,不会停下,后面的只要是正确的,都要执行






5. Redis管道
5.1引出

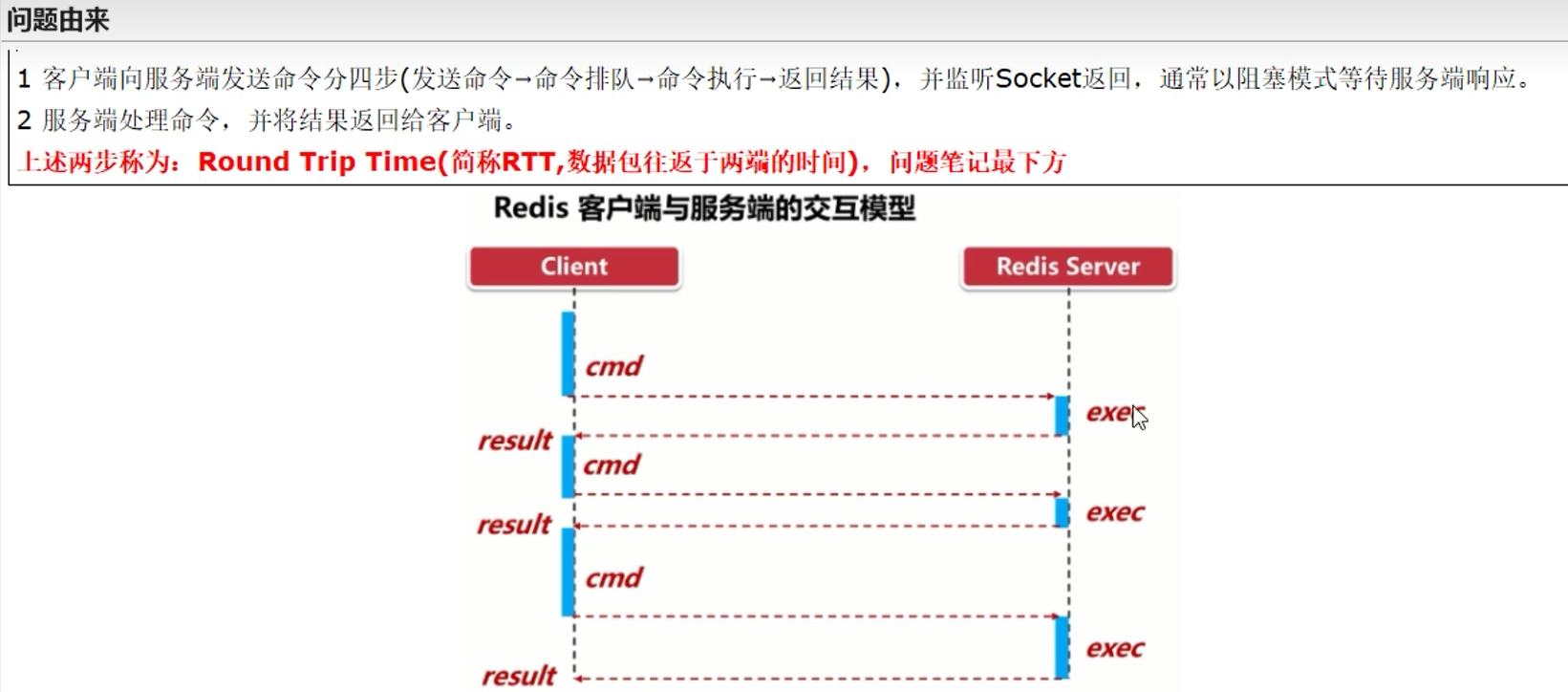

因此我们需要批处理这样的操作,类似于mset这样的操作,所以使用了管道的概念
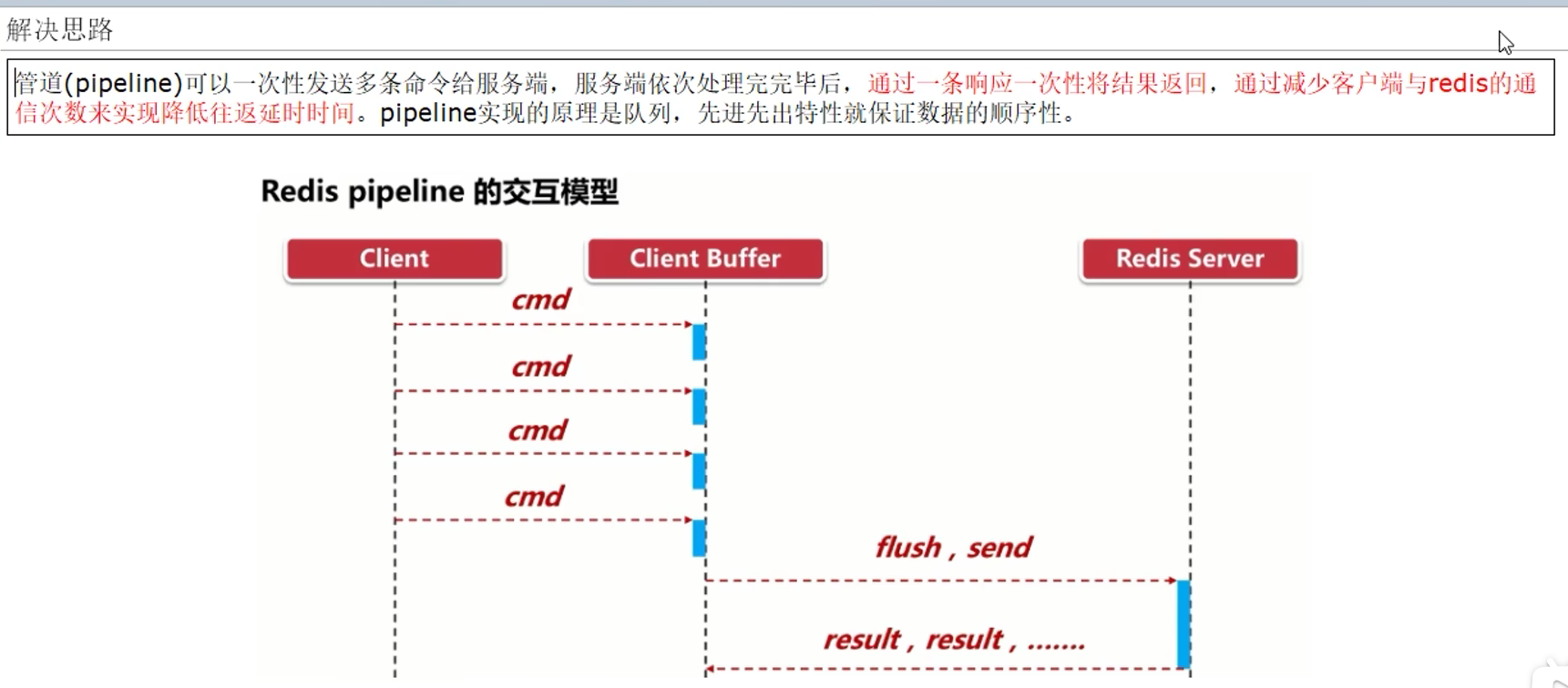
5.2 是什么

5.3 使用
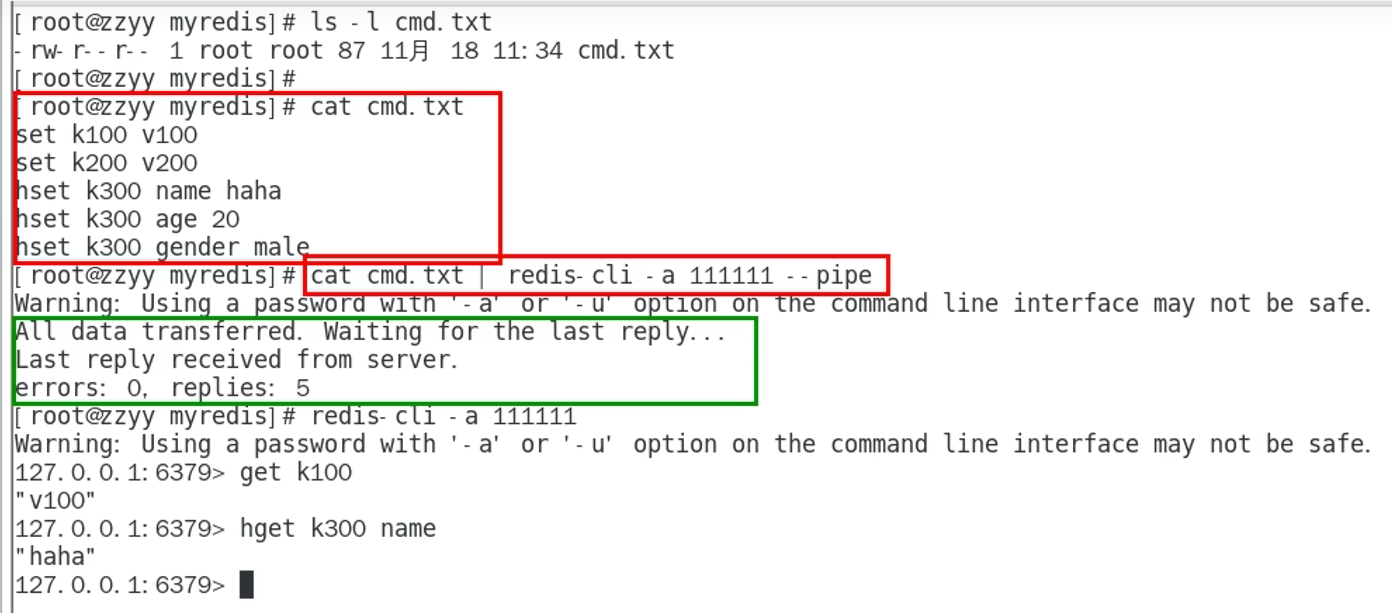
5.4 总结
Pipeline VS 原生批量命令:

Pipeline VS Redis事务:
Redis是不保证原子性(比如编译正确,但执行错误的时候)

Pipeline 注意事项:

6. Redis发布订阅(了解)
6.1 定义



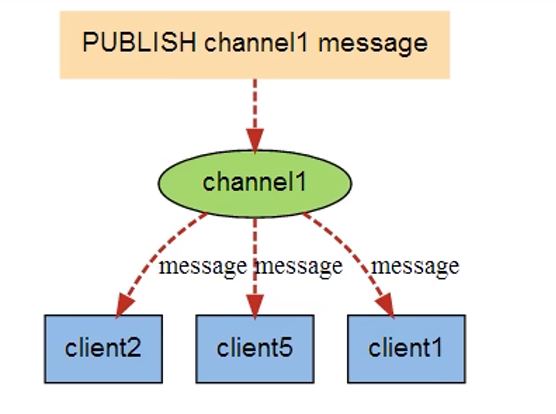

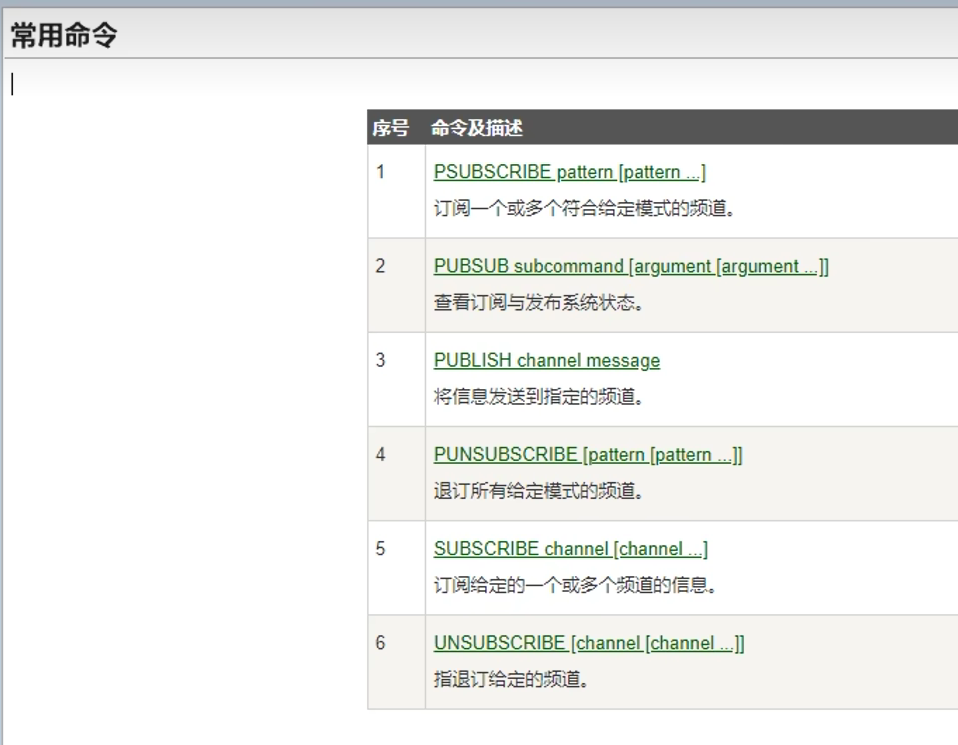
6.2 命令

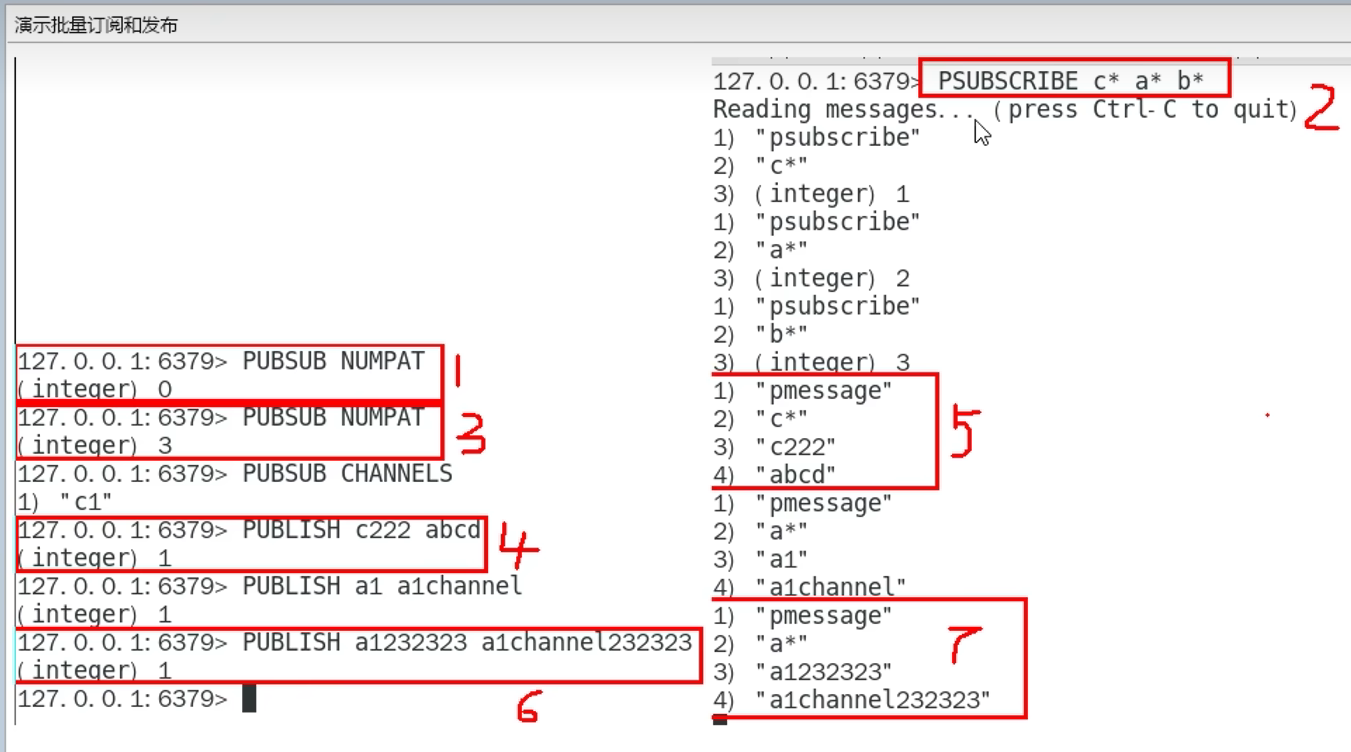

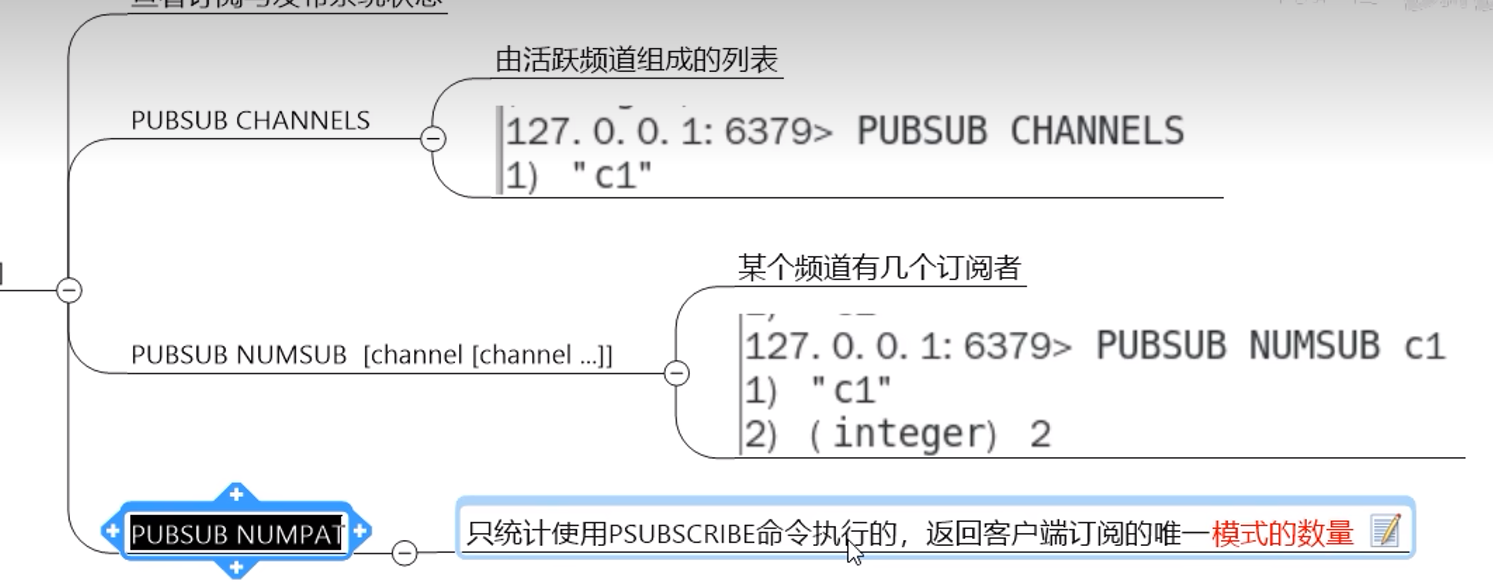
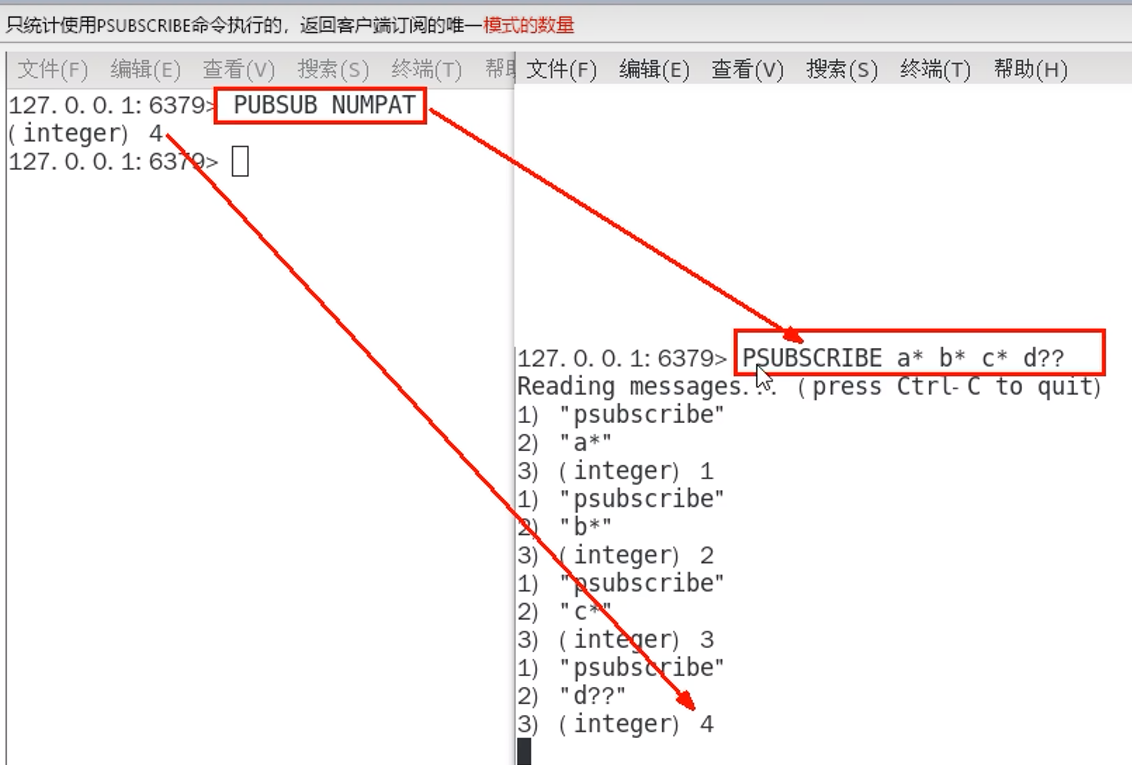
6.3 缺点


7. Redis复制
7.1 是什么

7.2 功能
读写分离:写找主机,读找从机
7.3 使用理论



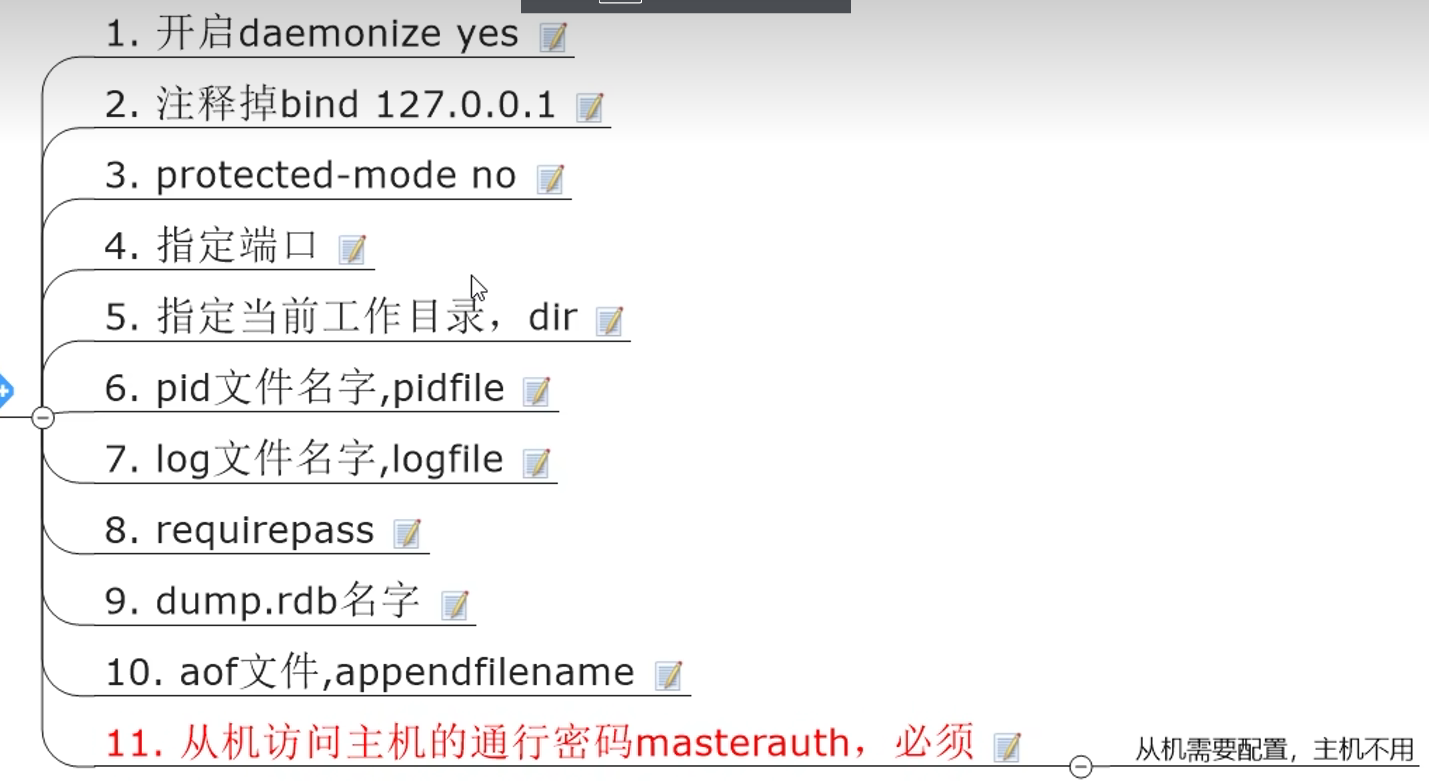
7.4 使用
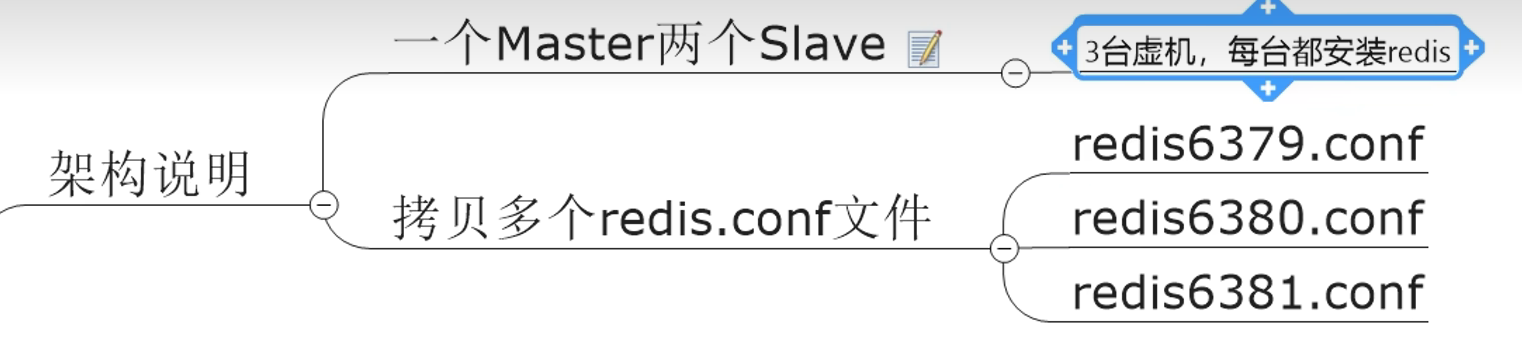
7.5 主从复制
7.5.1 一主二从
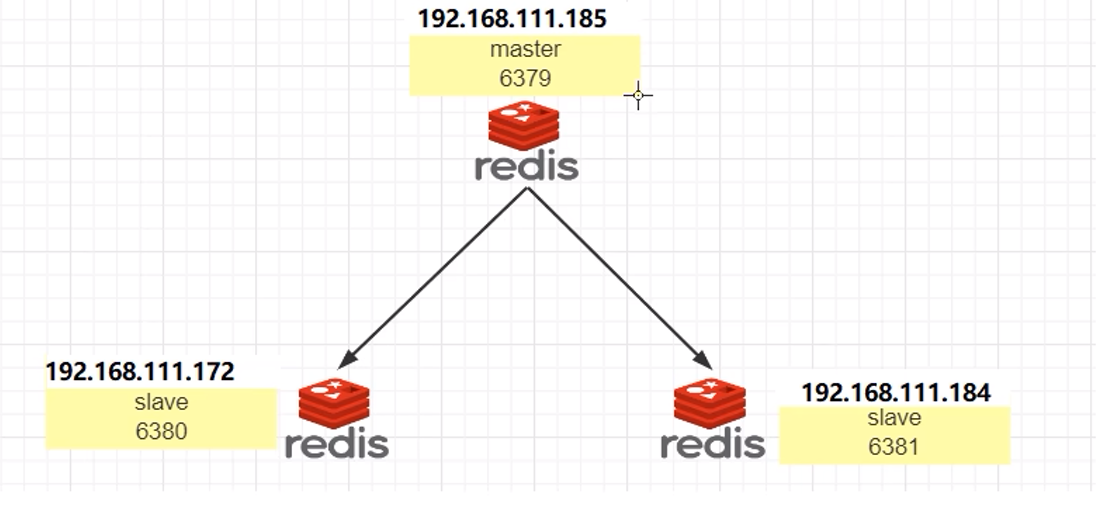
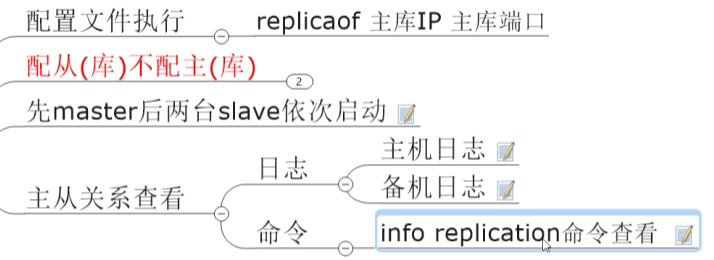
读写分离,从机不允许写入
在主机写入,从机读取
主机写入的,从机都会复制到,也就是主从的数据一样
流程:
从机在启动后,会一次性写入主机的数据(覆盖原有数据,完全复制主机数据)
主机收到同步命令后,会在后台保存快照(RDB持久化),并缓存收集到的修改数据集的命令,RDB持久化完成后,master将rdb快照文件和所有缓存的命令发送到所有slave,完成完全同步,slave收到后加载到内存
然后每10秒(默认)保持通信,完成增量复制(批次)
从机如果关机了,在开机的时候会一次性写入主机之前新写入的数据(根据backlog的offset来确定,只会复制其后的数据,类似断点续传),然后继续跟随复制
主机挂掉,从机原地等待,从机数据可以正常使用
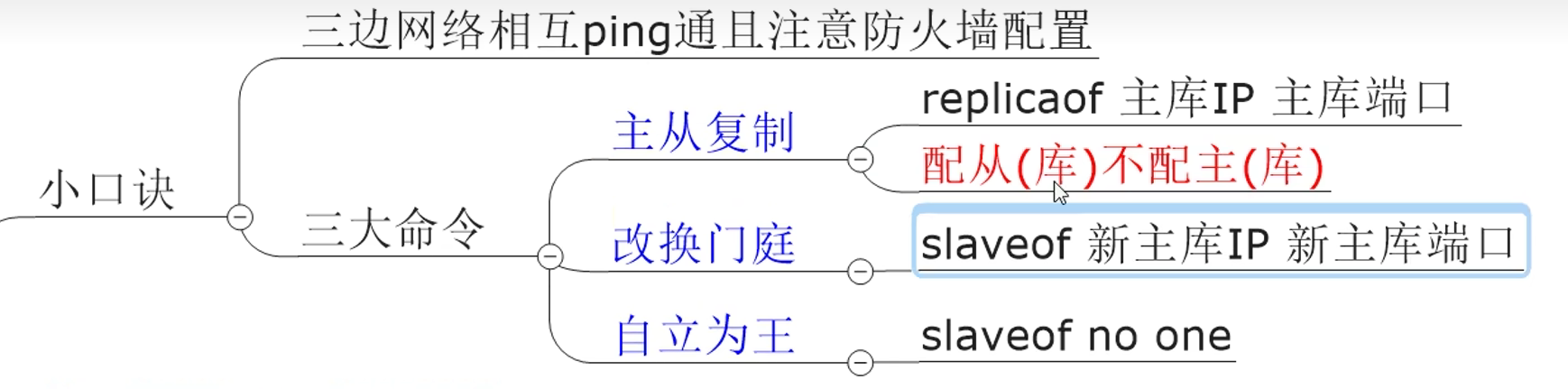
前面是采用配置文件来声明为从机
如果采用命令方式来声明为从机(slaveof),只是临时有效,shutdown之后恢复为master

7.5.2 薪火相传
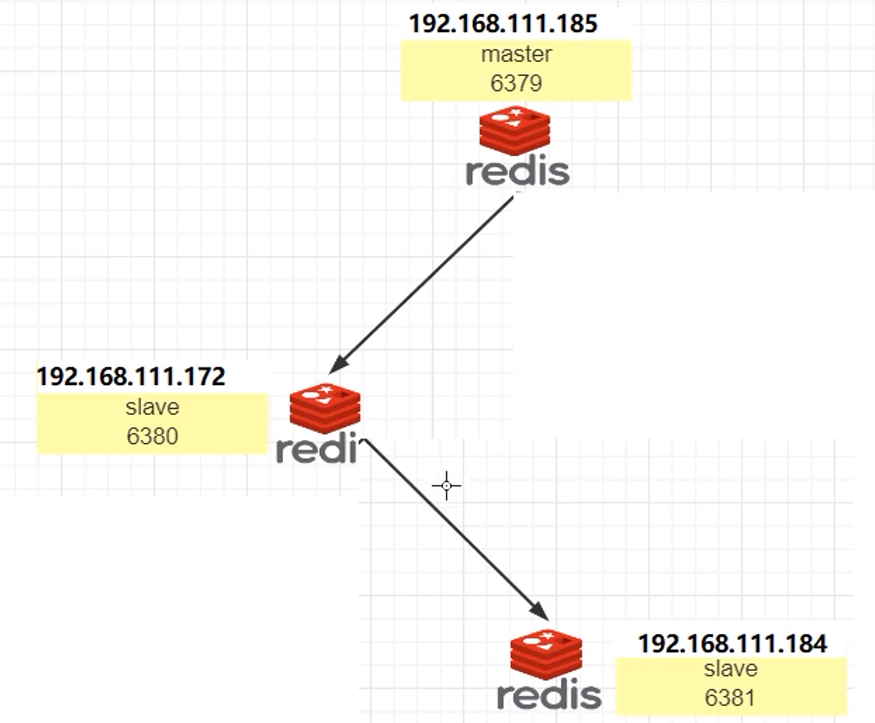

一条链中间的slave仍然是从机,不能写入
7.5.3 反客为主
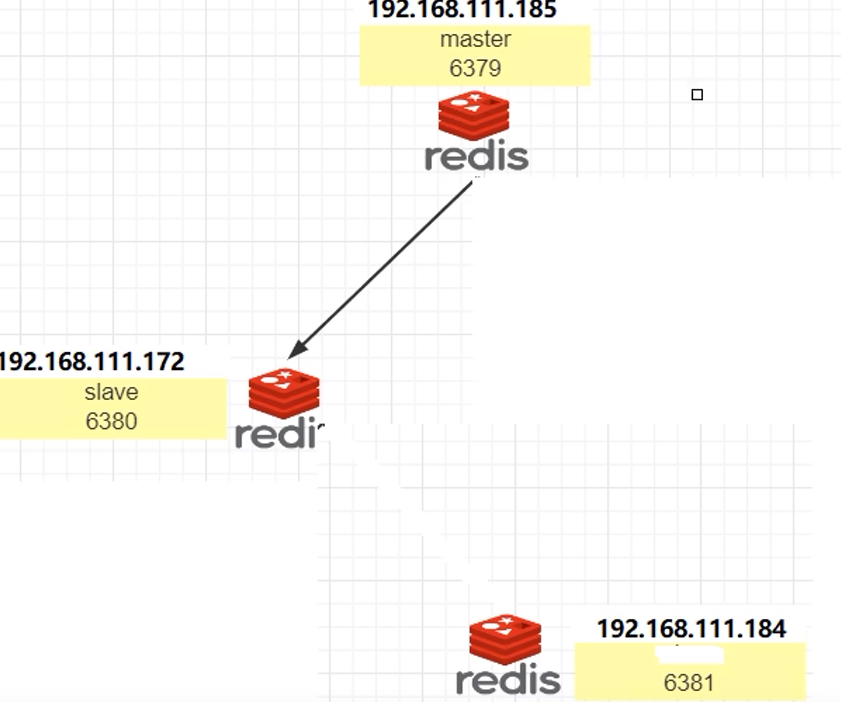

7.5.4 缺点
同步有一定延迟,当系统繁忙时或机器数量多的时候更加严重
主机挂了,从机会等待(导致不能写入,只能读取),只能手动重启
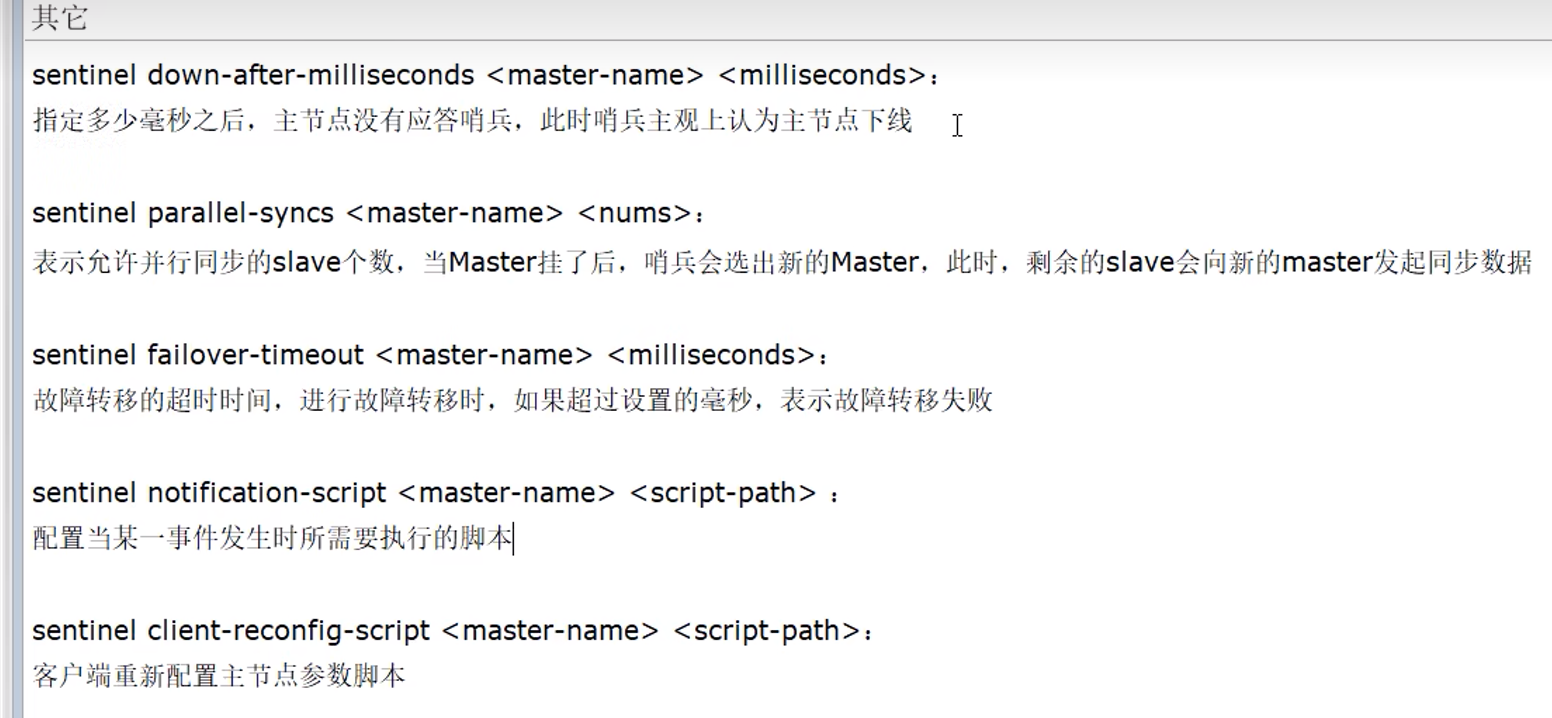
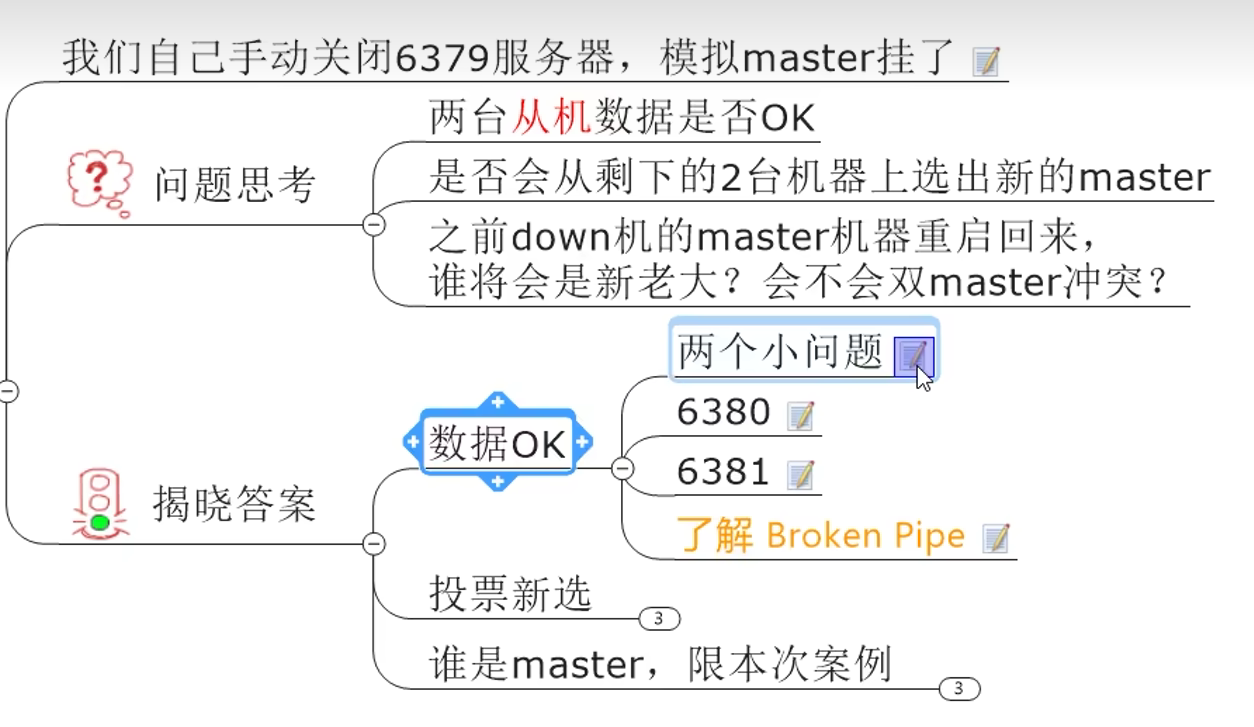
8. Redis哨兵
8.1 理论
监控master主机是否故障,如果故障,按投票数自动将某个从机转为新主机

8.2 实操
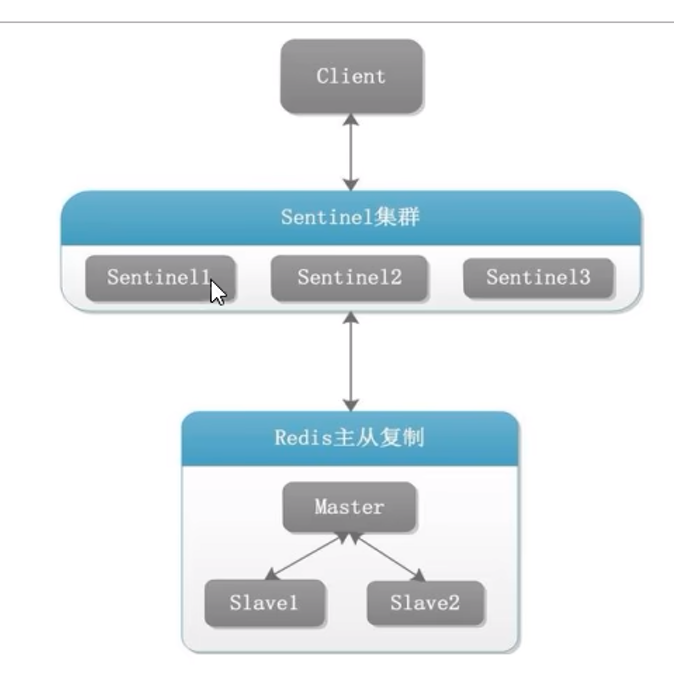
sentinel26379.conf文件:
可以同时监控多个master




再连一次即可
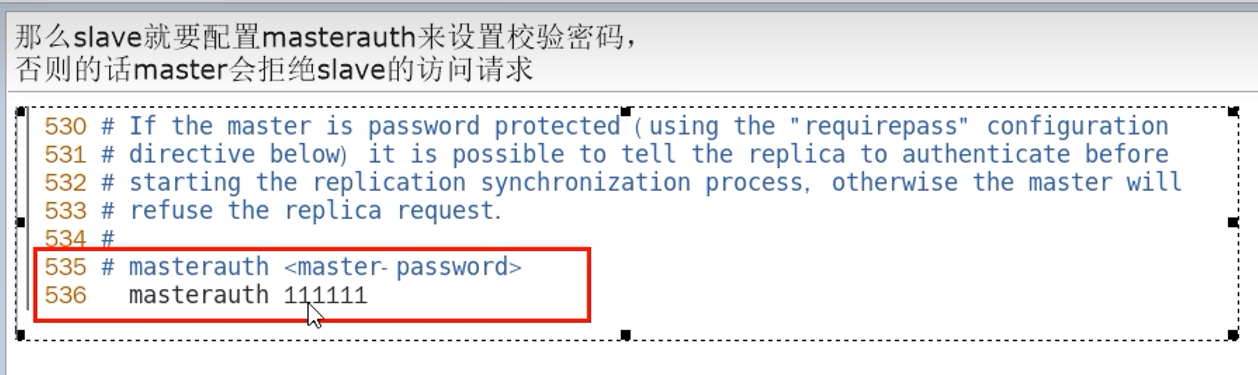
由于主机挂了,会变成从机,所以也要填写masterauth,但是为什么不用填写replicaof,因为后面会自动rewrite,而密码她不知道,所以我们要自己填写(masterauth)


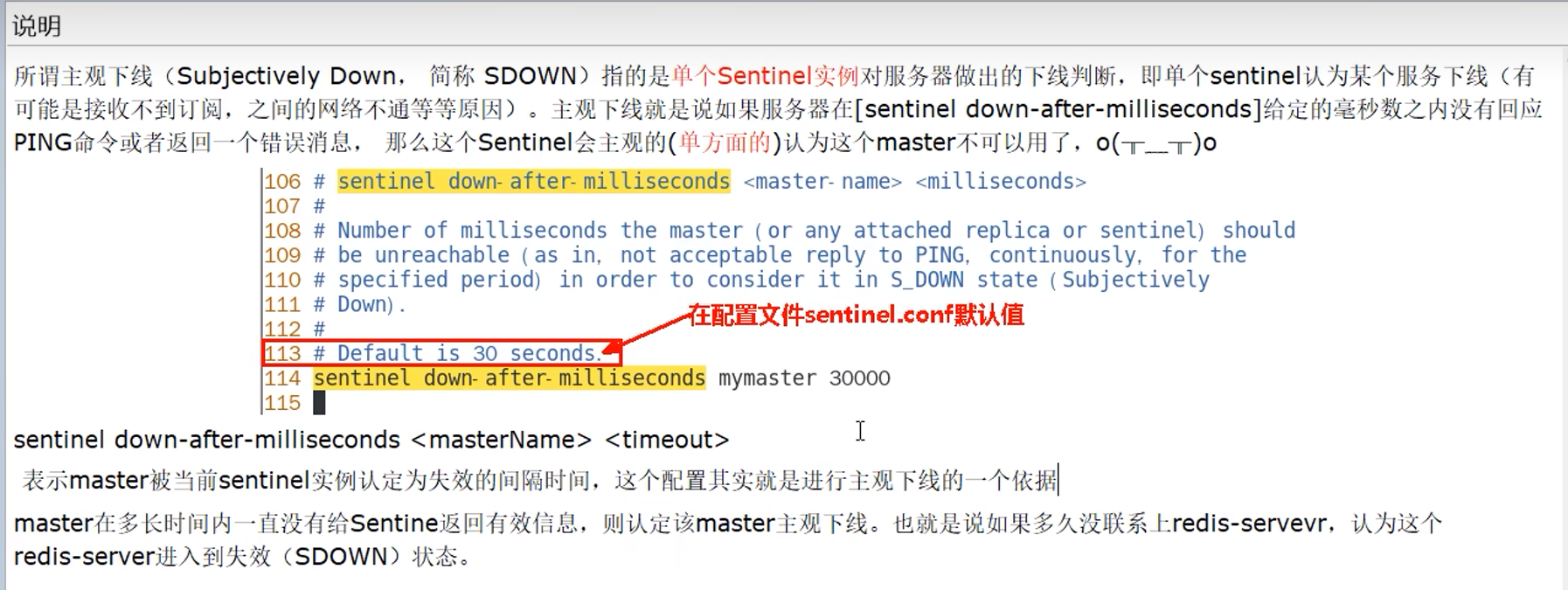
8.3 主观下线(SDown)
即单个哨兵认为,主机挂了
8.4 客观下线(ODown)
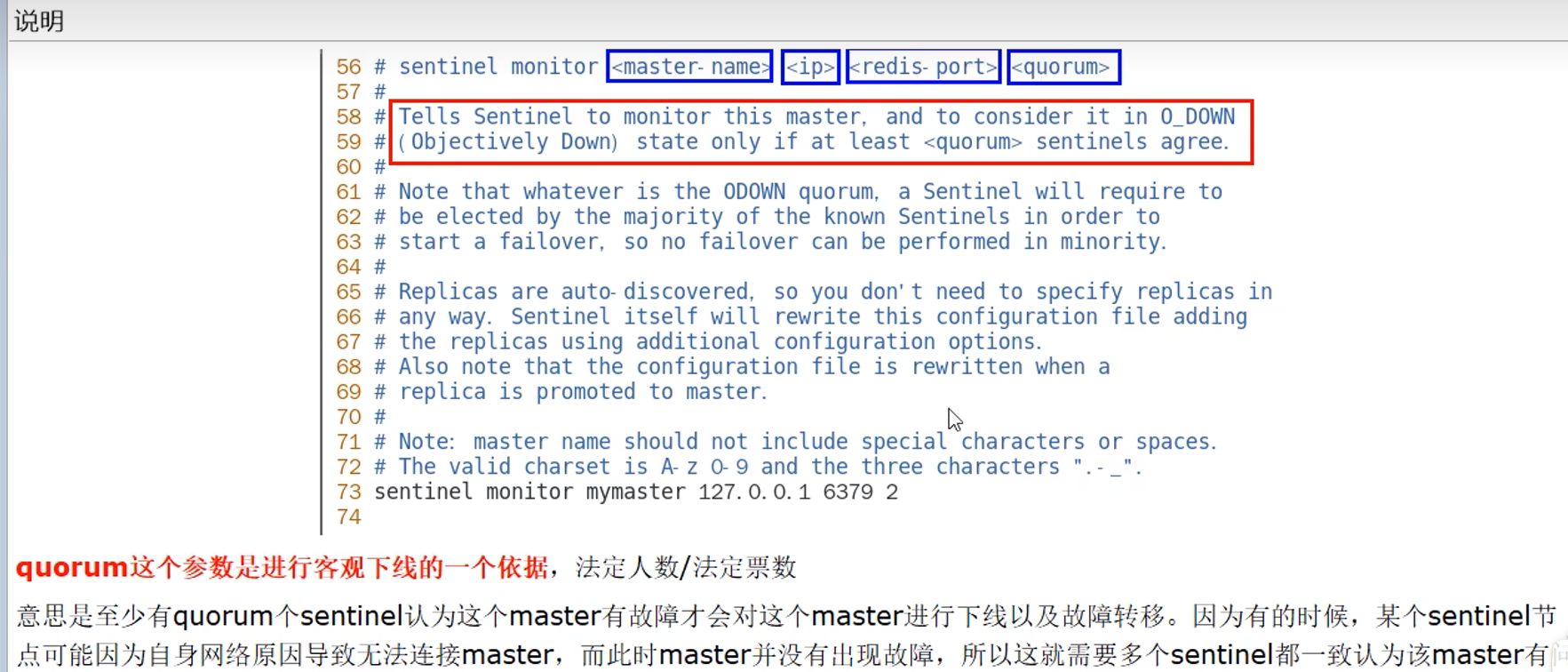
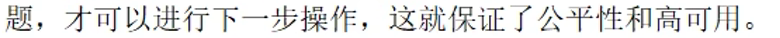
当判断为客观下线后,选出一个哨兵作为leader(由Raft算法完成),由它一个人来完成故障迁移(failover)
8.5 新master的选法
规则:
1. 设置的优先级 最高
1. 复制的offset 最大
1. RUN ID 最小
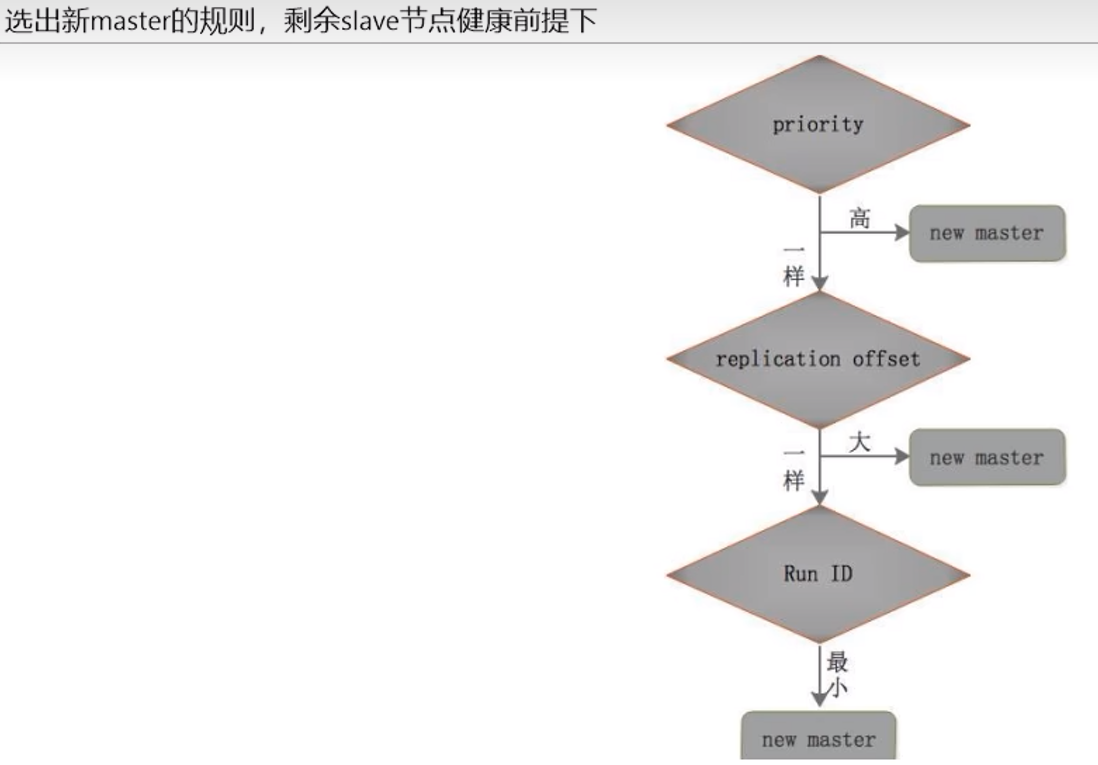


8.6 更换主从关系

对于老的master:

8.7 过程总结

8.8 使用建议

由于更换主从需要时间,这段时间可能导致数据丢失,故引出后面的集群
9. Redis集群
9.1 是什么
原来只有一台master提供写操作,写操作的压力大,现在集群是多个master,数据共享,各自记录分别的数据(通过slot计算),一个挂了,他的从机自动上位变成master

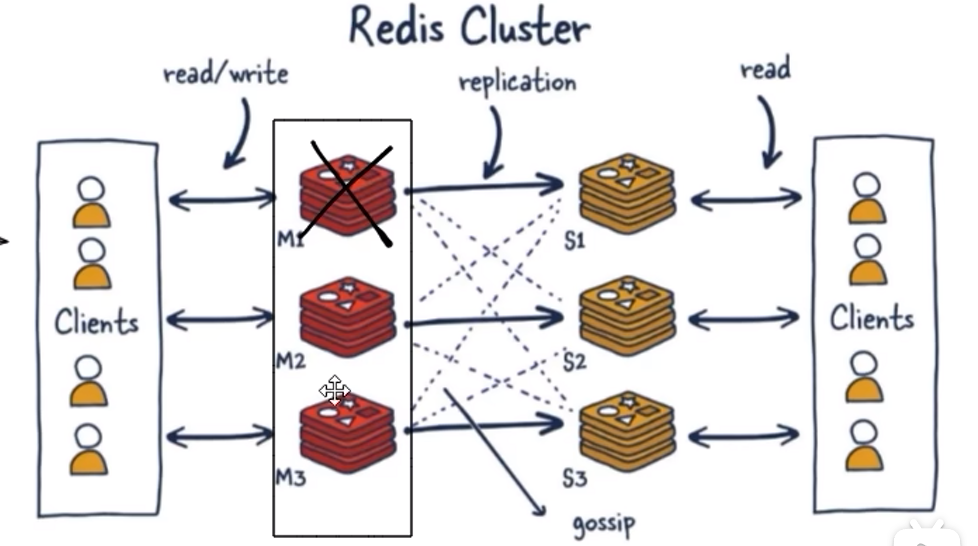

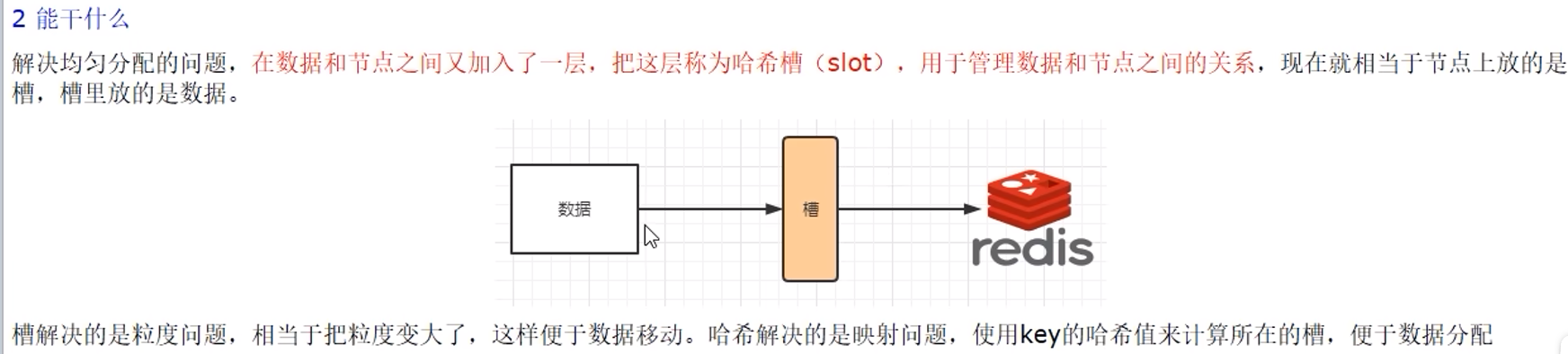
9.2 能干吗

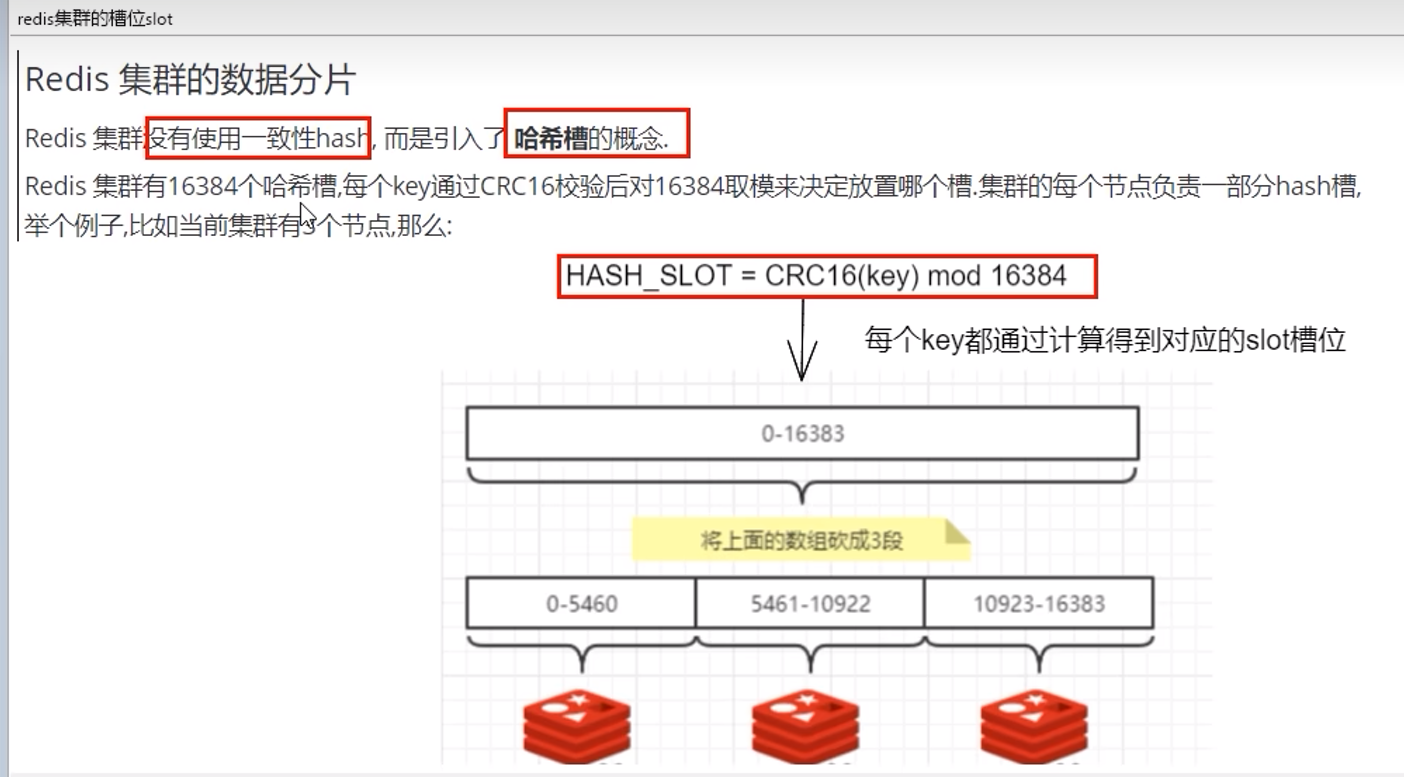
9.3 槽位slot
最多16384个,建议小于1000
多个master会一起分配这16384个slot(分片),每个master都有一定范围的slot
这样,可以通过计算来判断写入操作寻找哪个master

9.4 分片

9.5 槽位和分片的优势

加一台,只需要前面几台匀一些给它,方便扩容,并且重分配时不会停止服务。
9.6 slot槽位映射的3种解决方案
9.6.1 哈希区域分区
直接对N取余,分配到0,1,2...N-1台机器
缺点:
1. 不好扩容,N变化,需要修改映射关系
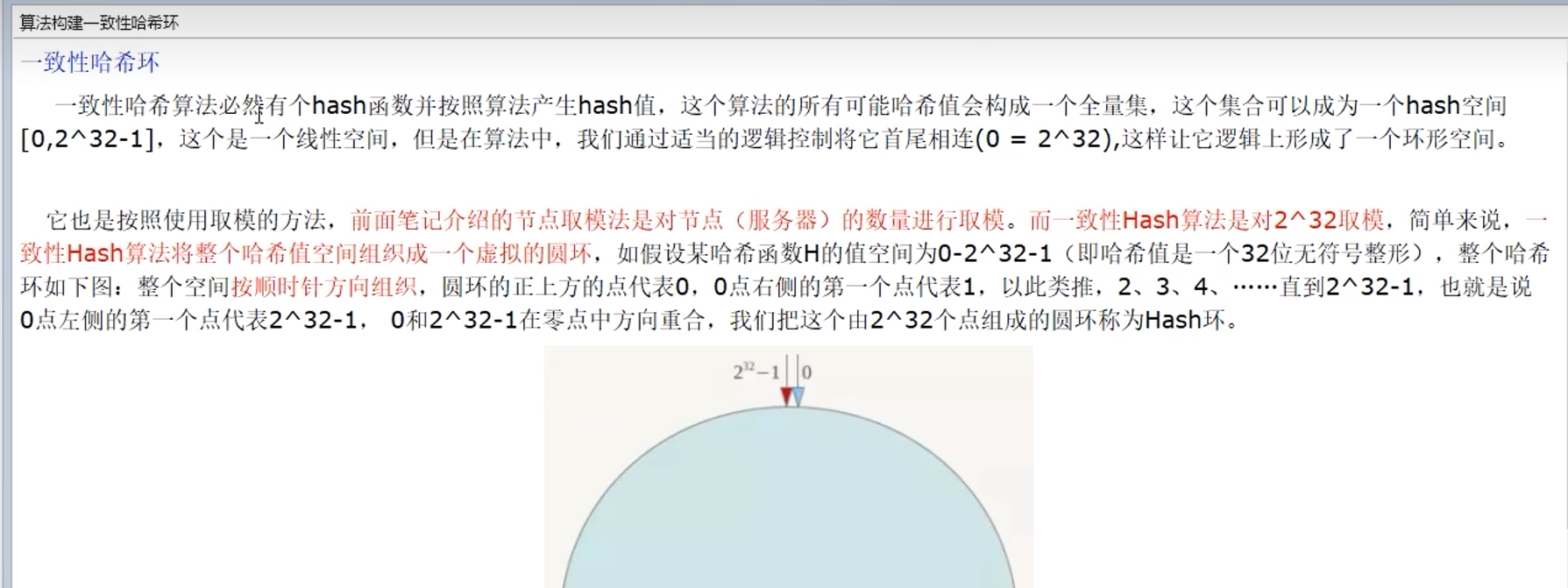
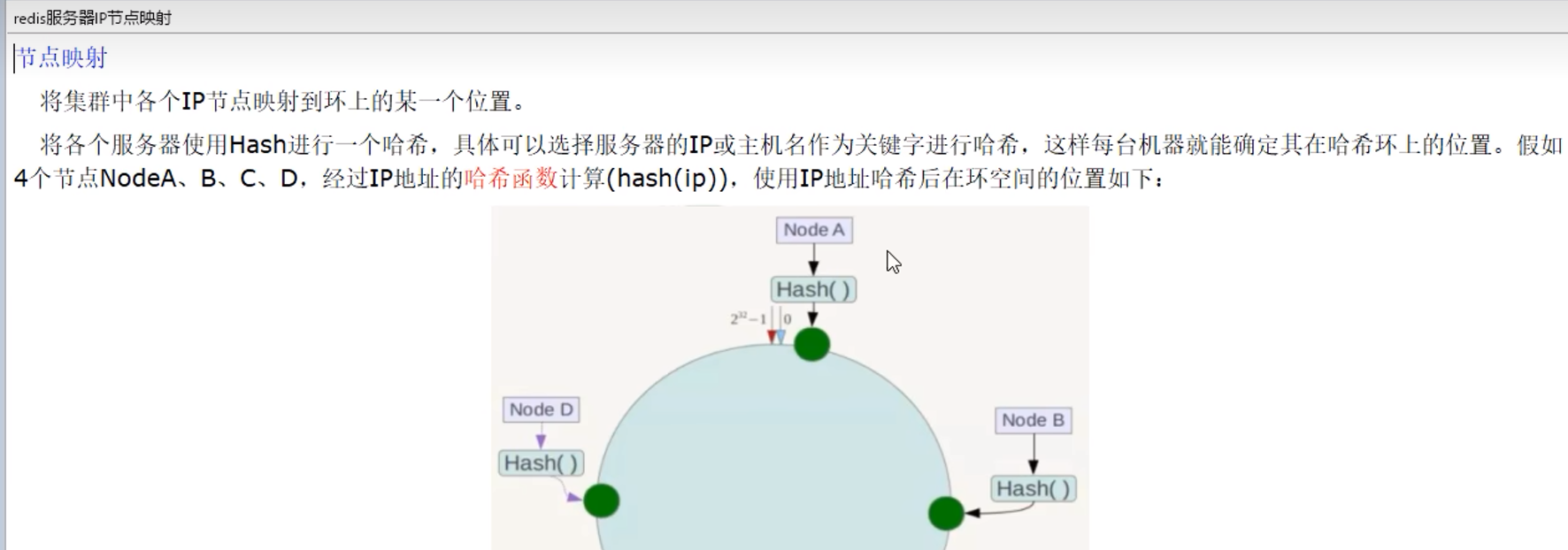
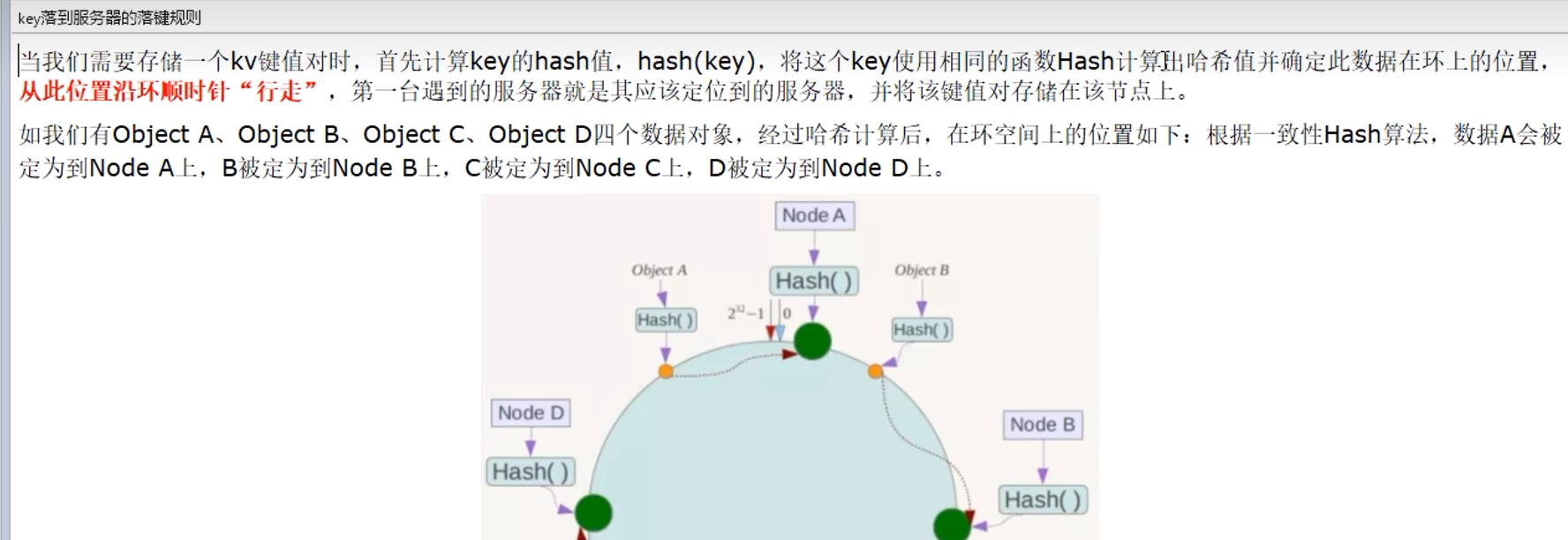
1. 某个或某些机器故障,导致N不确定,不可控 9.6.2 一致性哈希算法分区
步骤:

优点:
容错性、扩展性

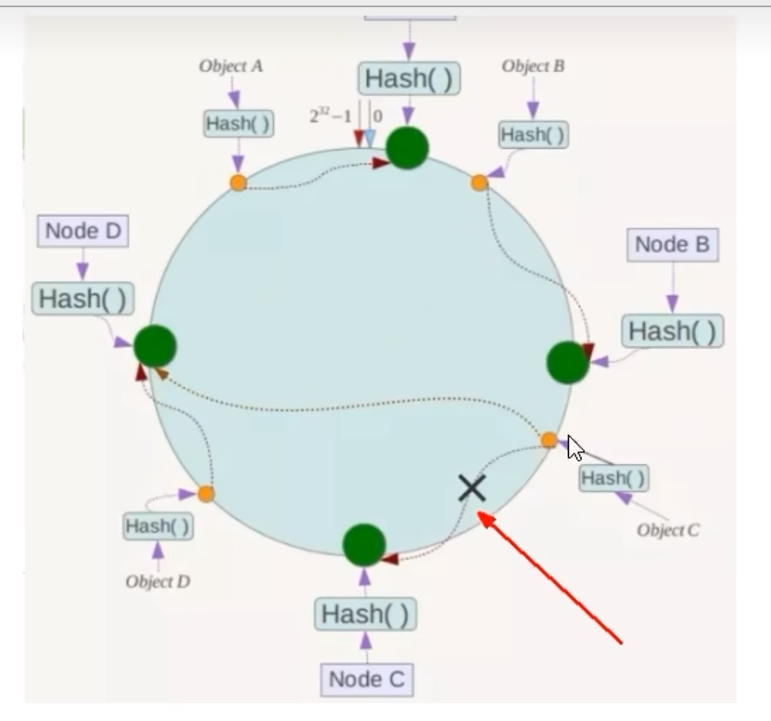

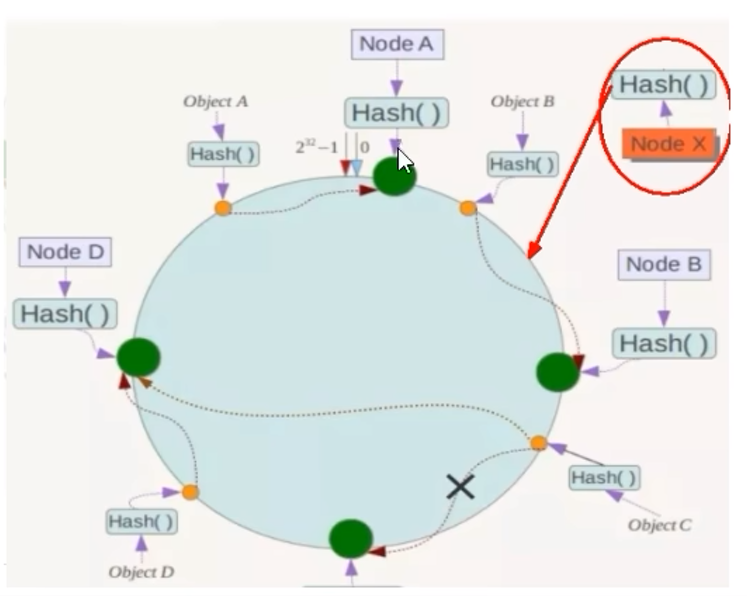
缺点:
数据倾斜
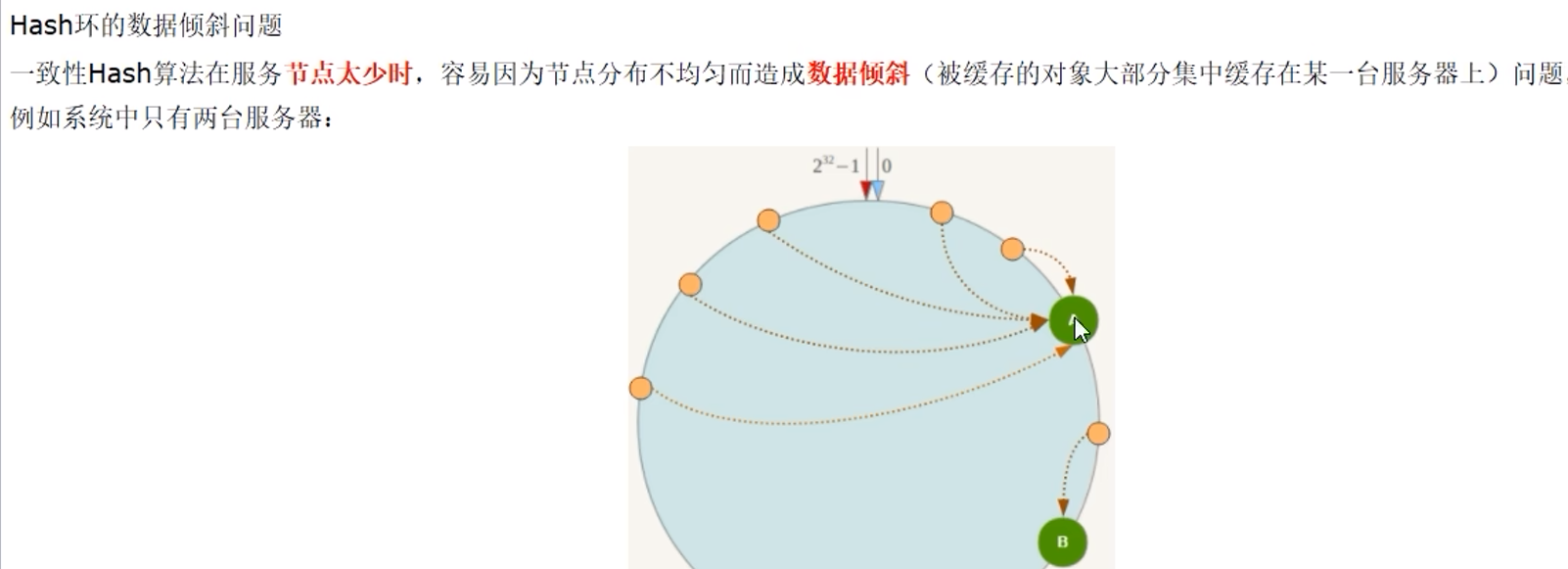
总结:
9.6.3 哈希槽计算
是什么:
实质是一个数组: 214 = 16384
214 = 16384

能干什么:

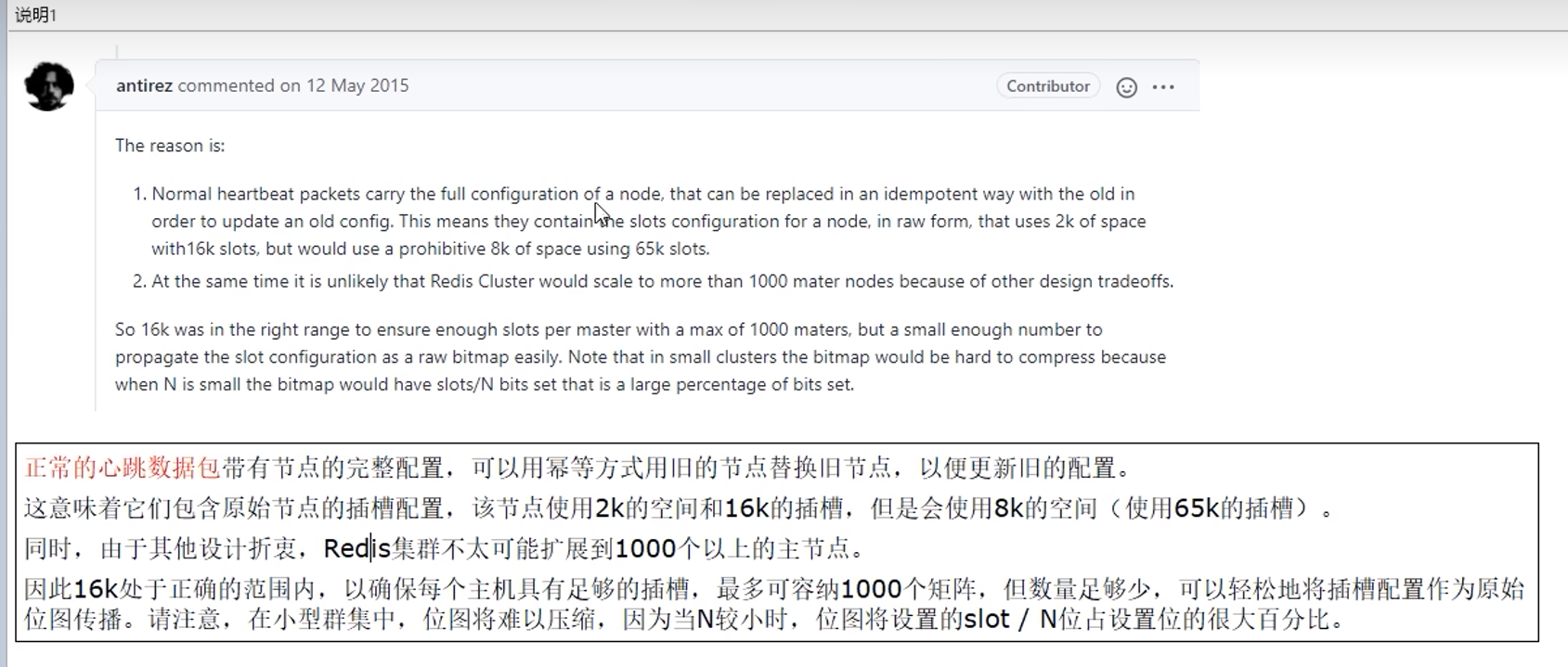
为什么采用16384而不是216?



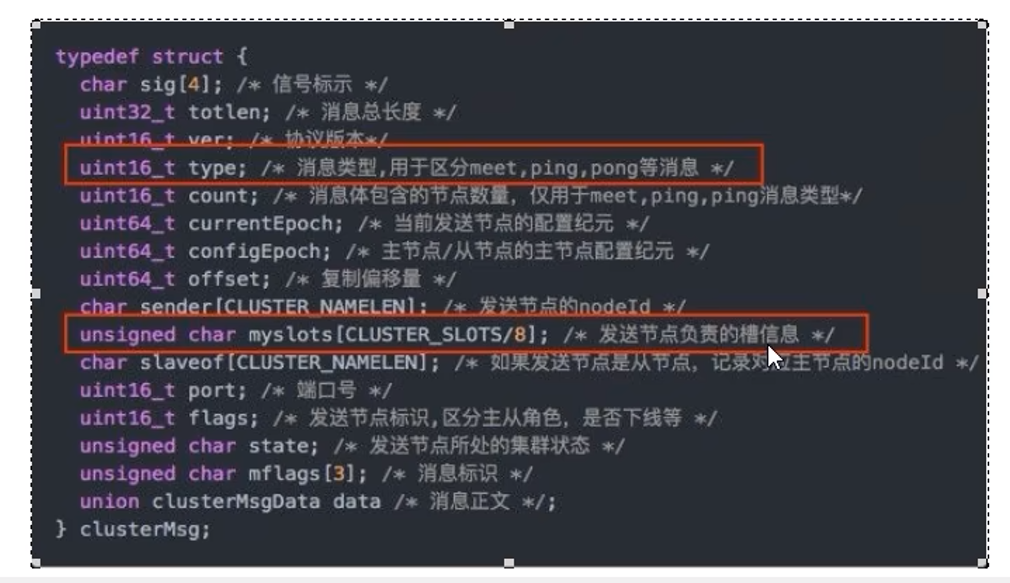
9.7 Redis集群不保证强一致性


9.8 集群搭建

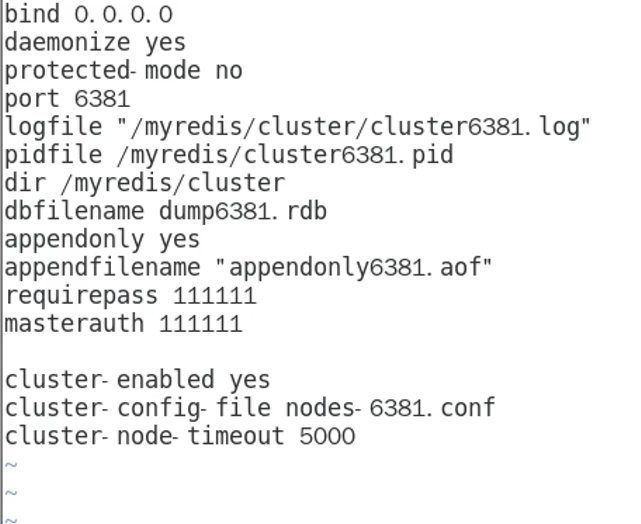
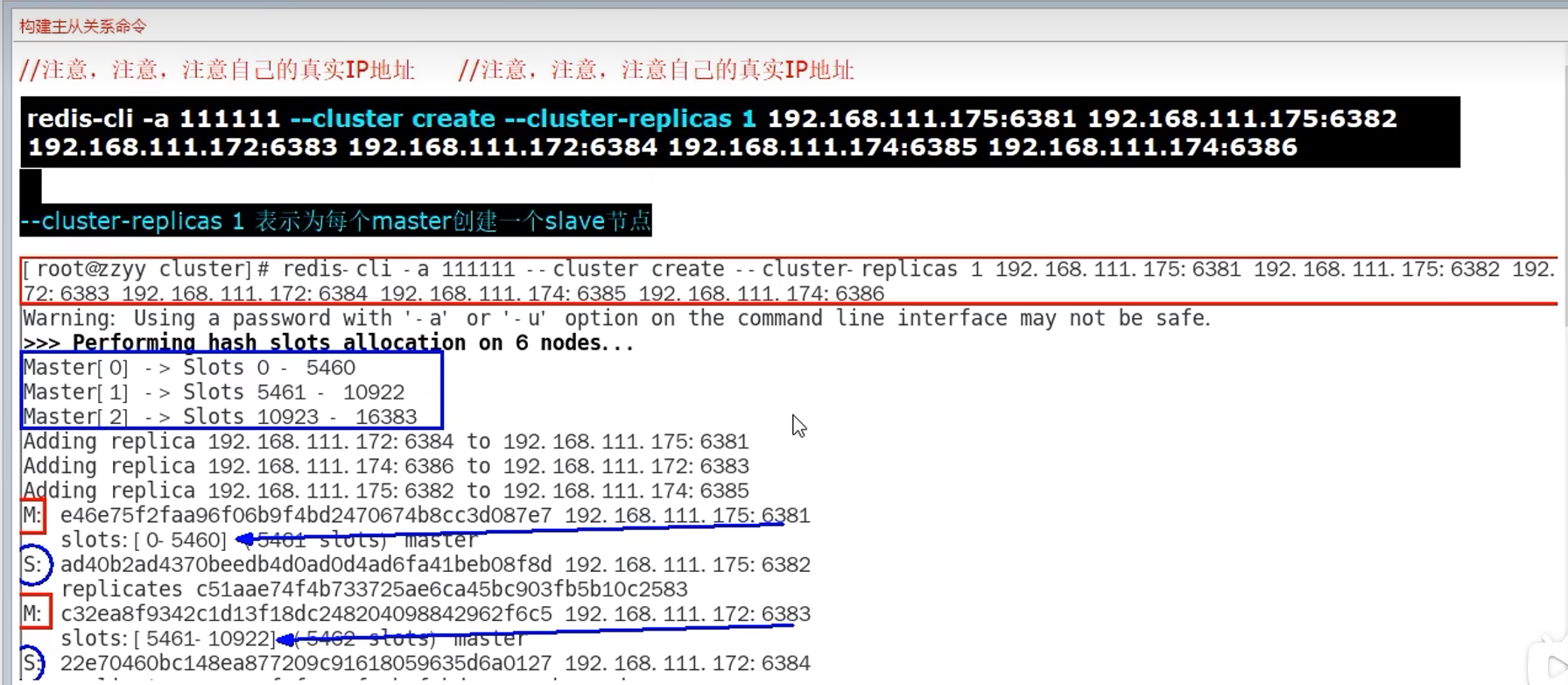
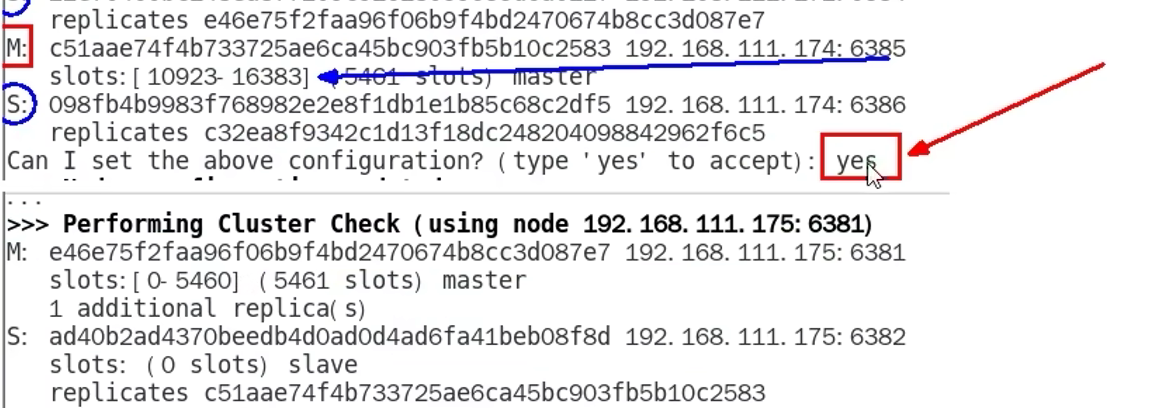
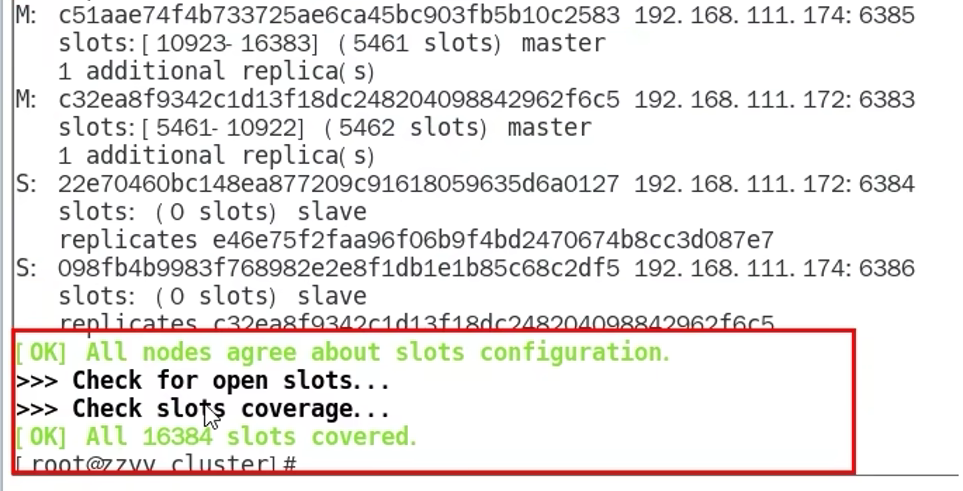
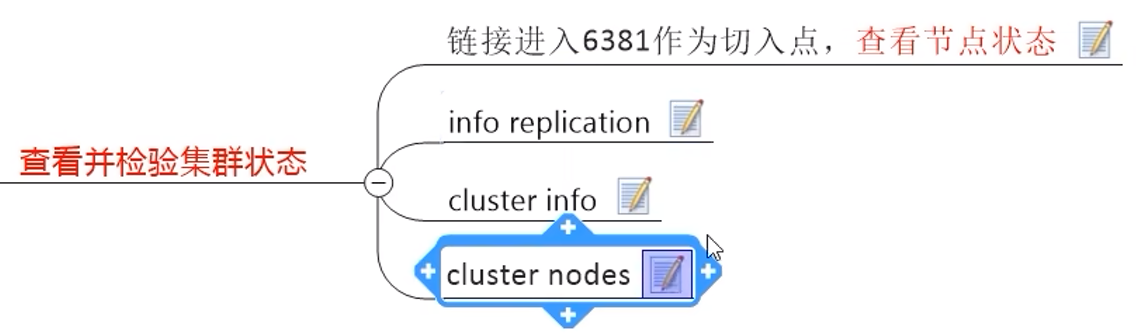

9.9 读写数据
普通的登录,写入可能出错:
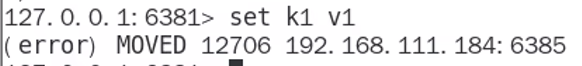

解决方法(-c):



输出槽位号(cluster keyslot)

9.10 容错切换
一台master宕机,其从机上位,旧master归来后变成从机
如果想要保持原来的关系,使用cluster failover命令(节点从属调整)


9.11 扩容

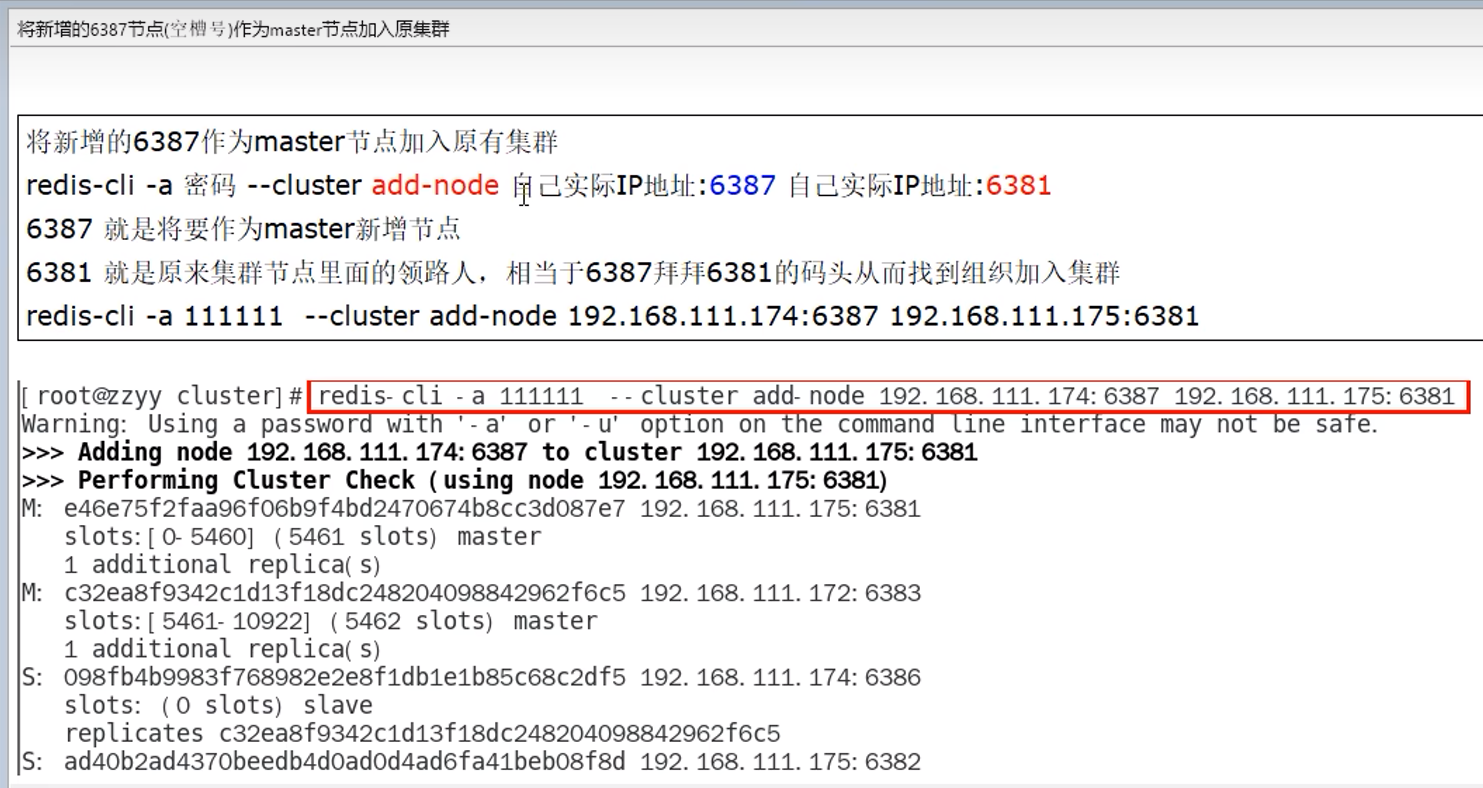
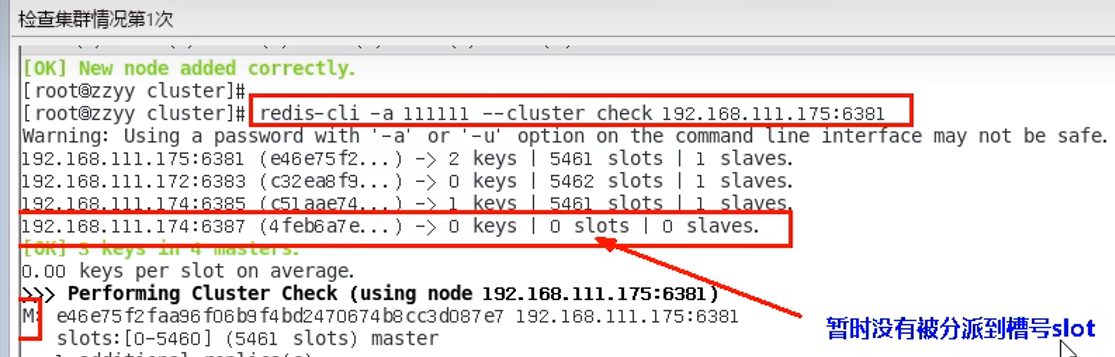
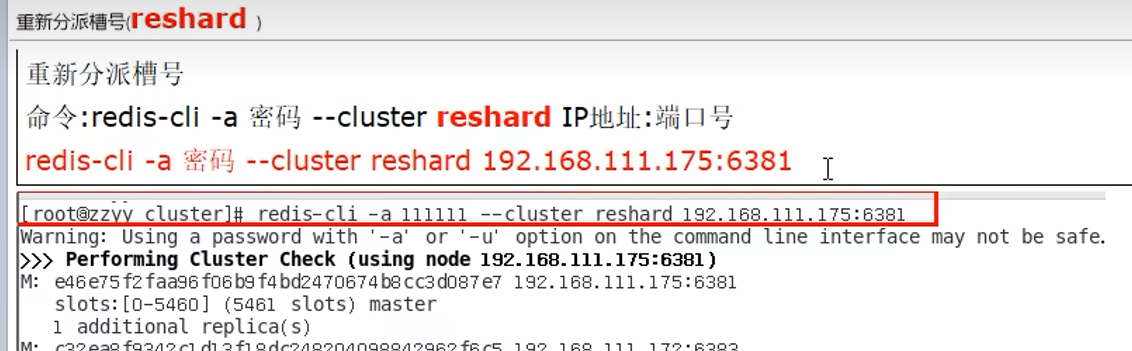
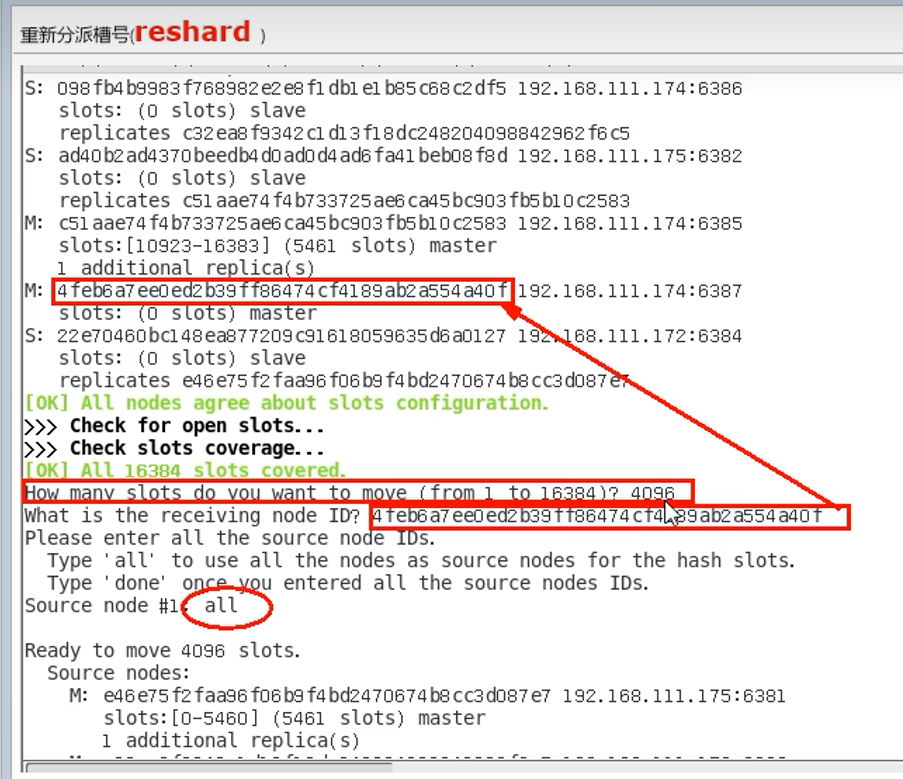
直接选部分,用来分配,而不是全部重新分配(即不是平均一人一段),现在新加的,由三段构成
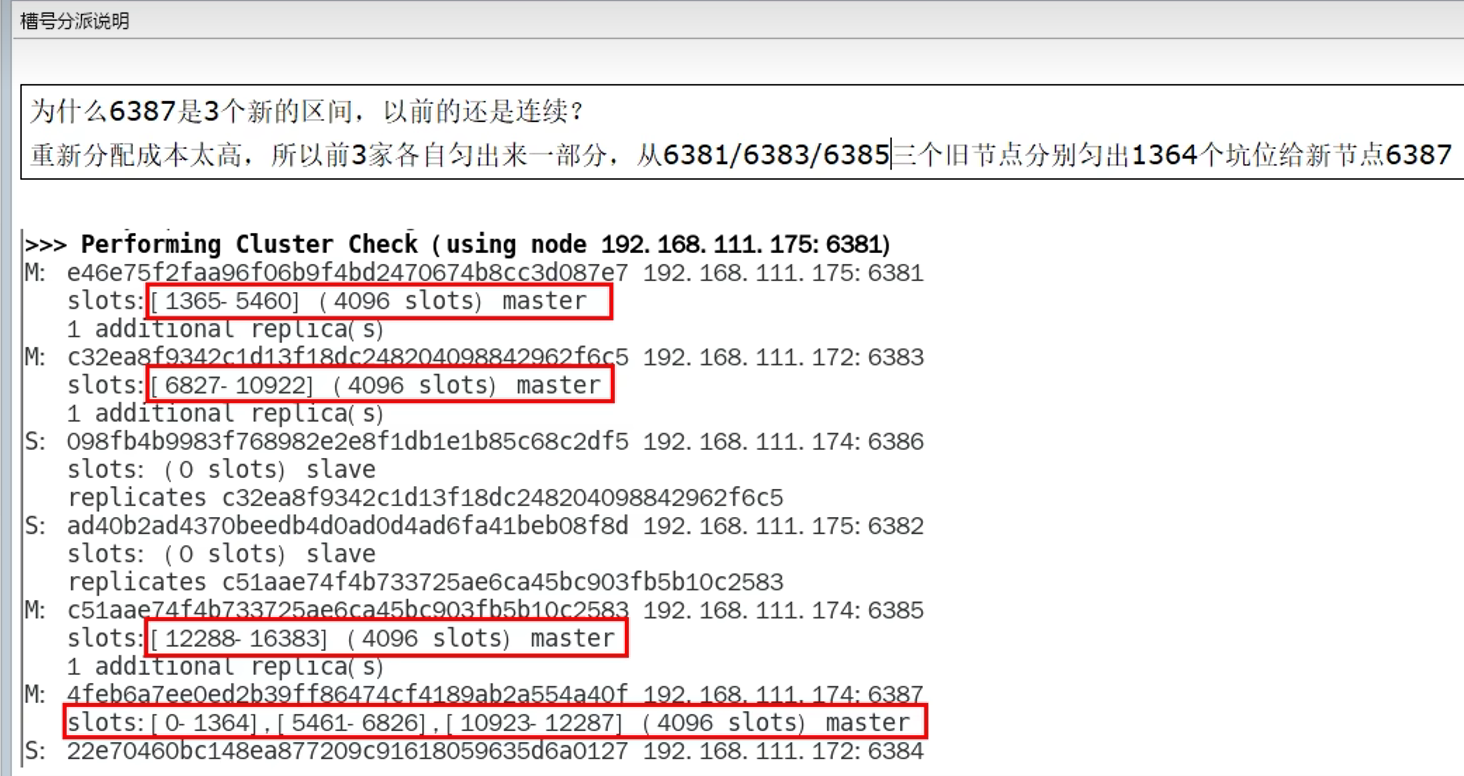
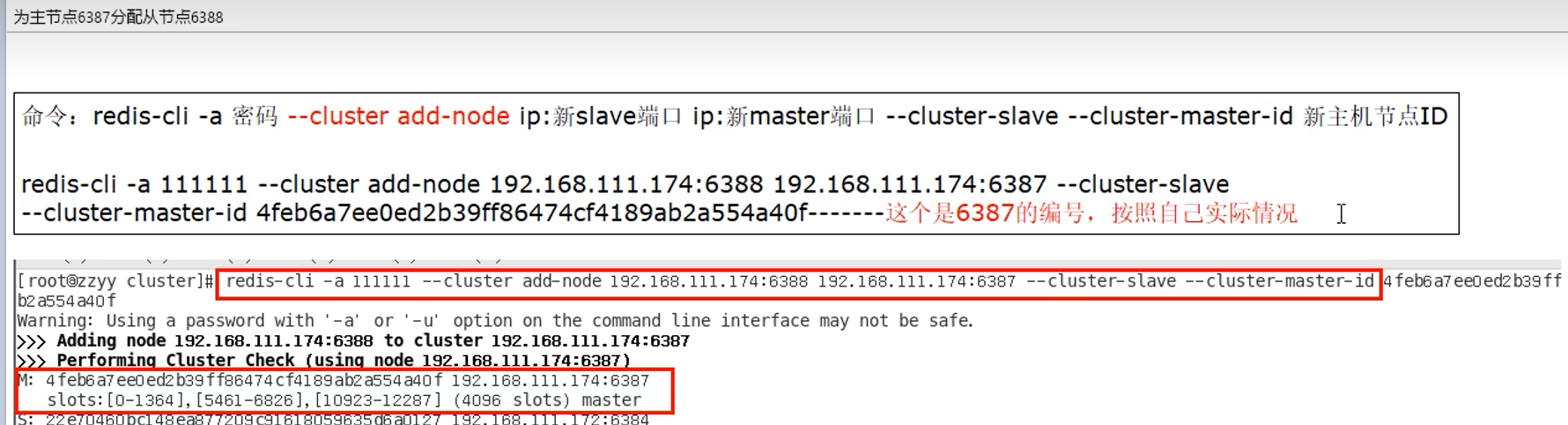
9.12 缩容
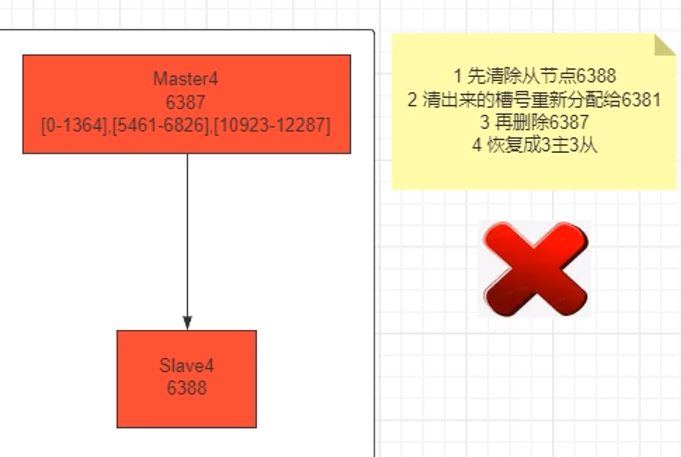
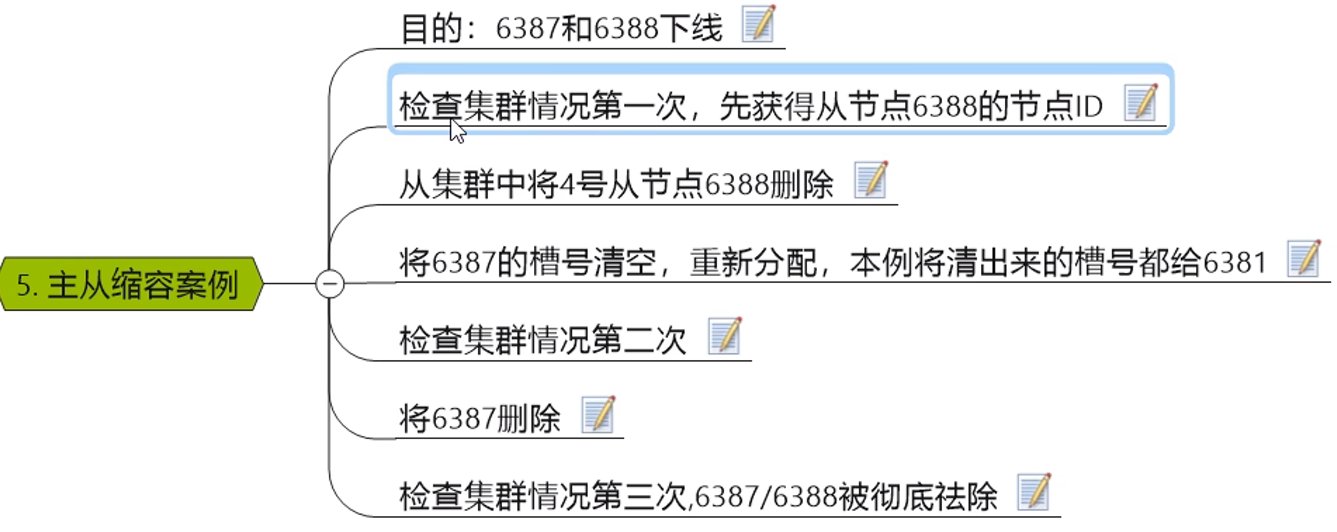
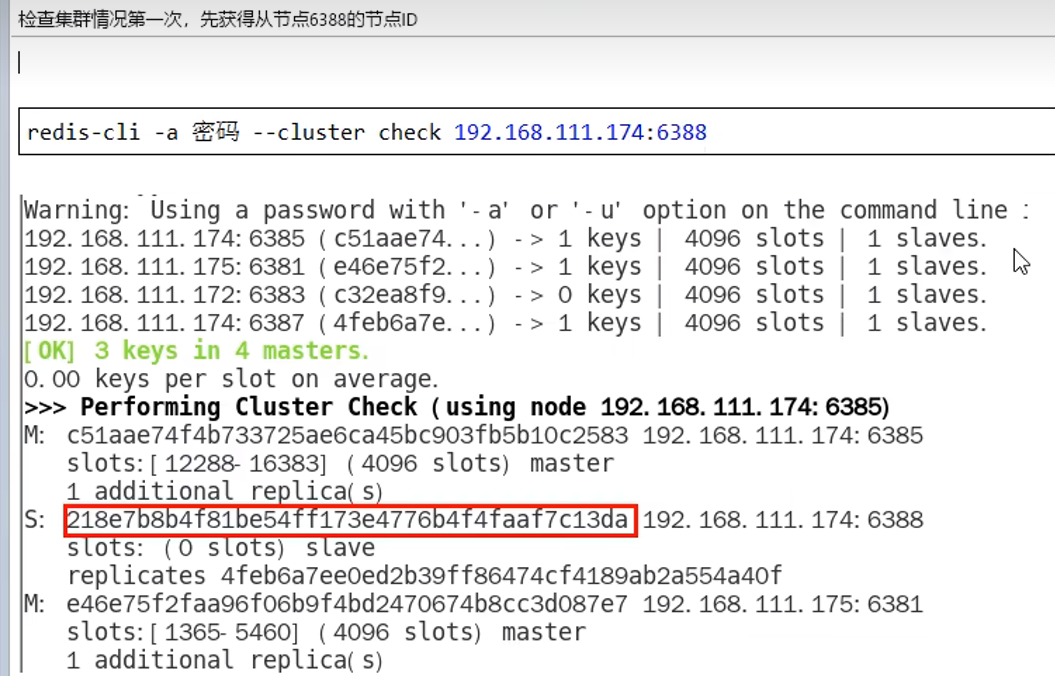


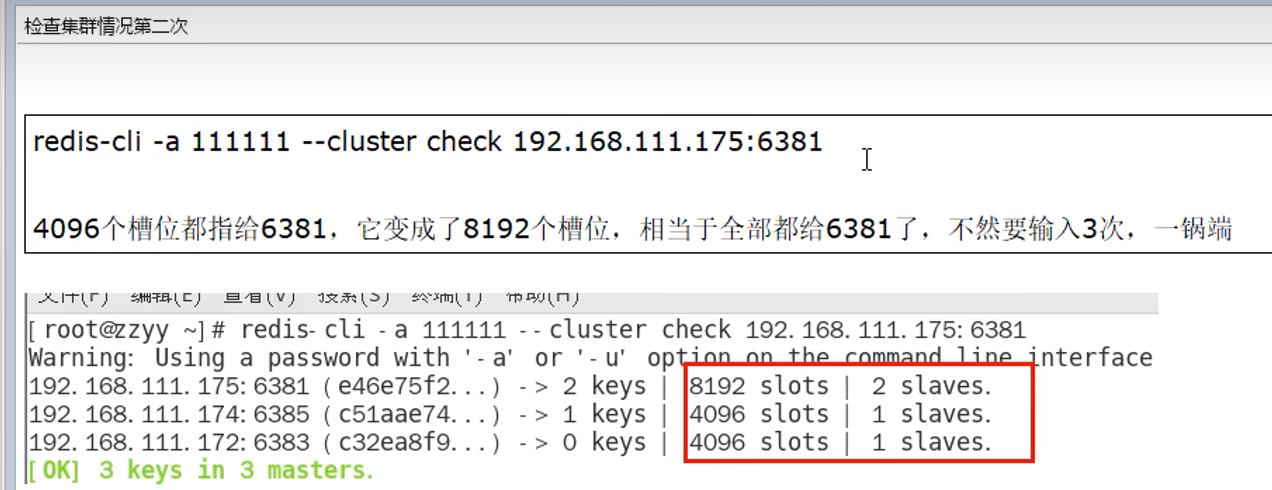
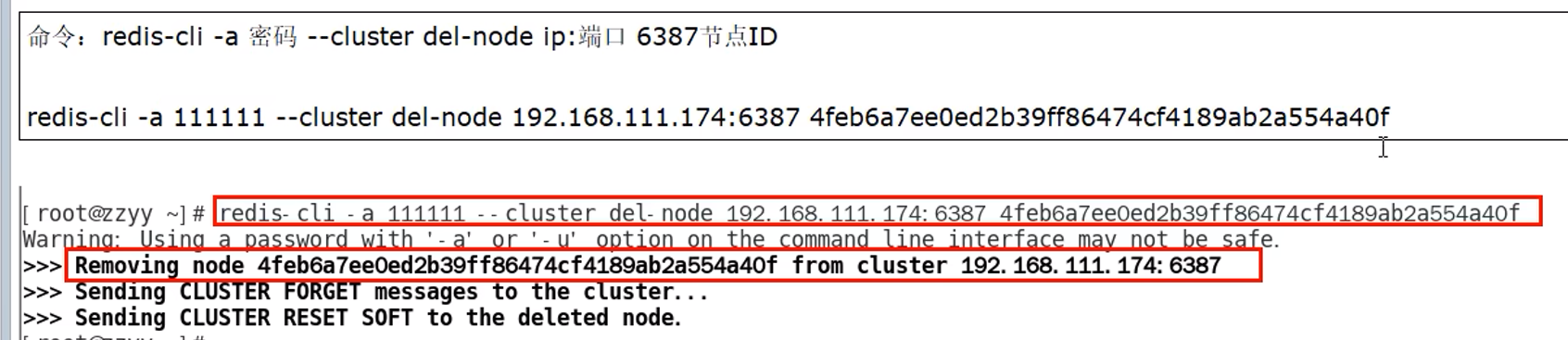
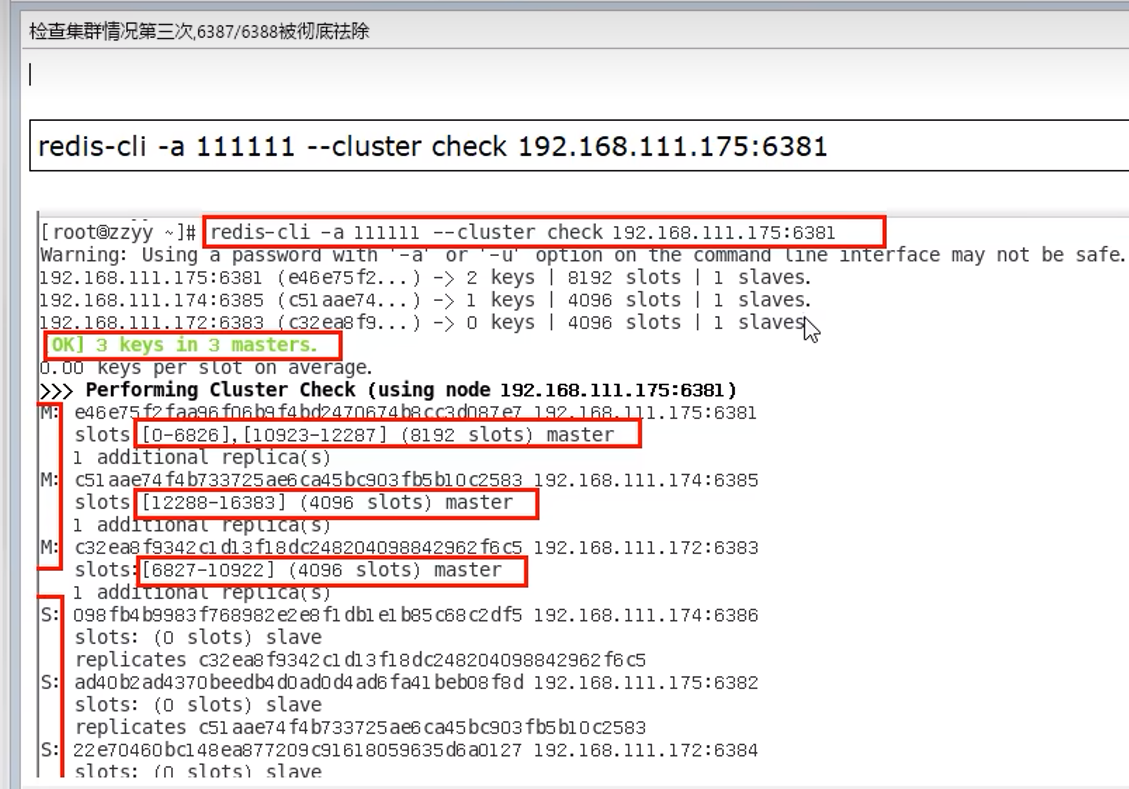
9.13 总结



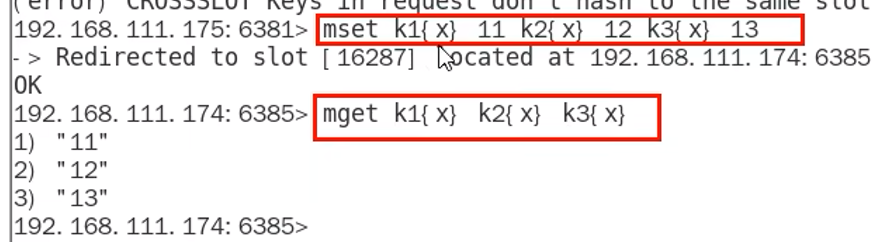
可以是x,也可以是任意的
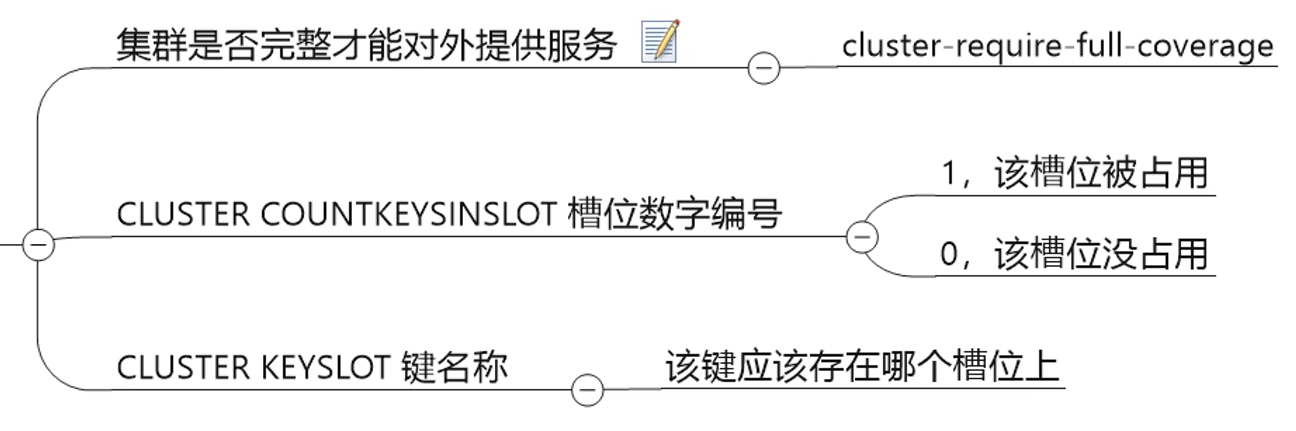
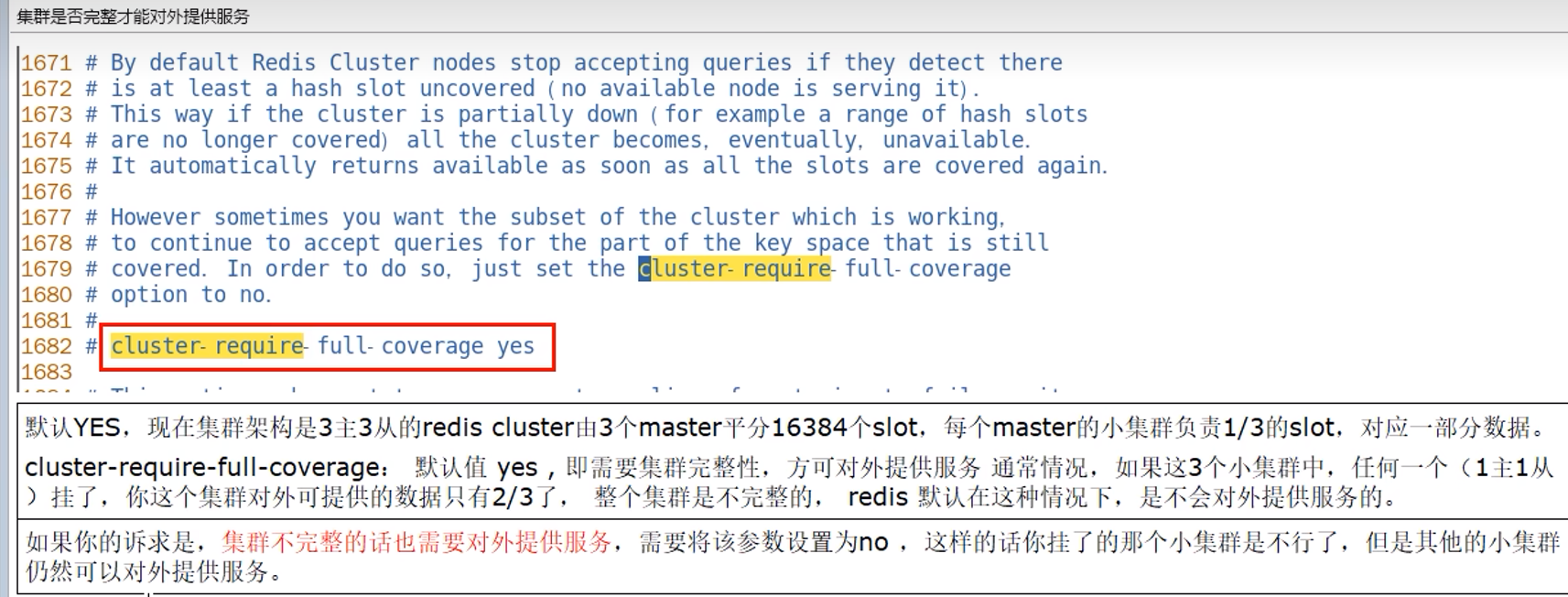
10. Springboot整合Redis
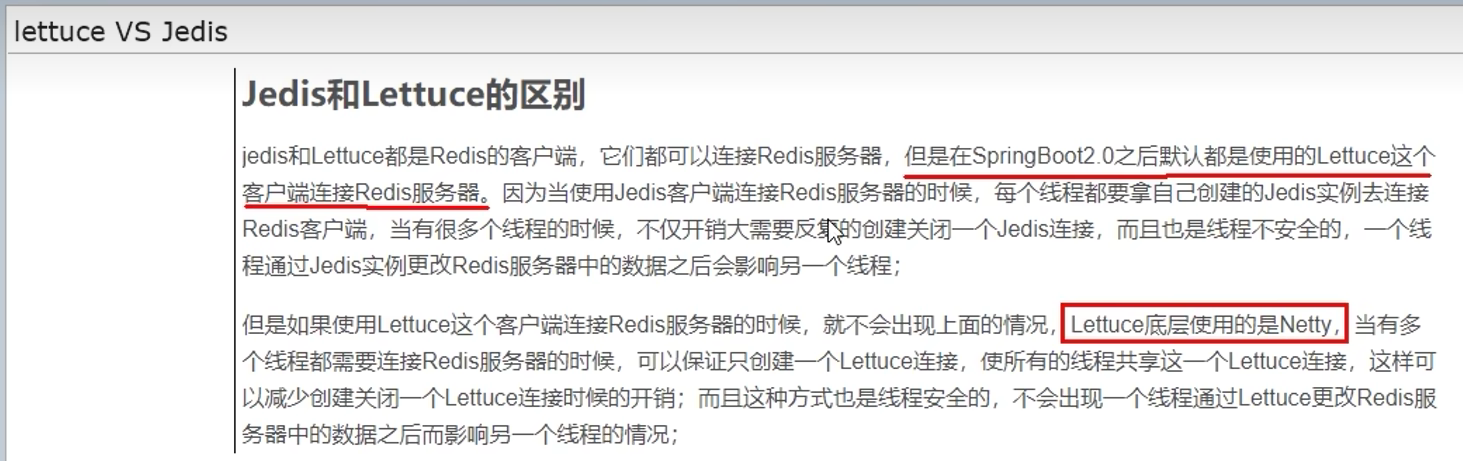
Jedis -> lettuce -> RedisTemplate
Jedis是最早的,lettuce是第二代,现在主要用springboot整合的RedisTemplate
10.1 连接Redis问题

10.2 Jedis
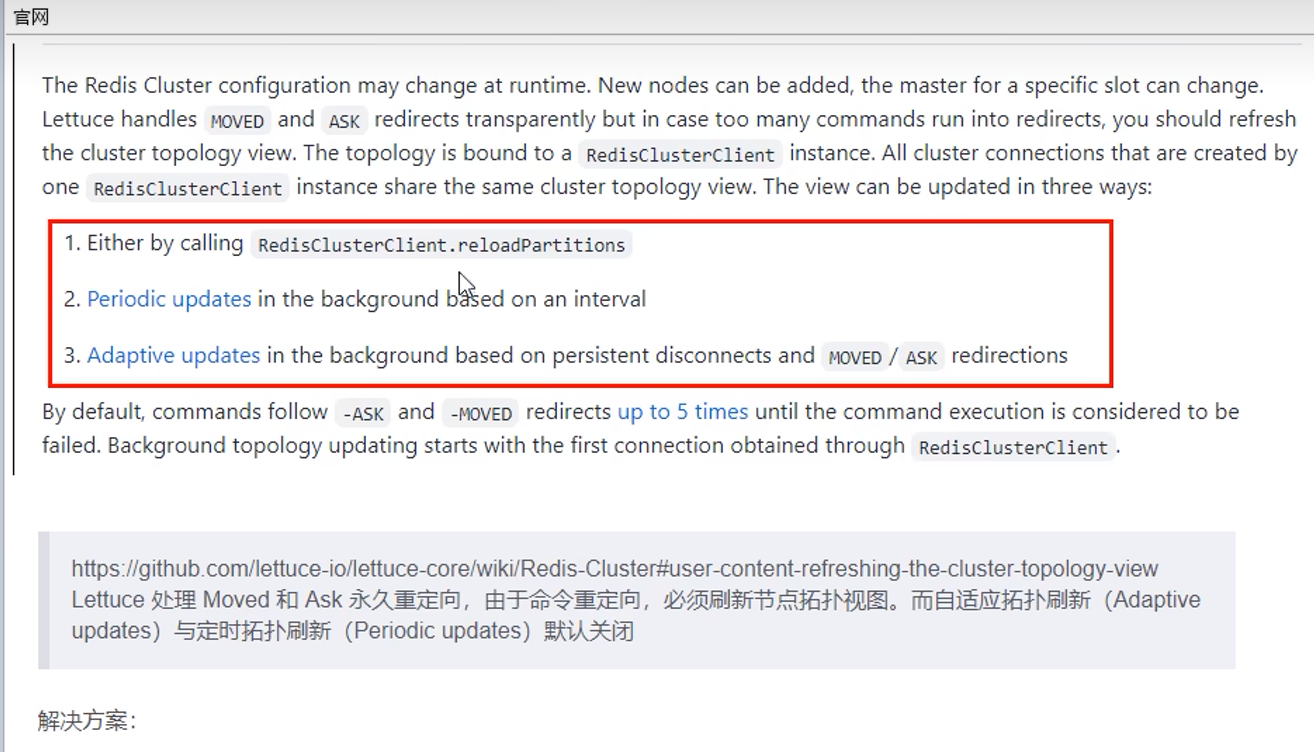
10.3 Lettuce
解决Jedis的线程不安全问题
10.4 RedisTemplate
10.4.1 单机
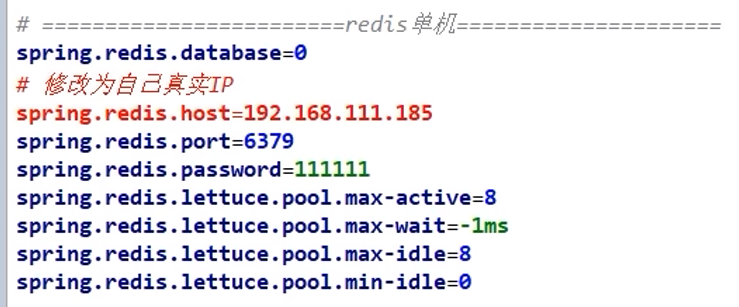


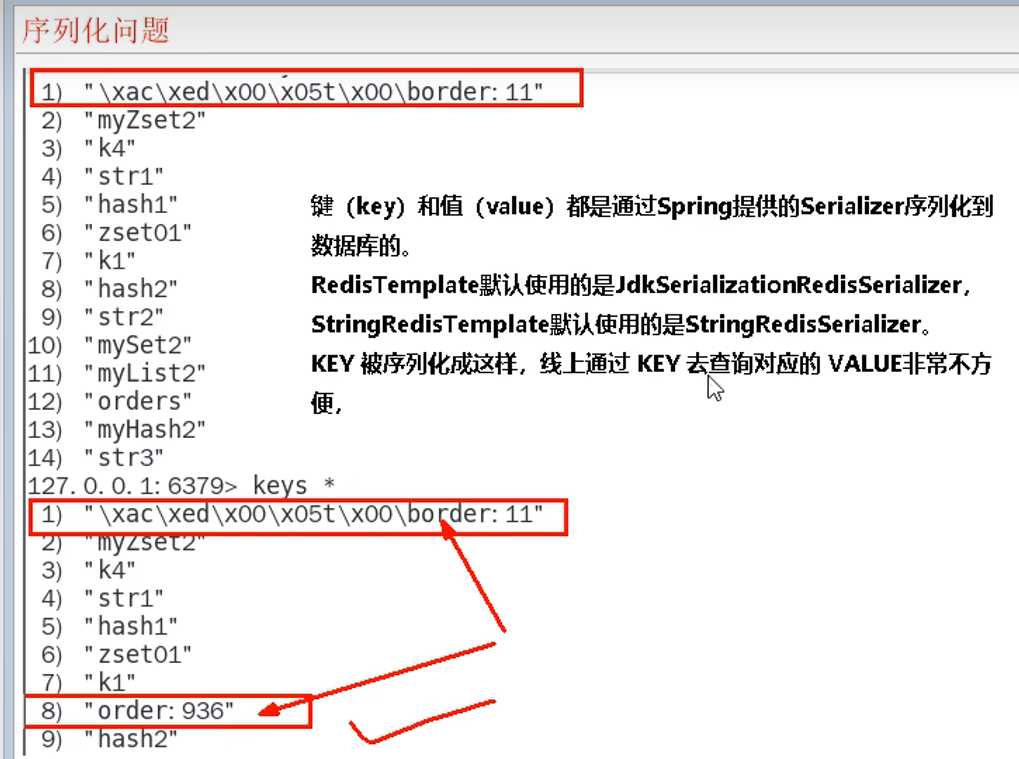
存在序列化问题(因此需要Redis配置类或者StringRedisTemplate)
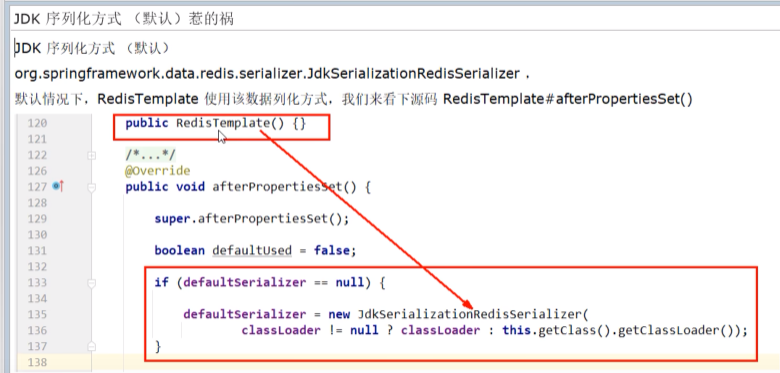
对于Key乱码:
- 使用StringRedisTemplate能够解决key的乱码问题,但是局限于String
- 最好使用Redis配置类,就能继续使用RedisTemplate,如下,下面springboot高版本报错,但是不影响使用
package com.xxx.studyredistemplate.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.lettuce.LettuceConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;
@Configuration
public class RedisConfig {
/**
* redis序列化的工具配置类,下面这个请一定开启配置
* 127.0.0.1:6379> keys *
* 1) "ord:102" 序列化过
* 2) "\xac\xed\x00\x05t\x00\aord:102" 野生,没有序列化过
* this.redisTemplate.opsForValue(); //提供了操作string类型的所有方法
* this.redisTemplate.opsForList(); // 提供了操作list类型的所有方法
* this.redisTemplate.opsForSet(); //提供了操作set的所有方法
* this.redisTemplate.opsForHash(); //提供了操作hash表的所有方法
* this.redisTemplate.opsForZSet(); //提供了操作zset的所有方法
* @param lettuceConnectionFactory
* @return
*/
@Bean
public RedisTemplate<String, Object> redisTemplate(LettuceConnectionFactory lettuceConnectionFactory )
{
RedisTemplate<String,Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(lettuceConnectionFactory);
//设置key序列化方式string
redisTemplate.setKeySerializer(new StringRedisSerializer());
//设置value的序列化方式json,使用GenericJackson2JsonRedisSerializer替换默认序列化
redisTemplate.setValueSerializer(new GenericJackson2JsonRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setHashValueSerializer(new GenericJackson2JsonRedisSerializer());
redisTemplate.afterPropertiesSet();
return redisTemplate;
}
}对于Value乱码的解决:
使用--raw启动客户端

10.4.2 集群

问题:
当一个master挂掉,从机上位,springboot客户端没有动态感知到架构变化