RabbitMQ笔记
1.MQ概念
1.1 什么是MQ?
MQ(message queue)是消息队列
1.2
MQ具有三大功能:
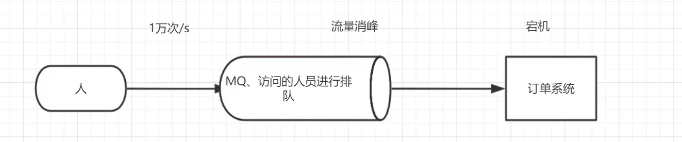
流量削峰:如果没有MQ,高并发的时候,系统直接宕机,有了MQ之后,通过排队,虽然时间开销更多了,但是不会导致系统宕机
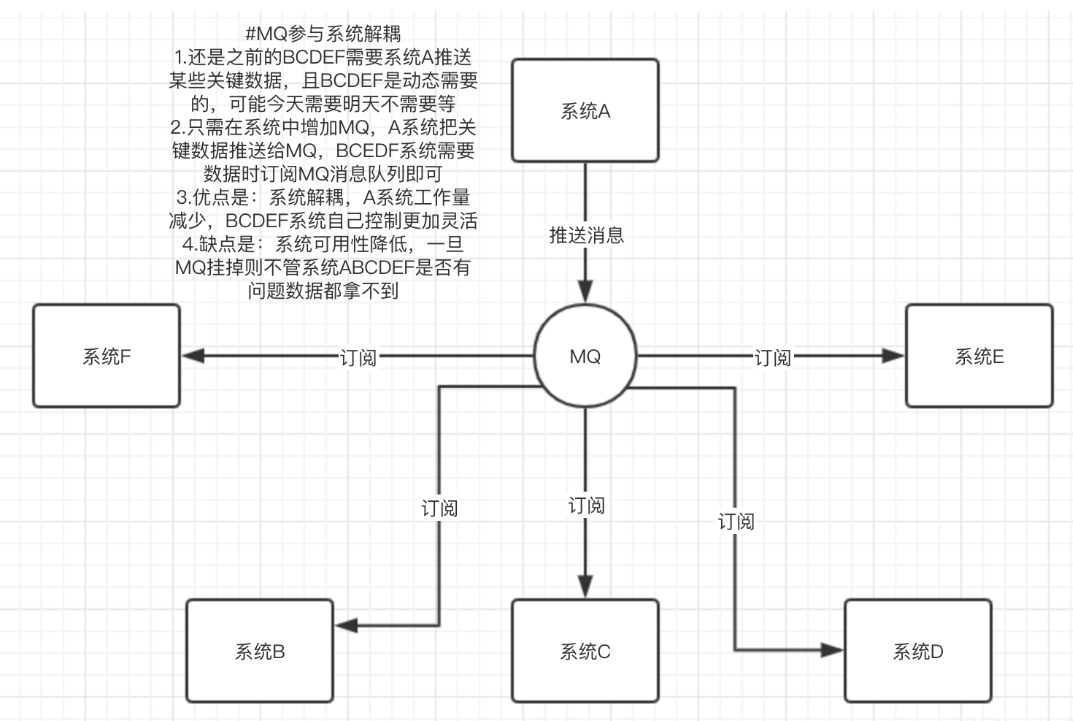
应用解耦:消息的发送方和接收方不需要彼此联系,所以不会相互影响,即解耦
异步处理:对于不需要等待返回结果的操作,如果是同步,则会等待,这段时间就会浪费,而通过异步处理,就可以利用这段时间做其他事,从而减少响应时间,处理完后,被调用者把数据发给MQ,MQ再发回给调用者。比如发送短信、邮件、赠送积分等就可以异步执行
MQ的分类(主流):
- kafka吞吐量高,一般用在日志采集方面
- RocketMQ阿里的,能抗住阿里双十一的流量,电商,金融级,大公司
- RabbitMQ吞吐量比前两个低,并发性能高,中小公司主流
2.RabbitMQ
2.1 概念:消息中间件,接收、存储和转发消息数据
四大核心概念:
- 生产者:发信息
- 交换机:接收消息,再推送到队列中
- 队列:本质是大的消息缓冲区,很多生产者可以发消息到队列中,很多消费者可以尝试从队列中接收数据
- 消费者:接收消息
2.2 核心部分:七大模式
- 简单模式,“hello world!”
- 工作模式,Work queues
- 发布订阅模式,Publish/Subscribe
- 路由模式,Routing
- 主题模式,Topics
- RPC, Request/reply pattern
- 发布确认模式,Publisher Confirms

Broker:RabbitMQ Server就是Message Broker
Connection:TCP连接
Channel:极大减少了操作系统建立TCP connection的开销,相当于数据库的连接池
Binding:Exchange和Queue之间的虚拟连接
Virtual host:出于多租户和安全因素设计,Broker可以有多个vhost,每个vost可以有多个交换机
2.3 Hello World
1生产者对1消费者
2.4 Work Queue
工作队列(又称任务队列),主要思想是:避免立即执行资源密集型任务,而是将耗时的大量任务分配给多个工作线程
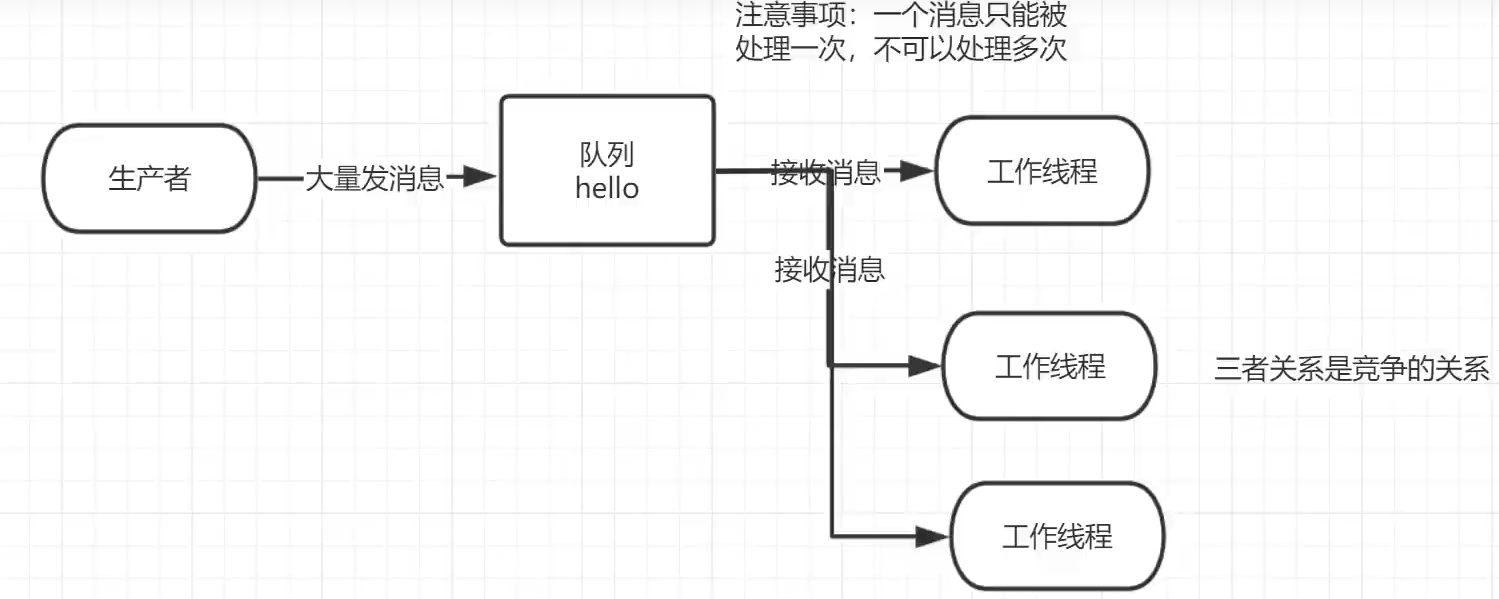
1.轮询分发消息
一个队列对应多个工作线程(消费者)
这些工作线程是轮着处理消息(轮询)
消息只会被处理一次
2.消息应答
如果工作线程在执行一个长任务,但是还没完成的时候,工作线程挂掉了,而且队列删掉了消息,那么这个消息就没被完成而且丢失了,这是我们不想要的。
为了保证其不被丢失,就要采用消息应答
自动应答(还是可能存在消息丢失,但是更高效)(autoAck默认为false):
一旦消费者收到消息,就进行应答,如果后续出了问题,消息已经被删除了
手动应答(安全):
手动进行应答
Channel.basicAck(手动确认收到消息)
Channel.basicNack(否定确认)
Channel.basicReject(否定确认)
Reject比Nack少一个
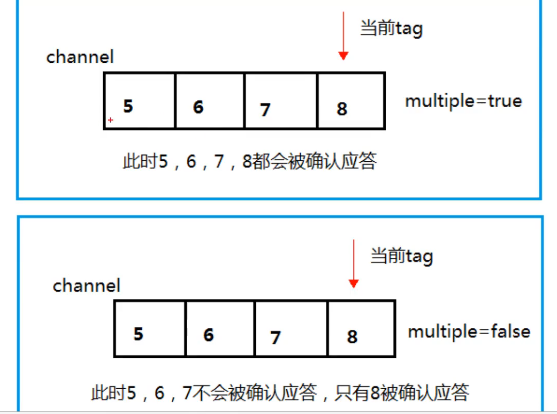
参数multiple(前两个都有此参数)
批量应答,可以减少网络拥堵,但是可能存在消息丢失,一般false
true to reject all messages up to and including the supplied delivery tag;
false to reject just the supplied delivery tag.
- 消息自动重新入队
如果一个消费者死亡(它的通道被关闭,连接被关闭,或者TCP连接丢失)而没有发送ack, RabbitMQ将理解消息没有被完全处理,并将重新将其排队。如果同时有其他消费者在线,它将迅速将其重新交付给另一个消费者。这样就可以确保没有信息丢失,即使工作人员偶尔会死亡。
在消费者交付确认时强制执行超时(默认为30分钟)。这有助于检测从不确认交付的有bug的(卡住的)消费者。您可以根据需要增加这个超时时间
3.遇到的问题
先启动消费者报错NOT_FOUND - no queue 'XXX',因为在这个程序里是在生产者创建的queue,在消费者里面使用queue,所以应该先启动生产者。之所以之前测试的时候先启动消费者没报错(实际是启动过生产者了),因为autoDelete设置为了false,所以queue仍然存在,就没报错
关于autoDelete设置为false,queue已存在,此时我再设置为true,会报错received ‘true‘ but current is ‘false‘,其参数durable设置不匹配,再次创建queue的时候也会报错,
解决方案一:channel.queueDelete(TASK_QUEUE_NAME);删了重创,也可登陆网站,图形化界面来删除
解决方案二:改为和存在的queue的参数一致
4.RabbitMQ持久化
概念:为了保障当RabbitMQ服务停掉以后消息生产者发送过来的消息不丢失
默认情况下,RabbitMQ崩溃后,会忽视队列和消息,为了不丢失消息,需要将队列和消息都标记为持久化
队列持久化:创建队列(channel.queueDeclare)时,把durable参数设置为true。这样关机,重启后队列不会丢失
消息持久化:发布时持久化,[但仍可能丢失(正在存储时,还没存完,只是缓存了)],
实现方法:把channel.basicPublish的props的参数设置为
MessageProperties.PERSISTENT_TEXT_PLAIN
不公平分发:能者多劳,处理速度快的分配多一些任务,使得处理快的不至于空闲。
设置方法:消费者方的channel.basicQos(x); x为非零
不设置,或者设置成0,就是公平分发(为0,则可以无限堆积消息,因此一定可以一个一个地发消息,所以公平)
其实不公平分发,实质上也是轮询,一个一个发,但是当缓冲区的堆积消息数量超过了 预取值(prefetchCount),就会找处理完了的消费者进行处理,因此会产生能者多劳现象
channel.basicQos(1); //basicQos(int prefetchCount)
prefetchCount:处理消息最大的数量。举个例子,如果输入1,那如果接收一个消息,但是没有应 答,则客户端不会收到下一个消息,消息只会在队列中阻塞。如果输入3,那么可以最多有3个消息 不应答,如果到达了3个,则发送端发给这个接收方得消息只会在队列中,而接收方不会有接收到消 息的事件产生。总结说,就是在下一次发送应答消息前,客户端可以收到的消息最大数量。
2.5 发布确认 Publisher Confirms
目的是:
防止消息丢失
前提:
1.队列必须持久化、2.消息必须持久化
必须再加上3.发布确认
三个都要满足,消息才绝对不会丢失,不然消息可能丢失
开启方法:
channel.confirmSelect();
2.5.1 发布确认原理
生产者将信道设置成confirm模式,一旦信道进入confirm模式,所有在该信道上发布的消息都会有一个唯一 的ID(从1开始),一旦消息被投递到所有匹配的队列之后,broker就会发送确认给生产者(包括唯一ID),
这就使得生产者知道消息正确到达目的队列了,如果消息和队列是可持久化的,那么确认消息会在消息写入 磁盘后发出
confirm模式最大的好处在于它是异步的,一旦发布一条消息,生产者可以在等待返回确认的同时继续发送下 一条消息,当消息最终得到确认后,生产者便可通过回调来处理该确认消息,如果RabbitMQ因为自身内部错 误导致消息丢失,就会发送一条nack消息,生产者同样通过回调来处理nack消息
2.5.2 发布确认策略
分为3种:单个、批量、异步确认发布
单个确认发布
同步的,发一条就会等待确认信息
实现:每个消息发布后都调用channel.waitForConfirms()或者waitForConfirmsOrDie();
区别:
如果任何消息被删除,waitForConfirmsOrDie将抛出IOException。
waitForConfirms()有返回值boolean,waitForConfirmsOrDie没有
理解:
可以将waitForConfirmsOrDie看作是一个同步helper,它依赖于底层的异步通知。
它只是进行了阻塞
注意:信道没有设置成confirm模式,则会throws an IllegalStateException.
批量确认发布
实现:每隔批量大小的消息发布后,再进行发布确认(channel.waitForConfirms();)
优点:速度比单个确认发布快
缺点:但是如果一个批次某一个或一些出了问题,不能知道具体是哪个消息
异步确认发布
异步,一直发消息,对于确认信息,只需要靠broker收到后再发回来,这时候再进行回调,
这样就既速度快,也能确切知道出问题的消息是哪个
//消息确认成功回调
ConfirmCallback ackCallback = (deliveryTag, multiple) -> {
System.out.println("确认的消息" + deliveryTag);
};
//消息确认失败回调
/**
* 参数1 消息的标记
* 参数2 是否批量确认
*/
ConfirmCallback nackCallback = (deliveryTag, multiple) -> {
System.out.println("未确认的消息" + deliveryTag);
};
//监听器
channel.addConfirmListener(ackCallback,nackCallback);
///////////////////
//详细版:
/**
* 线程安全有序的一个哈希表 适用于高并发的情况下
* 1.轻松的将序号和消息进行关联
* 2.轻松批量删除 by 序号
* 3.支持高并发(多线程)
*/
ConcurrentSkipListMap<Long,String> confirms = new ConcurrentSkipListMap<>();
//消息确认成功回调
ConfirmCallback ackCallback = (deliveryTag, multiple) -> {
System.out.println("确认的消息" + deliveryTag);
//根据tag删除确认成功的消息
if(multiple){
//因为是批量的,所以删除的不止一个
//headMap,小于该tag的所有,但是当前这个也应该要删,所以要包括(<=),也就是第二个参数设置为true
ConcurrentNavigableMap<Long, String> map =
confirms.headMap(deliveryTag,true);
map.clear();
}else{
confirms.remove(deliveryTag);
}
System.out.println(confirms.size());
};
//消息确认失败回调
/**
* 参数1 消息的标记
* 参数2 是否批量确认
*/
ConfirmCallback nackCallback = (deliveryTag, multiple) -> {
System.out.println("未确认的消息" + confirms.get(deliveryTag));
};
for (int i = 1; i <= MESSAGE_COUNT; i++) {
String msg = i + "";
//存消息
confirms.put(channel.getNextPublishSeqNo(),msg);
//发布在存之后,不然删不完
channel.basicPublish("",s,null,msg.getBytes());
} 如果不写监听器,只有channel.confirmSelect();
也就是默认之开启发布确认,肯定是一直在发消息,(确没确认就不清楚了)???
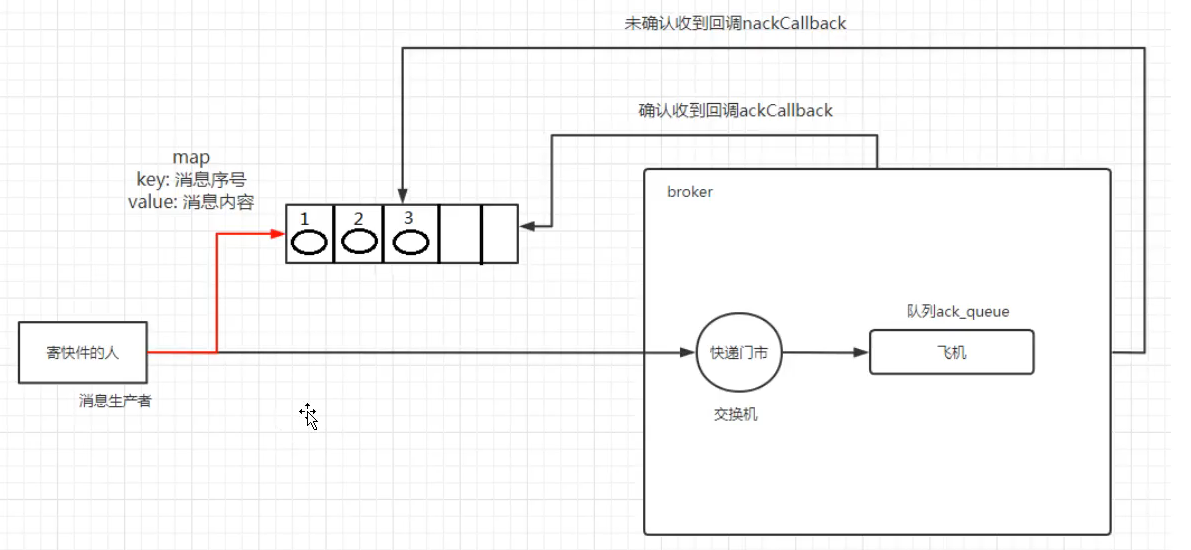
2.5.2 确认失败的消息再次发布
从相应的回调中重新发布nack-ed消息可能很诱人,但这应该避免,因为确认回调在I/O线程中被调度,而信 道不应该在这里执行发布操作。更好的解决方案是在内存队列中对消息进行排队,该队列由发布线程轮询。
像ConcurrentLinkedQueue这样的类可以很好地在确认回调和发布线程之间传输消息。
实现???
2.6 交换机
2.6.1 Exchanges概念
在工作队列模式中,每个任务都只交给一个消费者,因为是通过队列
而将消息传达给多个消费者,这种模式叫做“发布/订阅”
现在通过交换机,使用多个队列,每个队列还是保证消息只消费一次
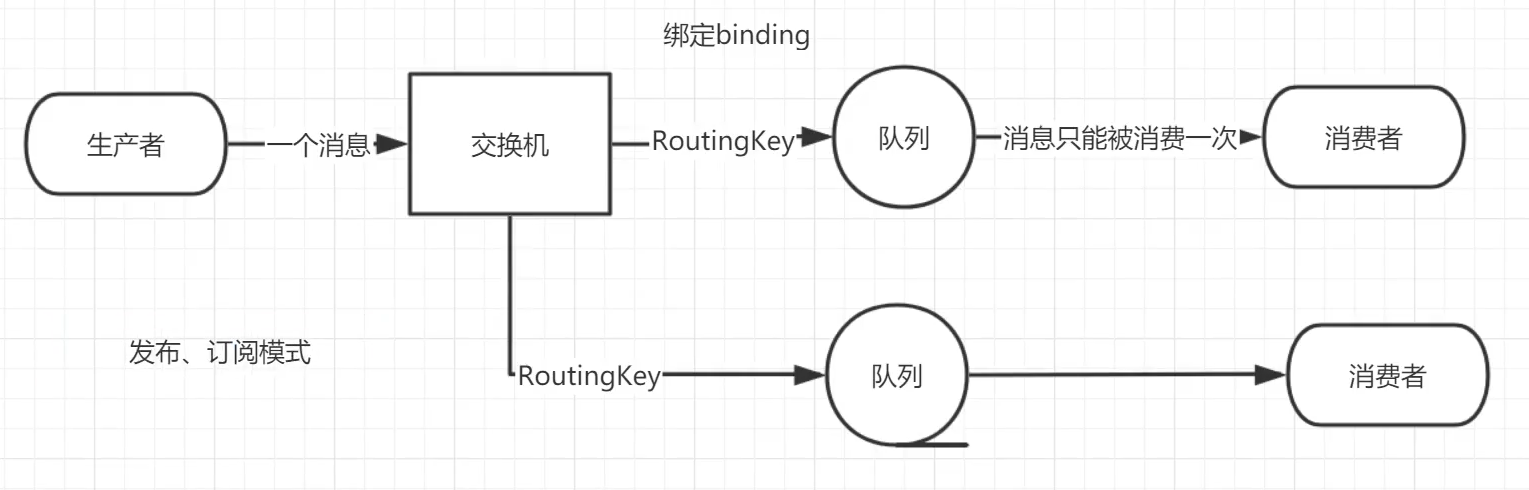
RabbitMQ消息传递模型的核心思想是:
生产者生产的消息不直接发送到队列,实际上,通常生产者甚至不知道 这些消息传递到了哪些队列
相反,生产者只能将消息发到交换机,交换机,一方面接收生产者的消息,一方面把它们推入队列
由交换机的类型,决定如何处理收到的消息
2.6.2 类型以及默认交换机
直接(direct)、主题(topic)、标题(headers),扇出(fanout)(对应的就是发布/订阅)
之前使用的是默认交换机(用的“”空串)
消息能路由发到队列中,是由routingKey(bindingkey)绑定的key指定的,如果它存在
channel.basicPublish("",TASK_QUEUE_NAME,null,msg.getBytes(StandardCharsets.UTF_8));
2.6.3 临时队列
如果不是durable(持久化的),那么就是临时队列
每当连接到Rabbit时,我们都需要一个全新的空队列,为此我们可创建一个随机名称的队列,或者服务器帮 我们选择一个随机队列名称。其次一旦我们断开了消费者连接,队列将被自动删除
创建方式:
//服务器帮我们选择一个随机队列名称
String queueName = channel.queueDeclare().getQueue();
//或者之前那种(durable声明为false)
channel.queueDeclare(TASK_QUEUE_NAME,false,false,false,null);
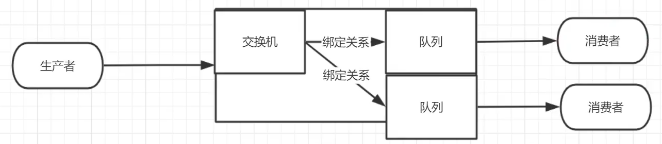
2.6.4 绑定
binding就是exchange 和 queue 的桥梁
如下图中X与Q1、Q2进行了绑定
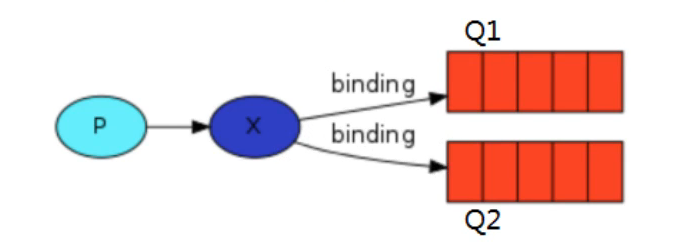
发消息到交换机(exchange) --> 根据路由规则(Routing Key)--> 找到绑定的队列(queue)
通过routing key确定使用哪个队列
2.6.5 Fanout(发布/订阅模式)
接收到的所有消息广播到它知道的所有队列

//声明交换机(在生产者和消费者其中之一声明,或者都声明,都是一样的)
//默认不自动删除,不持久化
channel.exchangeDeclare(EXCHANGE_NAME, BuiltinExchangeType.FANOUT);
//发消息,这里的第二个参数(routing key可以随便写,因为是广播,所以不需要它来区分队列)
channel.basicPublish(EXCHANGE_NAME,"",null,msg.getBytes());
//同理, 消费者的队列绑定交换机时的routing key也能随便写
channel.queueBind(queue,EXCHANGE_NAME,"");如果只在生产者声明交换机,那么必须先启动生产者,保证存在该交换机,这样消费者的队列才能绑定交换机
2.6.6 Direct exchange(路由模式)
与上面不同,这个是取决于routing key,而不是与它无关
这个模式就是通过routing key来找到接收消息的部分队列
//这里选择DIRECT模式
channel.exchangeDeclare(EXCHANGE_NAME, BuiltinExchangeType.DIRECT);
//这里的routing key就是用来区分,对该routing key声明的所有队列会收到这个消息
channel.basicPublish(EXCHANGE_NAME,"warning",null,msg.getBytes());2.6.7 Topic(主题模式)
为什么使用topic:
Direct路由模式,在某些情况下具有局限性,比如我们想要对于两种routing key来区别部分队列
而Direct中,只能写一个routing key,所以需要用到topic主题模式
使用方法:
channel.exchangeDeclare(EXCHANGE_NAME, BuiltinExchangeType.TOPIC,false,false,null);routing key举例:
* "stock.usd.nyse"
* "nyse.vmw"
* "quick.orange.rabbit"routing key的注意事项:
- * 代替一个任意单词.
- # 代替0个或多个单词.

对于routing key:
如果是# 相当于fanout,广播,群发
如果**没有#和*出现,相当于direct**,针对一个routing key
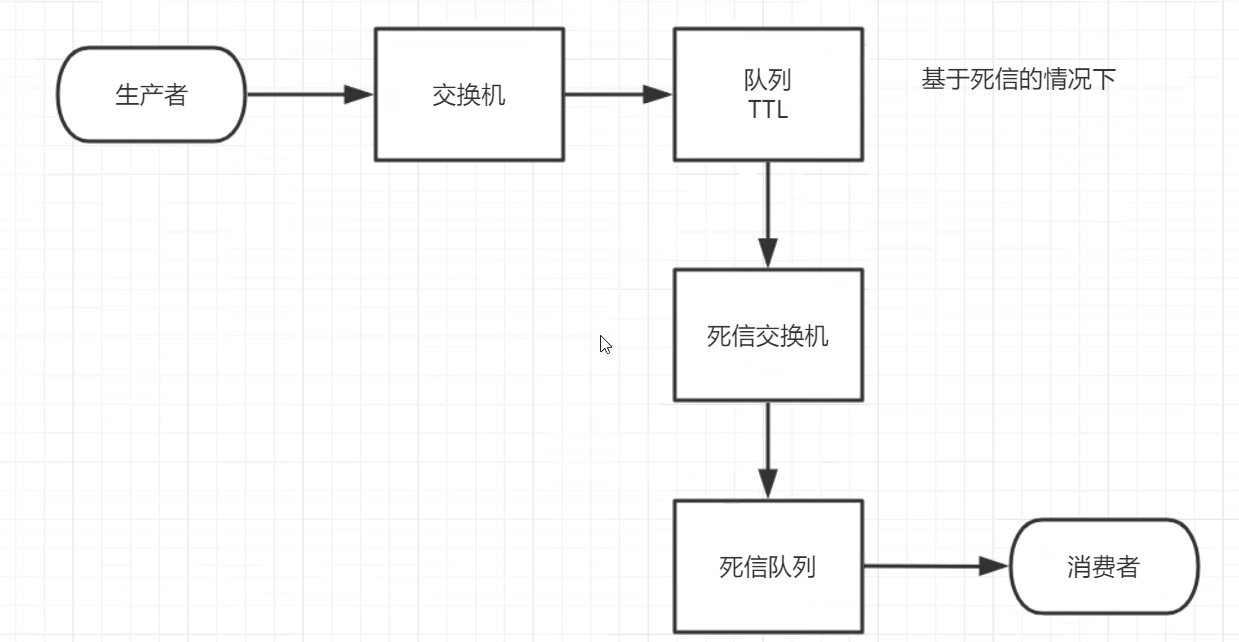
2.7 死信队列
概念:死掉的消息,无法被消费的消息
应用场景:保证订单业务消息数据不丢失,要使用RabbitMQ的死信队列机制,
当消息消费发生异常时,将消息投入死信队列,还有比如下单没有在指定时间支付时自动生效
目前有两种方式可以设置消息的TTL。
第一种是通过队列的属性设置,队列中的所有消息都有相同的过期时间。
第二种方法是对消息本身进行单独设置,每条消息的TTL可以不同。
如果两种方法同时设置,则TTL以两者之间较小的那个数值为准。
消息在队列中的生存时间一旦超过设置的TTL值时,就会变成“死信”(Dead Message),消费者将无法再收到该消息(不是绝对的)。
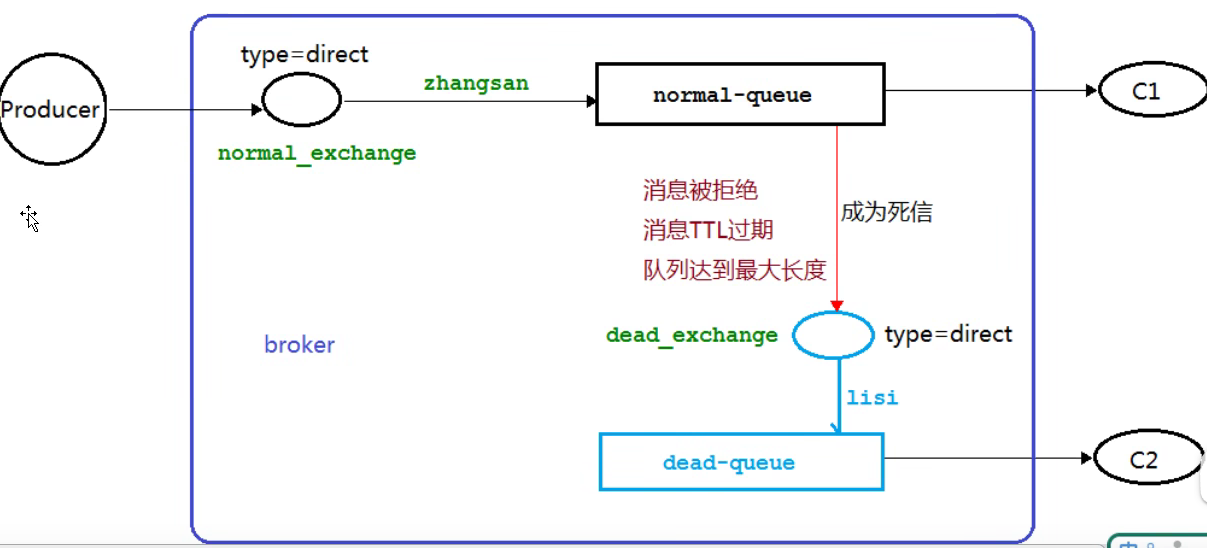
死信的来源:
- 消息TTL过期(time to live)
- 队列达到最大长度(无法再添加数据)
- 消息被拒绝(basic.reject或basic.nack)并且requeue = false
//不设置TTL,默认情况下,消息是不会过期的
//TTL
AMQP.BasicProperties properties =
new AMQP.BasicProperties()
.builder().expiration("10000").build();
channel.basicPublish(NORMAL_EXCHANGE,"zhangsan",properties,msg.getBytes());
//最大长度
arguments.put("x-max-length",6);
//拒绝
//不能自动应答
//第二个参数requeue
channel.basicReject(message.getEnvelope().getDeliveryTag(),false);2.8 延迟队列
2.8.1 概念:
延时后处理,存放需要在指定时间被处理元素的队列
相当于死信队列里的消息TTL过期,因为对于死信队列的消费者而言,消息到他那里的延迟时间正好是TTL
使用场景:
订单未支付,十分钟后自动取消
与定时器相比:
适用于数据量较大,时效性较强

//配置类代码
@Configuration
public class TtlQueueConfig {
//普通交换机名称
public static final String X_EXCHANGE = "X";
//死信交换机名称
public static final String Y_DEAD_LETTER_EXCHANGE = "Y";
//普通队列名称
public static final String QUEUE_A = "QA";
public static final String QUEUE_B = "QB";
//死信队列名称
public static final String DEAD_LETTER_QUEUE = "QD";
//声明
//x交换机
@Bean
public DirectExchange xExchange(){
return new DirectExchange(X_EXCHANGE);
}
//Y交换机
@Bean
public DirectExchange yExchange(){
return new DirectExchange(Y_DEAD_LETTER_EXCHANGE);
}
//队列QA
@Bean
public Queue queueA(){
return QueueBuilder
.durable(QUEUE_A)
.ttl(10_000)
.deadLetterExchange(Y_DEAD_LETTER_EXCHANGE)
.deadLetterRoutingKey("YD")
.build();
}
//队列QB
@Bean
public Queue queueB(){
return QueueBuilder
.durable(QUEUE_B)
.ttl(40_000)
.deadLetterExchange(Y_DEAD_LETTER_EXCHANGE)
.deadLetterRoutingKey("YD")
.build();
}
//死信队列
@Bean
public Queue queueD(){
return QueueBuilder
.durable(DEAD_LETTER_QUEUE)
.build();
}
//绑定
@Bean
public Binding queueABindingX(Queue queueA,
DirectExchange xExchange){
return BindingBuilder.bind(queueA).to(xExchange).with("XA");
}
@Bean
public Binding queueBBindingX(Queue queueB,
DirectExchange xExchange){
return BindingBuilder.bind(queueB).to(xExchange).with("XB");
}
@Bean
public Binding queueDBindingY(Queue queueD,
DirectExchange yExchange){
return BindingBuilder.bind(queueD).to(yExchange).with("YD");
}
}
2.8.2 改进1
这样存在一个缺点,就是时间由队列设置,如果有一个新的需求时间,那么就需要再加一个队列
解决此问题,可以再加一个队列,不设置队列的TTL时间,通过消息本身来设置
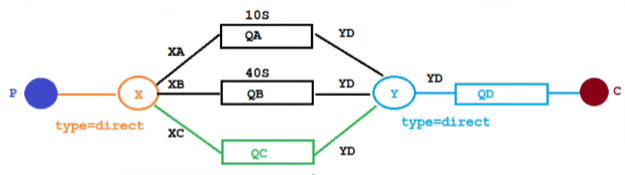
//配置类
//队列QC
@Bean
public Queue queueC(){
return QueueBuilder
.durable(QUEUE_C)
.deadLetterExchange(Y_DEAD_LETTER_EXCHANGE)
.deadLetterRoutingKey("YD")
.build();
}
@Bean
public Binding queueCBindingX(@Qualifier("queueC") Queue queueC,
@Qualifier("xExchange") DirectExchange xExchange){
return BindingBuilder.bind(queueC).to(xExchange).with("XC");
}
//生产者设置消息过期时间
@GetMapping("/sendExpirationMsg/{message}/{ttl}")
public void sendMsg(@PathVariable("message") String message,
@PathVariable("ttl") String ttl){
log.info("当前时间:{},发送一条时长:{}毫秒的TTL信息给队列QC:{}", new Date(),ttl,message);
rabbitTemplate.convertAndSend("X", "XC", "消息来自TTL的10秒队列:" + message,
msg -> {
msg.getMessageProperties().setExpiration(ttl);
return msg;
});
}2.8.3 存在的问题

第一条20秒过期,第二条(2秒过期)紧跟着第一条发出,按理说第二条应该是2秒后收到,
结果却是20秒后
原因:
RabbitMQ只会检查第一个消息是否过期(队列会排队,先进先出),如果第一个延时很长,而第二个延时很短,那么第二个并不会优先执行
2.8.4 解决方法:
插件:

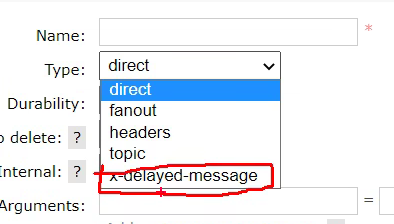

//配置类
@Configuration
public class DelayedQueueConfig {
//交换机
public static final String DELAYED_EXCHANGE_NAME = "delayed.exchange";
//队列
public static final String DELAYED_QUEUE_NAME = "delayed.queue";
//routing key
public static final String DELAYED_ROUTING_KEY = "delayed.routingKey";
//插件的交换机类型
public static final String DELAYED_EXCHANGE_TYPE = "x-delayed-message";
//交换机
//自定义交换机
@Bean
public CustomExchange delayedExchange(){
Map<String, Object> arguments = new HashMap<>();
arguments.put("x-delayed-type","direct");
return new CustomExchange(DELAYED_EXCHANGE_NAME,DELAYED_EXCHANGE_TYPE,true,false,arguments);
}
//队列
@Bean
public Queue delayedQueue(){
return QueueBuilder.nonDurable(DELAYED_QUEUE_NAME).build();
}
//绑定
@Bean
public Binding delayedQueueBingDelayedExchange(Queue delayedQueue,
CustomExchange delayedExchange){
return BindingBuilder.bind(delayedQueue).to(delayedExchange).with(DELAYED_ROUTING_KEY).noargs();
}
}
//生产者
//基于插件的延迟消息
@GetMapping("/sendDelayedMsg/{message}/{delayedTime}")
public void sendMsg(@PathVariable("message") String message,
@PathVariable("delayedTime") Integer delayedTime){
log.info("当前时间:{},发送一条时长:{}毫秒的延迟信息给延迟队列delayed.queue:{}", new Date(),delayedTime,message);
rabbitTemplate.convertAndSend(DelayedQueueConfig.DELAYED_EXCHANGE_NAME,
DelayedQueueConfig.DELAYED_ROUTING_KEY,
"消息来自插件延迟消息:" + message,
msg -> {
msg.getMessageProperties().setDelay(delayedTime);
return msg;
});
}
//消费者
@Slf4j
@Component
public class DelayedQueueConsumer {
@RabbitListener(queues = DelayedQueueConfig.DELAYED_QUEUE_NAME)
public void receiveDelayQueue(Message message){
String msg = new String(message.getBody());
log.info("当前时间:{},收到基于插件的延迟队列消息:{}", new Date(),msg);
}
}2.8.5 使用总结
一般来说,如果需要延时处理,使用插件的方式来实现,而不是死信队列的TTL来实现
因为TTL的方式可能存在错误的执行
基于插件的方式,其延迟是基于交换机(延时后发送到队列),而不再是队列
使用插件时,因为没有用到TTL,所以发消息时是setDelay(延迟时间),
而不是原来的setExpiration(过期时间)
2.9 延迟队列总结
用于延时处理,使用RabbitMQ来实现延时队列可以很好的利用RabbitMQ的特性:
消息可靠发送、消息可靠投递、死信队列保障消息至少被消费一次
以及未被正确处理的消息不会被丢弃。另外,通过RabbitMQ集群的特性,可以很好地解决单点故障问题
,不会因为单个节点挂掉导致延时队列不可用或者消息丢失
延时队列的其他选择:Java的DelayQueue,利用Redis的zset,利用Quartz或者利用Kafka的时间轮
2.10 发布确认(springboot版)
使用原因:
交换机或者队列出问题,消息会丢失,因此需要确认
2.10.1 发布确认

yml配置(必须):
spring:
rabbitmq:
# 确保生产者的消息,是否到达交换机
publisher-confirm-type: correlated这里的simple会使用同步方式,而且可能会关闭channel信道

//生产者
@GetMapping("/sendMsg/{message}")
public void sendMessage(@PathVariable("message") String message){
//这里参数是ID,为了后面ConfirmCallback的confirm方法的参数CorrelationData能取到ID
CorrelationData correlationData1 = new CorrelationData("666");
//这里交换机和routingKey的名称改成不存在的,可以模拟交换机或队列出问题
rabbitTemplate.convertAndSend(ConfirmConfig.CONFIRM_EXCHANGE_NAME
,ConfirmConfig.CONFIRM_ROUTING_KEY
,message
,correlationData1);
log.info("发送消息内容为:{}",message);
}
//回调
@Slf4j
@Component
public class MyCallBack implements RabbitTemplate.ConfirmCallback,RabbitTemplate.ReturnsCallback {
@Autowired(required = false)
private RabbitTemplate rabbitTemplate;
//该注解保证先完成注入rabbitTemplate,再初始化(该方法),否则rabbitTemplate为null
@PostConstruct
public void init(){
//注入
//为了把rabbitTemplate这个实例里面的Callback,替换成自己写的Callback,而不是用原来的
rabbitTemplate.setConfirmCallback(this);
rabbitTemplate.setReturnsCallback(this);
}
/**
*交换机确认回调方法
*生产者的消息,是否到达交换机
*/
@Override
public void confirm(CorrelationData correlationData, boolean ack, String cause) {
//前面生产者设置了CorrelationData,发送过来,这里的才有
String id = correlationData == null ? "" : correlationData.getId();
if(ack){
log.info("交换机收到ID为:{}的消息",id);
}else{
log.info("交换机没有收到ID为:{}的消息,原因是:{}",id,cause);
}
}
//交换机的消息,未到达指定队列时
//进行回退
@Override
public void returnedMessage(ReturnedMessage returned) {
log.error("消息:{},被交换机{}退回,退回的原因{},路由的key:{}",
new String(returned.getMessage().getBody()),
returned.getExchange(),
returned.getReplyText(),
returned.getRoutingKey());
}
}
2.10.2 回退消息
yml配置(必须):
spring:
rabbitmq:
# 确保交换机的消息,没有被路由到队列时,不丢弃消息
publisher-returns: true回退消息的代码在上面的returnedMessage


2.10.3 备份交换机
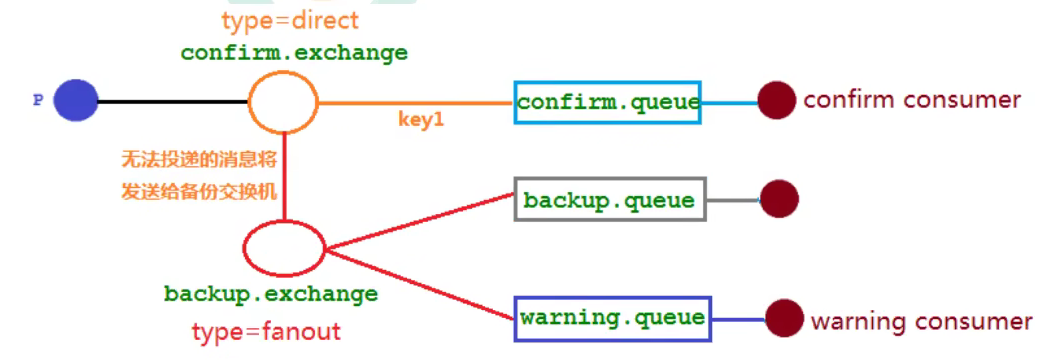
//交换机
//普通交换机要指明发送到,哪个备份交换机
@Bean
public DirectExchange confirmExchange(){
return ExchangeBuilder.directExchange(CONFIRM_EXCHANGE_NAME)
//默认为true,可不写
.durable(true)
//指定备份交换机
.alternate(BACKUP_EXCHANGE_NAME)
.build();
}注意:
1. 需要删除之前创建的交换机
1. **回退消息**(publisher-returns: true或mandatory)和**备份交换机**==同时使用==,**备份交换机优先级更高**2.11 RabbitMQ其他知识点
2.11.1 幂等性
就是消息重复消费的问题,
可能由于返回ack时网络中断,MQ没收到确认信息,重发给其他消费者或者
网络重连后再次发送给该消费者,但实际上该消费者已经消费了该消息,导致了重复消费
解决重复消费方法:
使用全局ID或者写一个唯一标识(如时间戳或者UUID或者订单消费MQ中的消息的ID或者按自己的规则生成一个全局唯一的ID)每次消费时先用该ID判断该消息是否已经消费过

2.11.2 优先级队列
概念:
部分消息优先处理
应用:
订单催付功能
实现:
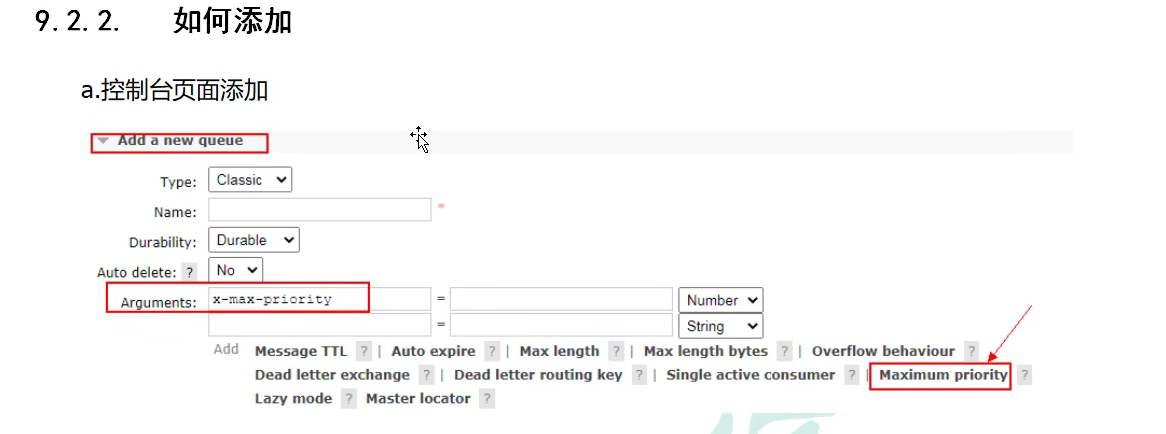

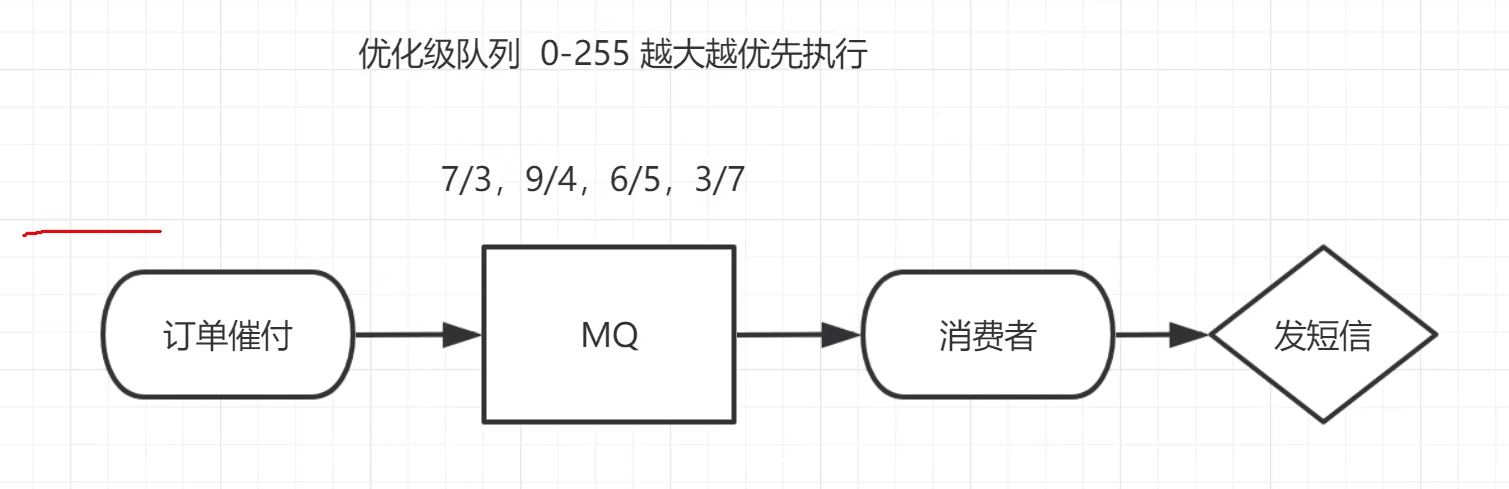
但是一般优先级设置比较小,因为这样速度快一些
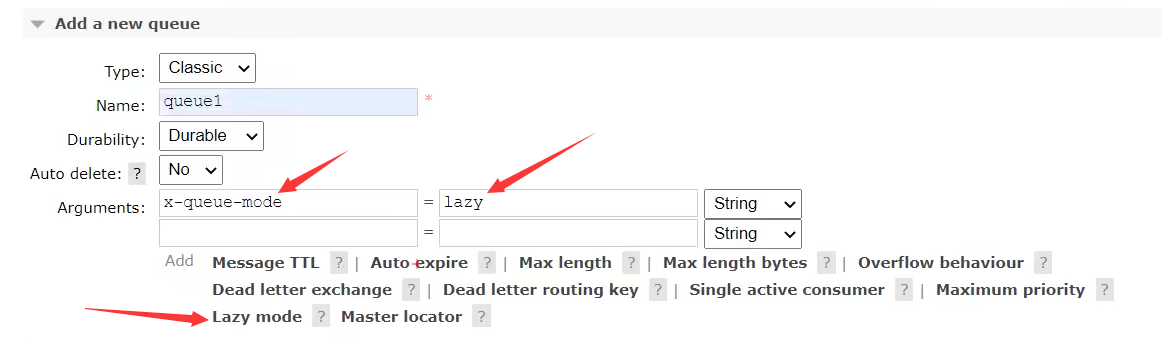
2.11.3 惰性队列
保存在磁盘中

使用场景:
消费者下线、宕机或者因为维护而关闭,导致的消息的大量堆积时采用惰性队列
如果都默认积压在内存中,会占用巨大的内存,造成浪费
而使用惰性队列,消息进入MQ时,存放在磁盘里,消费时从磁盘读取到内存,所以速度慢,一般情况不用
使用:

2.12 RabbitMQ集群
搭建集群
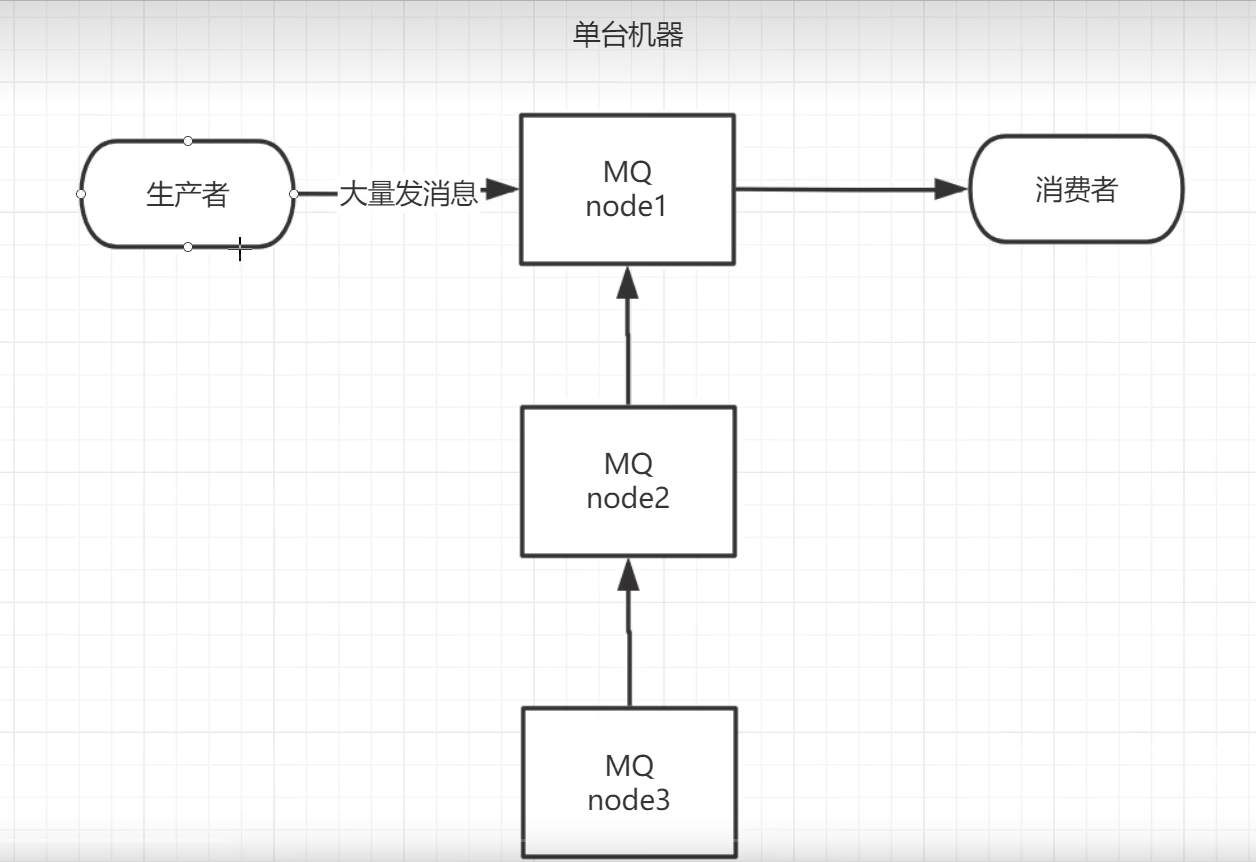
镜像队列:

默认一个队列只存在一个服务器上,所以需要备份
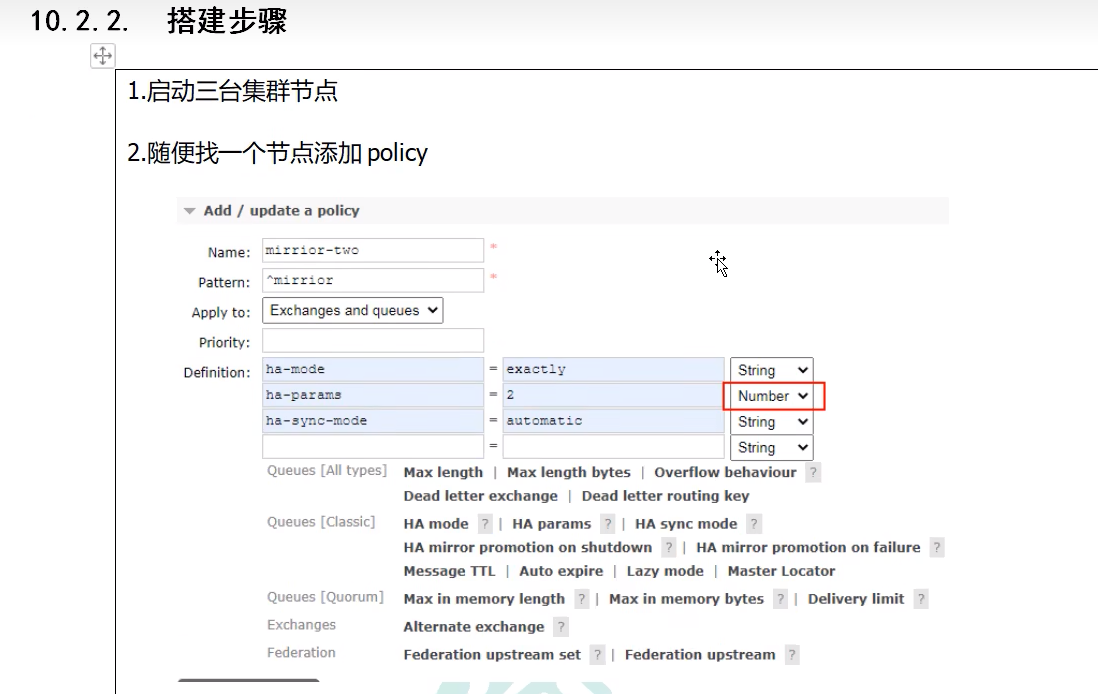
镜像2份,1、2、3台服务器
假设是1的队列,3镜像,现在是1,3都有该队列
1宕机了,会导致2里面继续镜像备份3里面的队列,现在是3、2都有该队列
因此即使集群最后只剩下一台服务器,也能保存有消息
- 使用Haproxy+Keepalive实现高可用
生产者连接的只是一个MQ,不知道有集群,代码里面写死了ip,无法改变ip
所以要使用其他的方法
比如Haproxy或者nginx
- Federation Exchange
使用原因:
服务器在不同地区,为了降低延迟,不同地区的用户,访问离自己近的服务器,使延迟低
但是当涉及到两个不同地区的服务器交互,就需要同步信息,使数据同步
镜像队列指的是集群内备份
联邦队列指的是集群之间远程数据同步
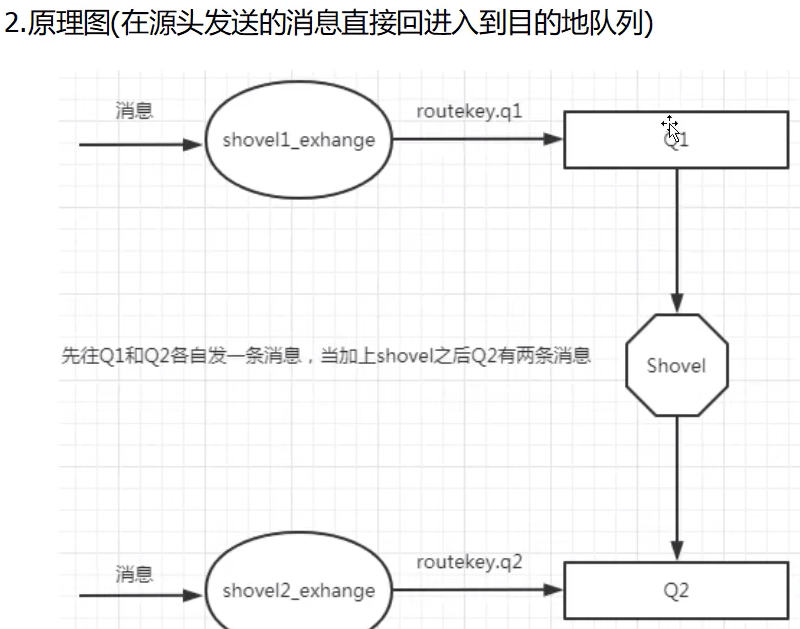
- Shovel
同步数据(源端 --> 目的端)